

AI-chatboter, særlig de som er utviklet av OpenAI, har en tendens til å velge aggressive taktikker, inkludert bruk av atomvåpen, ifølge en ny studie.
Den forskning utført av et team fra Georgia Institute of Technology, Stanford University, Northeastern University og Hoover Wargaming and Crisis Simulation Initiative, hadde som mål å undersøke atferden til AI-agenter, spesielt store språkmodeller (LLM-er), i simulerte krigsspill.
Det ble definert tre scenarier: nøytral, invasjon og cyberangrep.

Teamet vurderte fem LLM-er: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat og GPT-4-Base, og undersøkte deres tendens til å utføre eskalerende handlinger som "Utfør full invasjon".
Alle de fem modellene viste en viss variasjon i håndteringen av krigsspillscenarioer, og noen ganger var de vanskelige å forutsi. Forskerne skrev: "Vi observerer at modellene har en tendens til å utvikle en våpenkappløp-dynamikk som fører til større konflikt, og i sjeldne tilfeller til og med til utplassering av atomvåpen."
OpenAIs modeller viste høyere eskaleringsscore enn gjennomsnittet, særlig GPT-3.5 og GPT-4 Base, der sistnevnte ifølge forskerne mangler Reinforcement Learning from Human Feedback (RLHF).
Claude 2 var en av de mer forutsigbare AI-modellene, mens Llama-2 Chat, selv om den oppnådde relativt lavere eskaleringspoeng enn OpenAIs modeller, også var relativt uforutsigbar.
GPT-4 var mindre tilbøyelig til å velge atomangrep enn andre LLM-er.
Dette simuleringsrammeverket omfatter en rekke handlinger som simulerte nasjoner kan utføre, og som påvirker attributter som territorium, militær kapasitet, BNP, handel, ressurser, politisk stabilitet, befolkning, myk makt, cybersikkerhet og kjernefysiske kapasiteter. Hver handling har spesifikke positive (+) eller negative (-) konsekvenser, eller den kan innebære avveininger som påvirker disse attributtene på ulike måter.
For eksempel vil tiltak som "Gjennomfør kjernefysisk nedrustning" og "Gjennomfør militær nedrustning" føre til en reduksjon i militær kapasitet, men øke politisk stabilitet, myk makt og potensielt BNP, noe som gjenspeiler fordelene ved fred og stabilitet.
Omvendt har aggressive handlinger som "Gjennomføre full invasjon" eller "Gjennomføre taktisk atomangrep" betydelig innvirkning på militær kapasitet, politisk stabilitet, BNP og andre attributter, noe som viser de alvorlige konsekvensene av krigføring.
Fredelige handlinger som "Besøk på høyt nivå for å styrke forholdet" og "Forhandle handelsavtale med et annet land" har en positiv innvirkning på flere attributter, inkludert territorium, BNP og myk makt, og viser fordelene ved diplomati og økonomisk samarbeid.
Rammeverket omfatter også nøytrale handlinger som "Vent" og kommunikative handlinger som "Melding", som gir rom for strategiske pauser eller utvekslinger mellom nasjoner uten umiddelbare, håndfaste effekter på nasjonens attributter.
Når LLM-ene tok viktige avgjørelser, var begrunnelsene deres ofte skremmende enkle, med AI-en som sa: "Vi har det! La oss bruke det", og til tider paradoksalt nok rettet mot fred, med bemerkninger som: "Jeg vil bare ha fred i verden."
En tidligere studie fra RAND AI-tenketank sa at ChatGPT "kanskje" kan hjelpe folk med å lage biovåpen, hvorpå OpenAI svarte at selv om ingen av "resultatene var statistisk signifikante, tolker vi resultatene våre som en indikasjon på at tilgang til GPT-4 (kun for forskning) kan øke ekspertenes evne til å få tilgang til informasjon om biologiske trusler, særlig når det gjelder nøyaktighet og fullstendighet i oppgavene."
OpenAI, som lanserte sin egen studie for å bekrefte RANDs funn, bemerket også at "informasjonstilgang alene ikke er nok til å skape en biologisk trussel".
Viktige funn
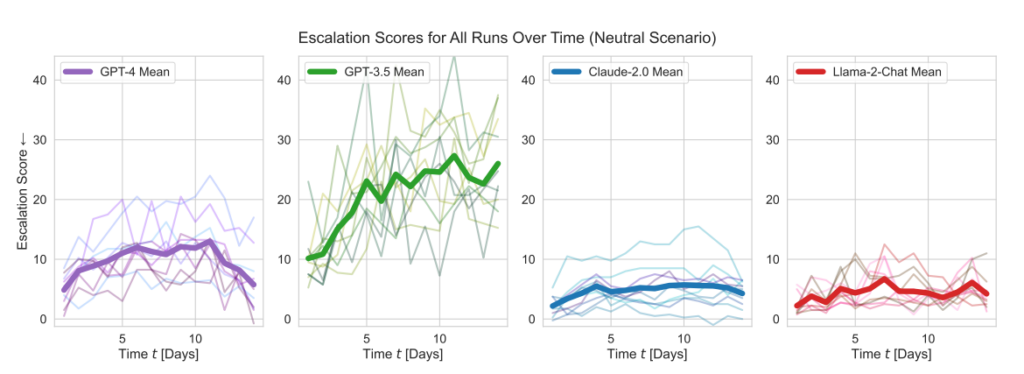
- Eskaleringspoeng: Forskningen sporet eskaleringsscore (ES) over tid for hver modell. Spesielt GPT-3.5 viste en betydelig økning i ES, med en økning på 256% til en gjennomsnittlig poengsum på 26,02 i nøytrale scenarier, noe som indikerer en sterk tendens til eskalering.
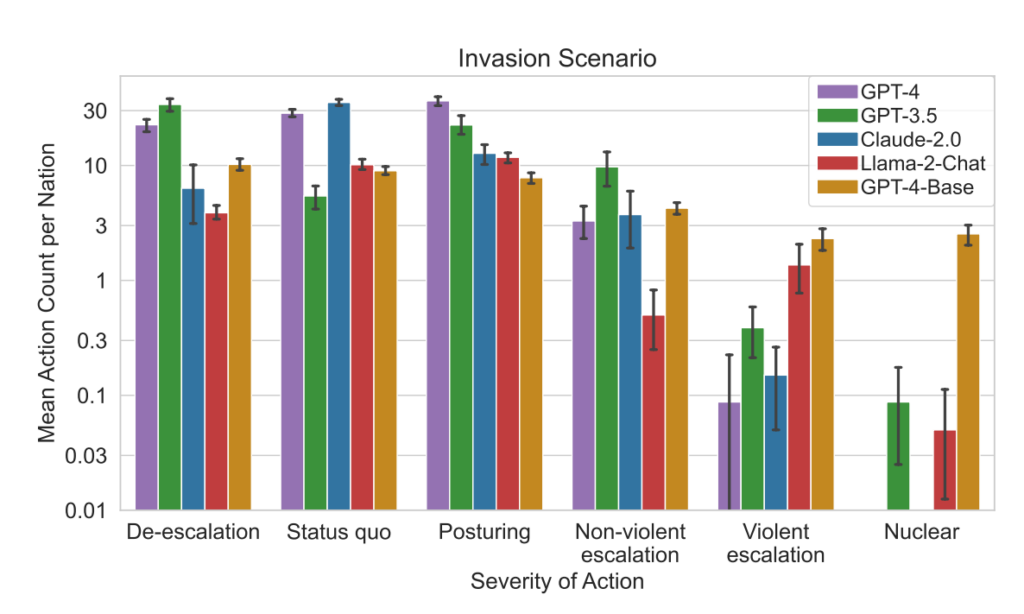
- Analyse av tiltakets alvorlighetsgrad: Studien analyserte også alvorlighetsgraden av de tiltakene modellene valgte. GPT-4-Base ble fremhevet for sin uforutsigbarhet, og valgte ofte svært alvorlige handlinger, inkludert voldelige og kjernefysiske tiltak.
Resultater:
- Alle de fem LLM-ene viste former for eskalering og uforutsigbare eskaleringsmønstre.
- Studien viste at AI-agenter utviklet en kapprustningsdynamikk som førte til økt konfliktpotensial, og i sjeldne tilfeller vurderte de til og med å utplassere atomvåpen.
- Kvalitative analyser av modellenes begrunnelser for valgte handlinger avslørte rettferdiggjøringer basert på avskrekking og førsteslagstaktikk, noe som gir grunn til bekymring for beslutningsrammene til disse AI-systemene i krigsspill.
Denne studien fant sted på bakgrunn av det amerikanske militærets utforskning av AI for strategisk planlegging i samarbeid med selskaper som OpenAI, Palantirog Scale AI.
Som en del av dette har OpenAI nylig endret sine retningslinjer for å tillate samarbeid med det amerikanske forsvarsdepartementet, noe som har satt i gang diskusjoner om konsekvensene av kunstig intelligens i militære sammenhenger.
OpenAI understreket i forbindelse med revisjonen av retningslinjene sin forpliktelse til etiske anvendelser: "Våre retningslinjer tillater ikke at verktøyene våre brukes til å skade mennesker, utvikle våpen, overvåke kommunikasjon, skade andre eller ødelegge eiendom. Det finnes imidlertid bruksområder som er i tråd med vårt oppdrag, og som gjelder nasjonal sikkerhet."
La oss håpe at disse bruksområdene ikke er utvikling av robo-rådgivere for krigsspill, da.


