

Store språkmodeller (Large Language Models, LLM) blir ofte villedet av skjevheter eller irrelevant kontekst i en ledetekst. Forskere ved Meta har funnet en tilsynelatende enkel måte å løse dette på.
Etter hvert som kontekstvinduene blir større, kan instruksjonene vi legger inn i en LLM, bli lengre og mer detaljerte. LLM-ene har blitt flinkere til å fange opp nyanser eller mindre detaljer i instruksjonene våre, men noen ganger kan dette forvirre dem.
Tidlig maskinlæring brukte en "hard attention"-tilnærming som skilte ut den mest relevante delen av en input og kun reagerte på den. Dette fungerer fint når du prøver å sette bildetekst til et bilde, men dårlig når du skal oversette en setning eller svare på et spørsmål med flere lag.
De fleste LLM-er bruker nå en "soft attention"-tilnærming som tokeniserer hele ledeteksten og tildeler vekting til hver enkelt.
Meta foreslår en tilnærming som kalles System 2 Oppmerksomhet (S2A) for å få det beste fra begge verdener. S2A bruker den naturlige språkbehandlingsevnen til en LLM til å ta imot ledeteksten din og fjerne skjevheter og irrelevant informasjon før du begynner å jobbe med et svar.
Her er et eksempel.

S2A fjerner informasjonen om Max, siden den er irrelevant for spørsmålet. S2A regenererer en optimalisert ledetekst før den begynner å jobbe med den. LLM-er er notorisk dårlige til å matte så det er en stor hjelp å gjøre ledeteksten mindre forvirrende.
LLM-er er folkelige og vil gjerne være enige med deg, selv når du tar feil. S2A fjerner alle skjevheter i en ledetekst og behandler deretter bare de relevante delene av ledeteksten. Dette reduserer det AI-forskere kaller "sycophancy", eller en AI-modells tilbøyelighet til å smiske.

S2A er egentlig bare en systemmelding som ber LLM-enheten om å finpusse den opprinnelige meldingen litt før den begynner å jobbe med den. Resultatene forskerne oppnådde med matte-, fakta- og langspørsmål var imponerende.
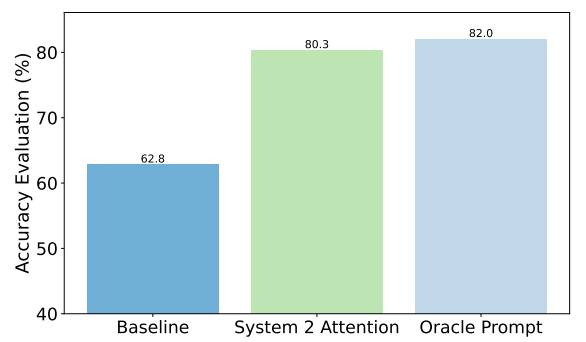
Her er et eksempel på forbedringene S2A oppnådde på faktaspørsmål. Utgangspunktet var svar på spørsmål som inneholdt skjevheter, mens Oracle-spørsmålet var et menneskeskapt idealspørsmål.
S2A kommer svært nær resultatene fra Oracle-prompten og leverer nesten 50% bedre nøyaktighet enn baseline-prompten.
Så hva er haken? Forbehandling av den opprinnelige ledeteksten før du svarer på den, gjør at prosessen krever flere beregninger. Hvis ledeteksten er lang og inneholder mye relevant informasjon, kan det medføre betydelige kostnader å generere ledeteksten på nytt.
Det er lite sannsynlig at brukerne blir flinkere til å skrive velformulerte spørsmål, så S2A kan være en god måte å omgå dette på.
Kommer Meta til å bygge S2A inn i sin Lama modell? Vi vet ikke, men du kan selv benytte deg av S2A-metoden.
Hvis du er nøye med å utelate meninger eller ledende forslag fra spørsmålene dine, er det mer sannsynlig at du får nøyaktige svar fra disse modellene.



