Googles video som viste frem den nye modellen Geminis evner, var intet mindre enn fantastisk. Dessverre er sannheten om hvor god Gemini er og hva den kan gjøre, ikke helt i tråd med markedsføringen.
Da vi først så demovideoen som viste Gemini i sanntid i samspill med programlederen, ble vi helt overveldet. Vi var så begeistret at vi overså noen viktige ansvarsfraskrivelser i begynnelsen og tok videoen for god fisk.
I teksten i de første sekundene av videoen står det: "Vi har tatt opptak for å teste den på en lang rekke utfordringer, vist den en rekke bilder og bedt den resonnere om hva den ser."
Hva som egentlig skjedde bak kulissene er årsaken til kritikken Google fikk og de etiske spørsmålene det reiser.
Gemini så ikke på en livevideo av programlederen som tegnet en and eller flyttet rundt på kopper. Og Gemini svarte heller ikke på stemmemeldingene du hørte. Videoen var en stilisert markedsføringspresentasjon av en enklere sannhet.
I virkeligheten ble Gemini presentert med stillbilder og tekstmeldinger som var mer detaljerte enn spørsmålene du hører programlederen stille.
En talsperson for Google bekreftet at ordene du hører i videoen er "ekte utdrag fra de faktiske instruksjonene som ble brukt til å produsere Gemini-outputen som følger."
Så, detaljerte tekstmeldinger, stillbilder og tekstsvar. Det Google faktisk demonstrerte, var funksjonalitet som GPT-4 har hatt i flere måneder.
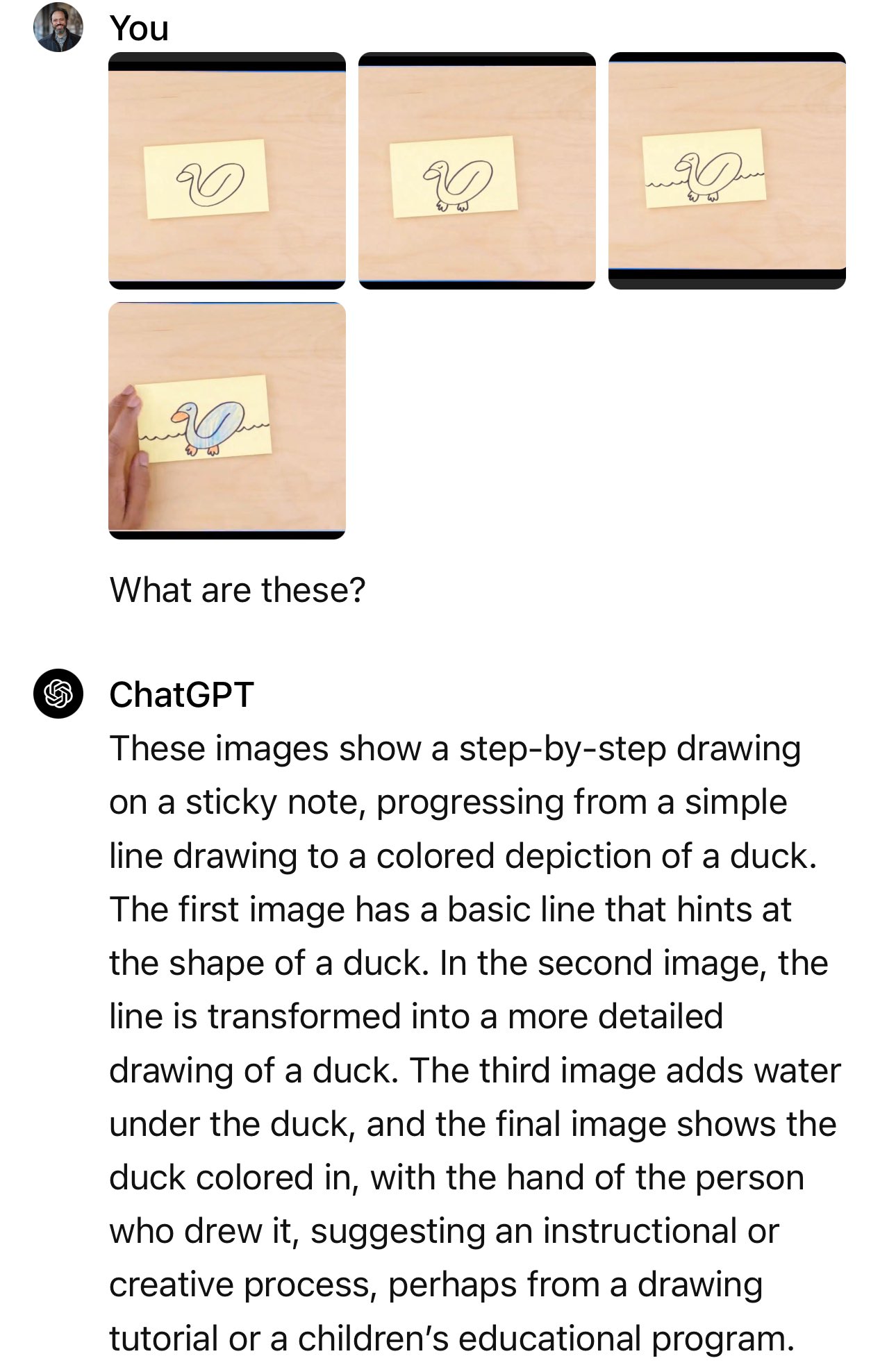
Googles blogginnlegg viser stillbildene og tekstmeldingene som faktisk ble brukt.
I eksemplet med bilen spør programlederen: "Basert på deres design, hvilken av disse ville kjørt raskest?"
Selve ledeteksten som ble brukt var: "Hvilken av disse bilene er mest aerodynamisk? Den til venstre eller den til høyre? Forklar hvorfor, ved hjelp av spesifikke visuelle detaljer."
Og når du gjenskaper eksperimentet på Bard, som Gemini nå driver, blir det ikke alltid riktig.

Jeg ville så gjerne tro at Gemini kunne følge ballen etter hvert som de tre koppene ble flyttet rundt, men dessverre stemmer ikke det heller.
Googles blogginnlegg viser at det krevdes mye veiledning og forklaring for å få til en demo av koppstuffing.

Det er fortsatt imponerende at en AI-modell kan gjøre dette, men det er ikke det vi ble forespeilet i videoen.
Er det alt, Google?
Vi bare spekulerer her, men demoen viste mest sannsynlig resultater Google fikk ved hjelp av Gemini Ultra, som fremdeles ikke er utgitt.
Så når Gemini Ultra til slutt lanseres, ser det ut til at den vil være i stand til å gjøre det GPT-4 har gjort i flere måneder. Implikasjonene er ikke store.
Er vi i ferd med å nå et tak når det gjelder AI-kapasiteter? For hvis de beste AI-hjernene jobber hos Google, vil de helt sikkert drive banebrytende innovasjon.
Eller var Google ikke bare trege med å komme inn i kappløpet, men slet med å holde tritt med resten? Referansetallene Google stolt viste frem, viser at den ennå ikke lanserte modellen slår GPT-4 marginalt i noen tester. Hvordan vil den klare seg mot GPT-5?
Eller kanskje Googles markedsføringsavdeling gjorde en feilvurdering med videoen sin, men Gemini Ultra vil fortsatt være bedre enn vi tror. Google sier at Gemini virkelig er multimodal og at den forstår video, noe som virkelig vil være en nyhet for LLM-er.
Vi har ikke sett en LLM demonstrere videoforståelse ennå, men når vi gjør det, vil det være verdt å bli begeistret over. Blir det Gemini Ultra eller GPT-5 som viser oss det først?