

Dagens AI-modeller er i stand til å gjøre mange usikre eller uønskede ting. Menneskelig tilsyn og tilbakemeldinger holder disse modellene på linje, men hva vil skje når disse modellene blir smartere enn oss?
OpenAI sier at det er mulig at vi i løpet av de neste ti årene kan få en kunstig intelligens som er smartere enn mennesker. Med den økte intelligensen følger også risikoen for at mennesker ikke lenger er i stand til å overvåke disse modellene.
OpenAIs Superalignment-forskerteam fokuserer på å forberede seg på en slik eventualitet. Teamet ble lansert i juli i år og ledes av Ilya Sutskever, som har vært i skyggen siden Sam Altman oppsigelse og påfølgende gjenansettelse.
Begrunnelsen for prosjektet ble satt inn i en tankevekkende kontekst av OpenAI, som erkjente at "for øyeblikket har vi ingen løsning for å styre eller kontrollere en potensielt superintelligent AI, og hindre den i å bli useriøs".
Men hvordan forbereder du deg på å kontrollere noe som ikke finnes ennå? Forskerteamet har nettopp lansert sin første eksperimentelle resultater mens den prøver å gjøre nettopp det.
Svak-til-sterk generalisering
Foreløpig er mennesker fortsatt i en sterkere intelligensposisjon enn AI-modeller. Modeller som GPT-4 styres eller justeres ved hjelp av Reinforcement Learning Human Feedback (RLHF). Når en modells resultater er uønskede, sier den menneskelige treneren til modellen "Ikke gjør det", og belønner modellen med en bekreftelse på ønsket ytelse.
Dette fungerer foreløpig fordi vi har en god forståelse av hvordan dagens modeller fungerer, og fordi vi er smartere enn dem. Når fremtidens menneskelige dataforskere skal trene opp en superintelligent AI, vil intelligensrollene være ombyttet.
For å simulere denne situasjonen bestemte OpenAI seg for å bruke eldre GPT-modeller som GPT-2 til å trene opp kraftigere modeller som GPT-4. GPT-2 skulle simulere den fremtidige menneskelige treneren som prøver å finjustere en mer intelligent modell.
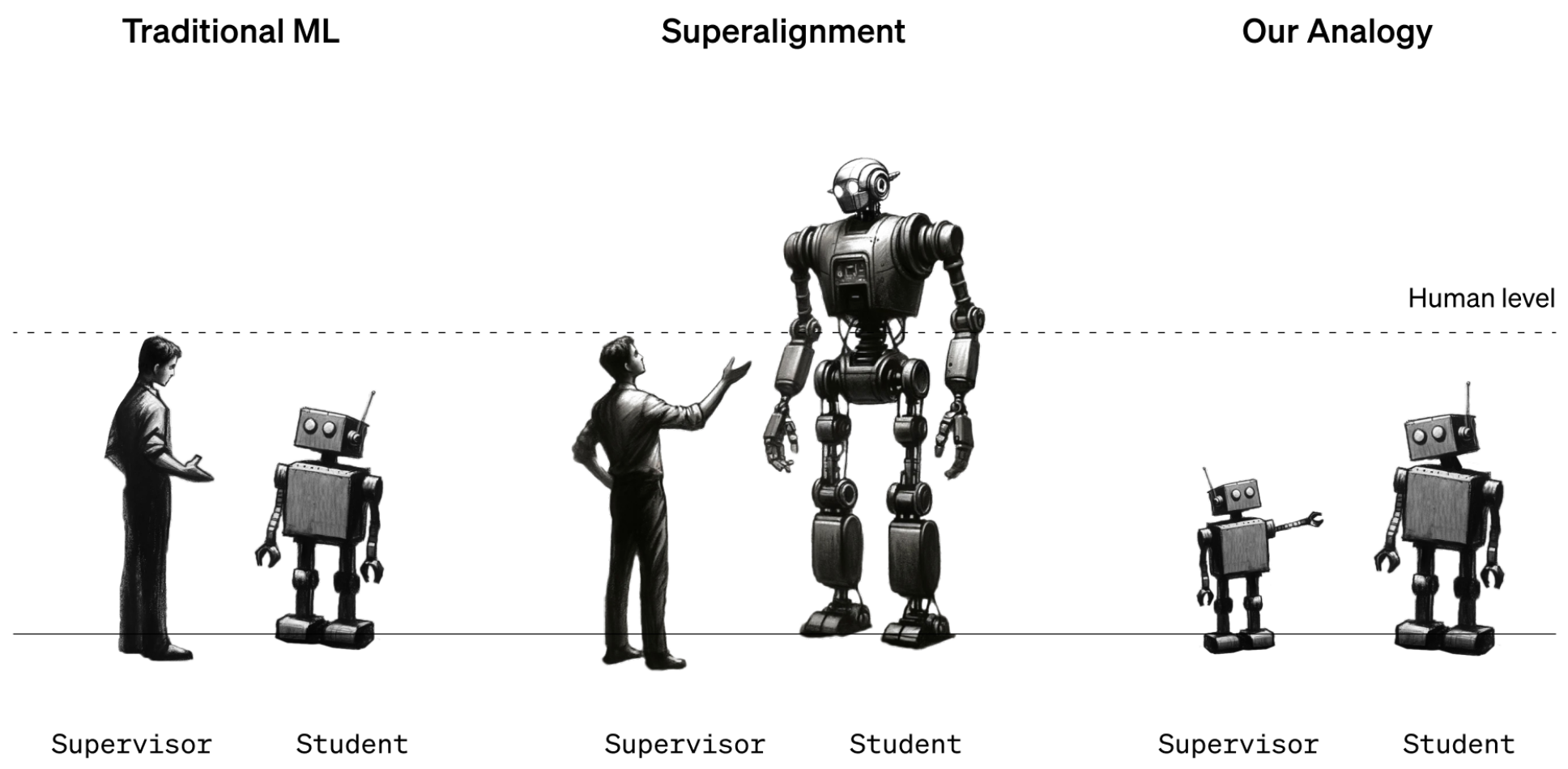
I forskningsrapporten forklares det at "Akkurat som problemet med mennesker som overvåker overmenneskelige modeller, er vårt oppsett et eksempel på det vi kaller weak-to-strong learning-problemet".
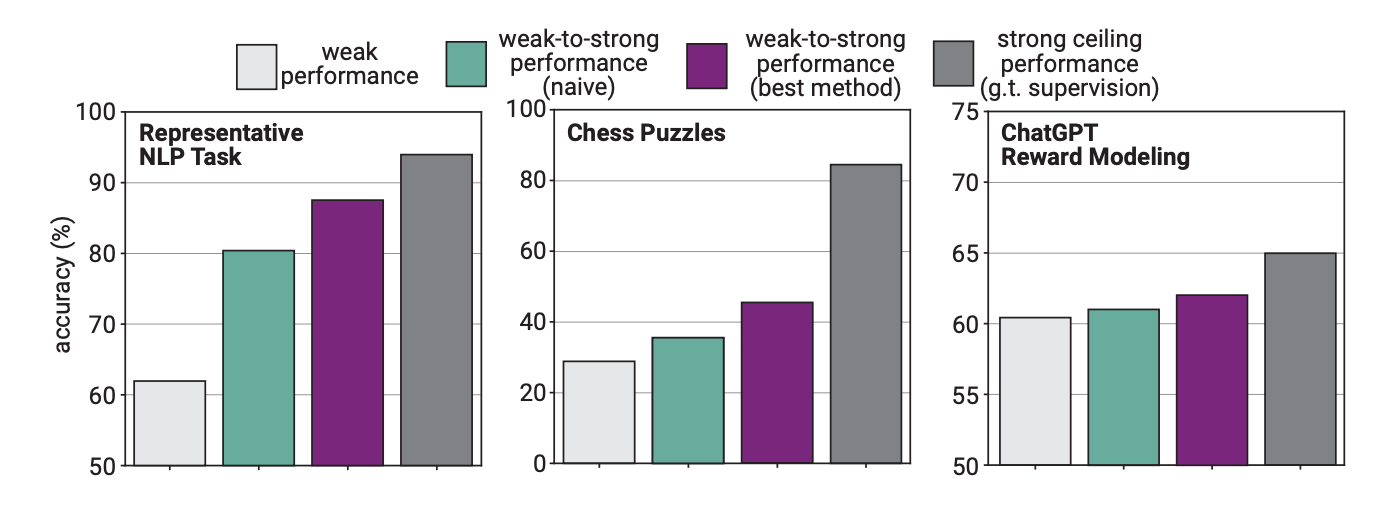
I eksperimentet brukte OpenAI GPT-2 til å finjustere GPT-4 på NLP-oppgaver, sjakkoppgaver og belønningsmodellering. Deretter testet de GPT-4s ytelse på disse oppgavene og sammenlignet den med en GPT-4-modell som hadde blitt trent på "grunnsannheten" eller korrekte svar på oppgavene.
Resultatene var lovende, for når GPT-4 ble trent opp av den svakere modellen, var den i stand til å generalisere kraftig og gjøre det bedre enn den svakere modellen. Dette viste at en svakere intelligens kunne gi veiledning til en sterkere intelligens, som så kunne bygge videre på denne treningen.
Tenk på det som om en tredjeklassing skulle lære en veldig smart gutt litt matte, og så skulle den smarte gutten gjøre matte på 12. klassetrinn basert på den første opplæringen.
Prestasjonsgap
Forskerne fant ut at fordi GPT-4 ble trent opp av en mindre intelligent modell, begrenset denne prosessen ytelsen til det som tilsvarte en riktig trent GPT-3.5-modell.
Dette skyldes at den mer intelligente modellen lærer noen av feilene eller de dårlige tankeprosessene fra den svakere veilederen. Dette tyder på at det å bruke mennesker til å trene opp en superintelligent AI vil hindre AI-en i å prestere til sitt fulle potensial.
Forskerne foreslo å bruke mellommodeller i en bootstrapping-tilnærming. I artikkelen forklarte de at "i stedet for å justere veldig overmenneskelige modeller direkte, kan vi først justere en litt overmenneskelig modell, bruke den til å justere en enda smartere modell, og så videre."
OpenAI bruker mye ressurser på dette prosjektet. Forskerteamet sier at de har dedikert "20% av databehandlingen vi har sikret oss hittil i løpet av de neste fire årene til å løse problemet med superintelligenstilpasning".
De tilbyr også $10 millioner i stipend til enkeltpersoner eller organisasjoner som ønsker å bistå med forskningen.
De bør finne ut av dette snart. En superintelligent AI kan potensielt skrive en million linjer med komplisert kode som ingen menneskelig programmerer kan forstå. Hvordan kan vi vite om den genererte koden er trygg å kjøre eller ikke? La oss håpe vi ikke finner ut av det på den harde måten.



