

Forskere fra UC San Diego og New York University har utviklet V*, en LLM-styrt søkealgoritme som er mye bedre enn GPT-4V når det gjelder kontekstuell forståelse og presis målretting mot spesifikke visuelle elementer i bilder.
Multimodale store språkmodeller (MLLM) som OpenAIs GPT-4V imponerte oss i fjor med sin evne til å svare på spørsmål om bilder. Selv om GPT-4V er imponerende, sliter den noen ganger når bildene er svært komplekse, og den overser ofte små detaljer.
V*-algoritmen bruker en Visual Question Answering (VQA) LLM for å finne ut hvilket område i bildet den skal fokusere på for å svare på en visuell forespørsel. Forskerne kaller denne kombinasjonen Show, sEArch og telL (SEAL).
Hvis noen gir deg et høyoppløst bilde og stiller deg et spørsmål om det, vil logikken din veilede deg til å zoome inn på et område der det er mest sannsynlig at du finner det aktuelle objektet. SEAL bruker V* til å analysere bilder på en lignende måte.
En visuell søkemodell kan ganske enkelt dele et bilde inn i blokker, zoome inn i hver blokk og deretter behandle det for å finne det aktuelle objektet, men det er svært ineffektivt rent beregningsmessig.
Når V* blir bedt om å sende inn en tekstlig forespørsel om et bilde, prøver den først å lokalisere bildemålet direkte. Hvis den ikke klarer det, ber den MLLM om å bruke sunn fornuft for å identifisere hvilket område av bildet det er mest sannsynlig at målet befinner seg i.
Deretter fokuserer den søket på dette området, i stedet for å forsøke å zoome inn på hele bildet.

Når GPT-4V blir bedt om å svare på spørsmål om et bilde som krever omfattende visuell behandling av høyoppløselige bilder, sliter den. SEAL med V* presterer mye bedre.

På spørsmålet "Hva slags drikke kan vi kjøpe fra den automaten?" svarte SEAL "Coca-Cola". svarte SEAL "Coca-Cola", mens GPT-4V feilaktig gjettet "Pepsi".
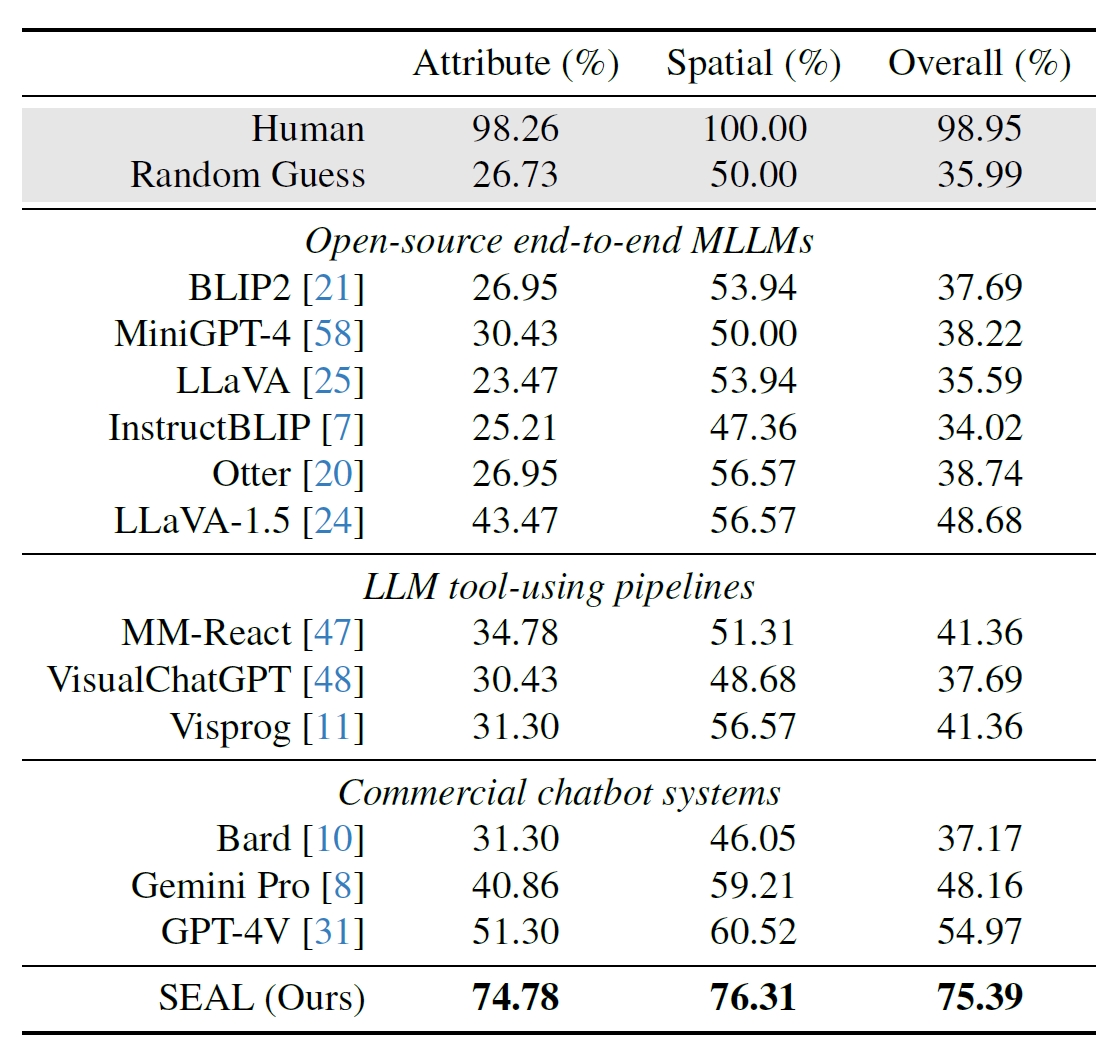
Forskerne brukte 191 høyoppløselige bilder fra Metas datasett Segment Anything (SAM) og opprettet en referanseindeks for å se hvordan SEALs ytelse var sammenlignet med andre modeller. V*Bench-referansen tester to oppgaver: attributtgjenkjenning og romlig relasjonsresonnering.
Figurene nedenfor viser menneskelig ytelse sammenlignet med modeller med åpen kildekode, kommersielle modeller som GPT-4V og SEAL. Økningen V* gir i SEALs ytelse er spesielt imponerende fordi den underliggende MLLM-en den bruker, er LLaVa-7b, som er mye mindre enn GPT-4V.
Denne intuitive tilnærmingen til bildeanalyse ser ut til å fungere veldig bra, med en rekke imponerende eksempler på sammendrag av artikkelen på GitHub.
Det blir interessant å se om andre MLLM-er, som de fra OpenAI eller Google, tar i bruk en lignende tilnærming.
På spørsmål om hvilken drikke som ble solgt fra automaten på bildet over, svarte Googles Bard: "Det er ingen automat i forgrunnen." Kanskje Gemini Ultra vil gjøre en bedre jobb.
Foreløpig ser det ut til at SEAL og den nye V*-algoritmen ligger et godt stykke foran noen av de største multimodale modellene når det gjelder visuell avhøring.



