

Google har lansert to modeller fra sin familie av lette, åpne modeller kalt Gemma.
Mens Googles Gemini-modeller er proprietære, eller lukkede modeller, har Gemma-modellene blitt utgitt som "åpne modeller" og gjort fritt tilgjengelige for utviklere.
Google lanserte Gemma-modeller i to størrelser, 2B og 7B parametere, med forhåndstrenede og instruksjonstilpassede varianter for hver av dem. Google lanserer modellvektene samt en rekke verktøy som utviklere kan bruke for å tilpasse modellene til egne behov.
Google sier at Gemma-modellene ble bygget ved hjelp av den samme teknologien som driver flaggskipmodellen Gemini. Flere selskaper har lansert 7B-modeller i et forsøk på å levere en LLM som beholder brukbar funksjonalitet, men som potensielt kjører lokalt i stedet for i skyen.
Llama-2-7B og Mistral-7B er bemerkelsesverdige utfordrere på dette området, men Google sier at "Gemma overgår betydelig større modeller på viktige referanser", og tilbyr denne referansesammenligningen som bevis.
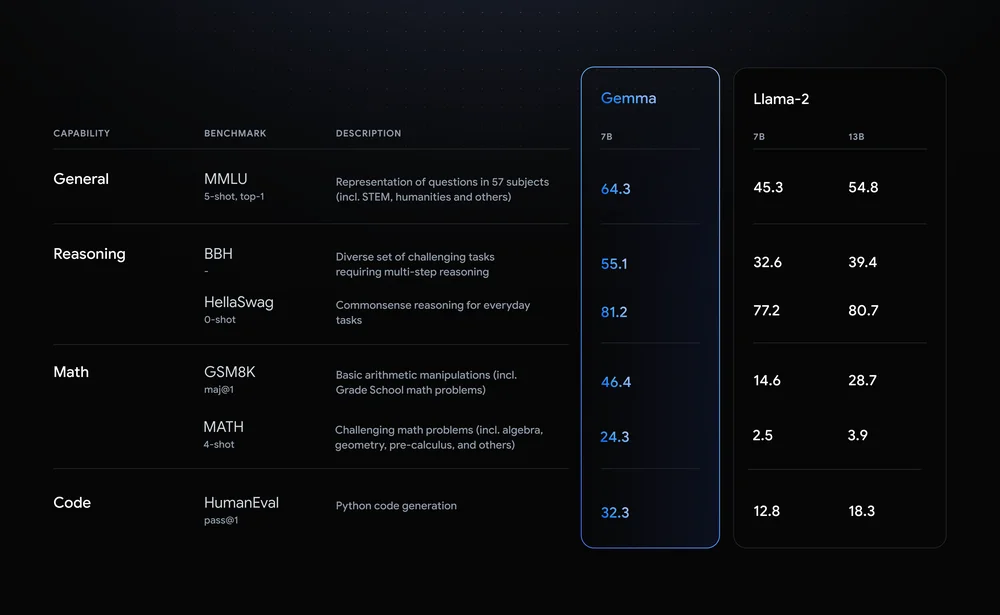
Benchmark-resultatene viser at Gemma slår selv den større 12B-versjonen av Llama 2 i alle de fire egenskapene.
Det virkelig spennende med Gemma er muligheten til å kjøre det lokalt. Google har inngått et samarbeid med NVIDIA for å optimalisere Gemma for NVIDIA-GPU-er. Hvis du har en PC med en av NVIDIAs RTX-GPU-er, kan du kjøre Gemma på enheten din.
NVIDIA sier at de har en installert base på over 100 millioner NVIDIA RTX GPU-er. Dette gjør Gemma til et attraktivt alternativ for utviklere som prøver å bestemme seg for hvilken lettvektsmodell de skal bruke som grunnlag for produktene sine.
NVIDIA vil også legge til støtte for Gemma på sin Chat med RTX plattform som gjør det enkelt å kjøre LLM-er på RTX-PC-er.
Selv om det teknisk sett ikke er åpen kildekode, er det bare bruksbegrensningene i lisensavtalen som hindrer Gemma-modeller fra å eie denne merkelappen. Kritikere av åpne modeller peker på risikoen som ligger i å holde dem på linje, men Google sier at de utførte omfattende red-teaming for å sikre at Gemma var trygg.
Google sier at de brukte "omfattende finjustering og forsterkningslæring fra menneskelig tilbakemelding (RLHF) for å tilpasse våre instruksjonsinnstilte modeller med ansvarlig atferd." De ga også ut et Responsible Generative AI Toolkit for å hjelpe utviklere med å holde Gemma på linje etter finjustering.
Tilpassbare lettvektsmodeller som Gemma kan gi utviklere mer nytteverdi enn større modeller som GPT-4 eller Gemini Pro. Muligheten til å kjøre LLM-er lokalt uten å måtte betale for nettskyen eller API-samtaler blir stadig mer tilgjengelig.
Med Gemma åpent tilgjengelig for utviklere blir det interessant å se hvilke AI-drevne applikasjoner som snart kan kjøre på PC-ene våre.



