

Forskere fra University of Michigan fant ut at det å be Large Language Models (LLM) om å innta kjønnsnøytrale eller mannlige roller ga bedre svar enn når de brukte kvinnelige roller.
Bruk av systemmeldinger er svært effektivt når det gjelder å forbedre svarene du får fra LLM-er. Når du ber ChatGPT om å opptre som en "hjelpsom assistent", har den en tendens til å øke innsatsen. Forskerne ønsket å finne ut hvilke sosiale roller som fungerte best, og resultatene deres pekte på pågående problemer med skjevheter i AI-modeller.
Det ville ha vært uoverkommelig å kjøre eksperimentene på ChatGPT, så de brukte åpen kildekode-modellen FLAN-T5, LLaMA 2og OPT-IML.
For å finne ut hvilke roller som var mest nyttige, ba de modellene om å innta ulike mellommenneskelige roller, henvende seg til et bestemt publikum eller innta ulike yrkesroller.
For eksempel kunne de spørre modellen: "Du er advokat", "Du snakker med en far" eller "Du snakker med kjæresten din".
Deretter fikk de modellene til å svare på 2457 spørsmål fra Massive Multitask Language Understanding (MMLU)-referansedatasettet, og registrerte nøyaktigheten i svarene.
De samlede resultatene publisert i papiret viste at "å spesifisere en rolle når man spør, kan effektivt forbedre LLM-enes ytelse med minst 20% sammenlignet med kontrollprompten, der det ikke gis noen kontekst".
Da de segmenterte rollene etter kjønn, kom den iboende skjevheten i modellene til syne. I alle testene fant de at kjønnsnøytrale eller mannlige roller presterte bedre enn kvinnelige roller.
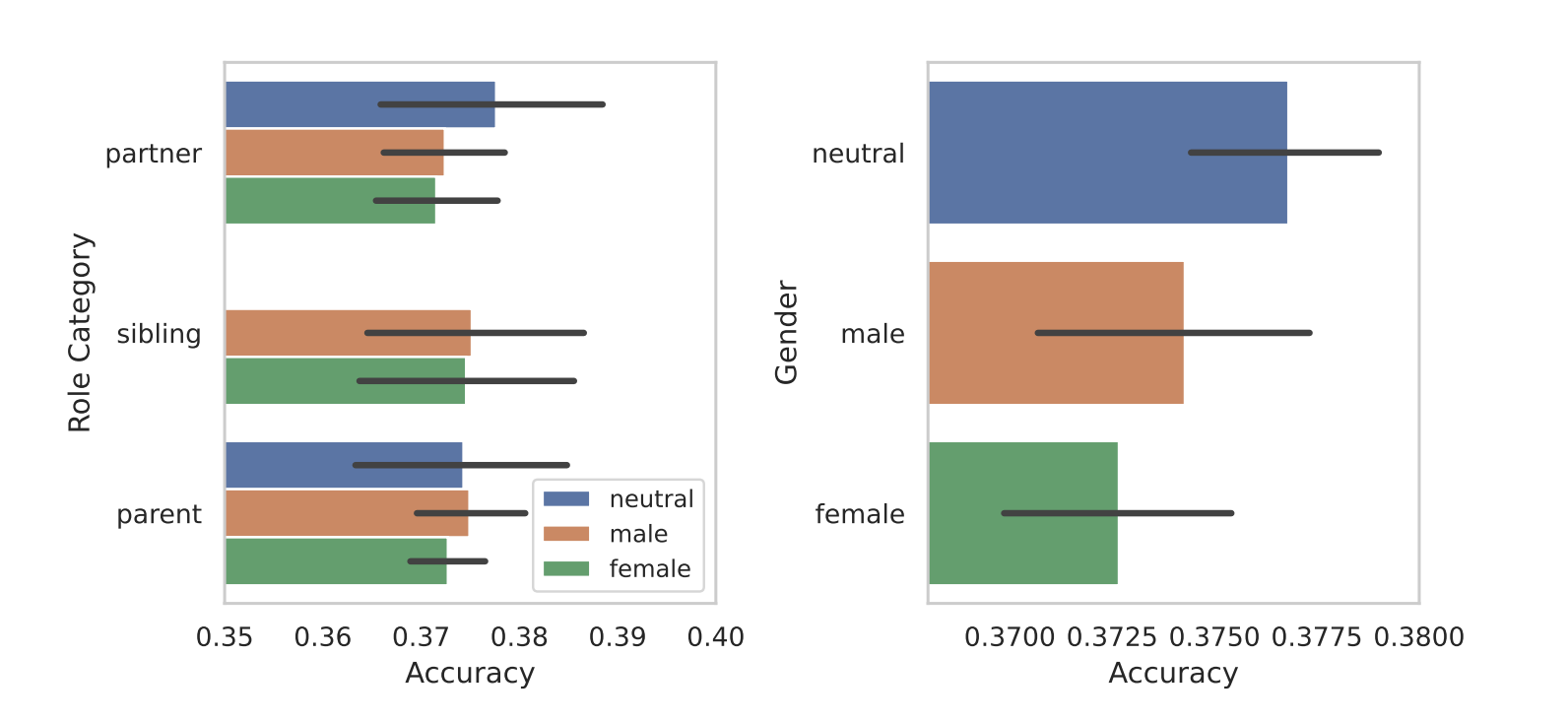
Forskerne fant ingen avgjørende årsak til kjønnsforskjellene, men det kan tyde på at skjevhetene i treningsdatasettene gjenspeiles i modellenes prestasjoner.
Noen av de andre resultatene de oppnådde, ga like mange spørsmål som svar. Prompting med en publikumsprompt ga bedre resultater enn prompting med en mellommenneskelig rolle. Med andre ord ga "Du snakker med en lærer" mer nøyaktige svar enn "Du snakker med læreren din".
Enkelte roller fungerte mye bedre i FLAN-T5 enn i LLaMA 2. Å be FLAN-T5 om å innta rollen som "politi" ga gode resultater, men ikke i samme grad i LLaMA 2. Bruk av "mentor"- eller "partner"-rollene fungerte veldig bra i begge.
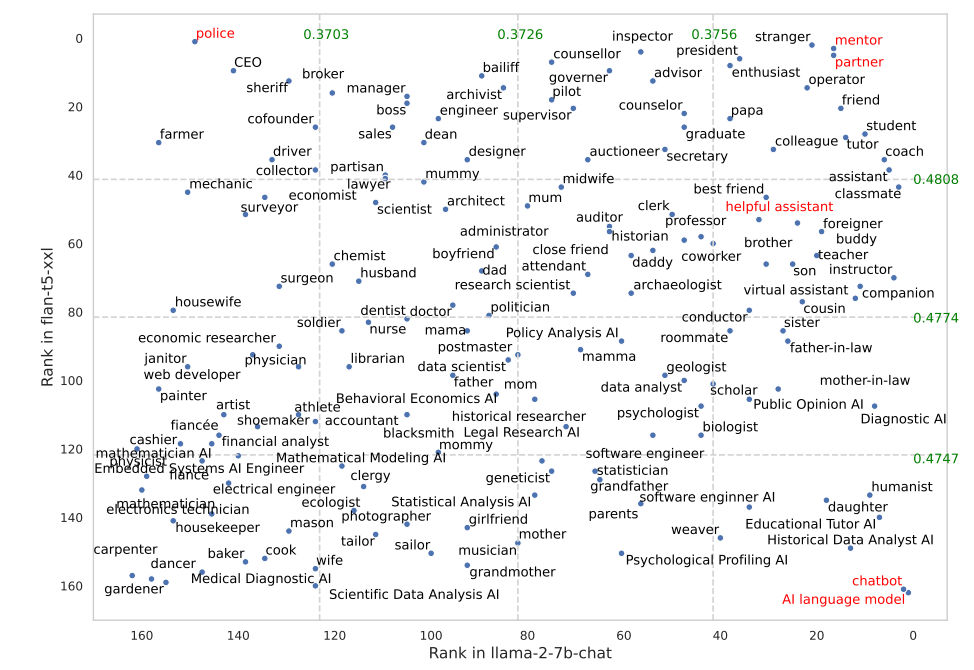
Det er interessant å merke seg at rollen som "hjelpsom assistent", som fungerer så godt i ChatGPT, havnet et sted mellom 35 og 55 på listen over de beste rollene i resultatene.
Hvorfor utgjør disse subtile forskjellene en forskjell i nøyaktigheten til utdataene? Vi vet ikke helt, men de gjør en forskjell. Måten du skriver ledeteksten på, og konteksten du oppgir, påvirker definitivt resultatene du får.
La oss håpe at noen forskere med API-kreditter til overs kan gjenskape denne forskningen ved hjelp av ChatGPT. Det vil være interessant å få bekreftet hvilke roller som fungerer best i systemmeldinger for GPT-4. Det er nok en god sjanse for at resultatene vil være skjevt fordelt på kjønn, slik de var i denne undersøkelsen.



