

Nvidia kunngjorde ny programvare med åpen kildekode som ifølge selskapet vil gi bedre ytelse på H100 GPU-ene.
Mye av den nåværende etterspørselen etter Nvidias GPU-er er å bygge datakraft for å trene opp nye modeller. Men når modellene er trent opp, må de brukes. Inferens i AI refererer til evnen en LLM som ChatGPT har til å trekke konklusjoner eller komme med spådommer ut fra data den har blitt trent på, og generere resultater.
Når du prøver å bruke ChatGPT og får opp en melding om at serverne er overbelastet, er det fordi maskinvaren sliter med å holde tritt med etterspørselen etter slutninger.
Nvidia sier at den nye programvaren, TensorRT-LLM, kan få den eksisterende maskinvaren til å kjøre mye raskere og mer energieffektivt.
Programvaren inneholder optimaliserte versjoner av de mest populære modellene, inkludert Meta Llama 2, OpenAI GPT-2 og GPT-3, Falcon, Mosaic MPT og BLOOM.
Den bruker noen smarte teknikker, som mer effektiv gruppering av inferensoppgaver og kvantifiseringsteknikker, for å oppnå økt ytelse.
LLM-er bruker vanligvis 16-biters flyttallsverdier for å representere vekter og aktiveringer. Kvantisering tar disse verdiene og reduserer dem til 8-bits flyttallverdier under inferens. De fleste modeller klarer å beholde nøyaktigheten med denne reduserte presisjonen.
Bedrifter som har en databehandlingsinfrastruktur basert på Nvidias H100-GPU-er, kan forvente en enorm forbedring av inferensytelsen uten å måtte bruke en eneste krone på å bruke TensorRT-LLM.
Nvidia brukte et eksempel på å kjøre en liten åpen kildekodemodell, GPT-J 6, for å oppsummere artikler i CNN/Daily Mail-datasettet. Den eldre A100-brikken brukes som basishastighet og sammenlignes deretter med H100 uten og deretter med TensorRT-LLM.
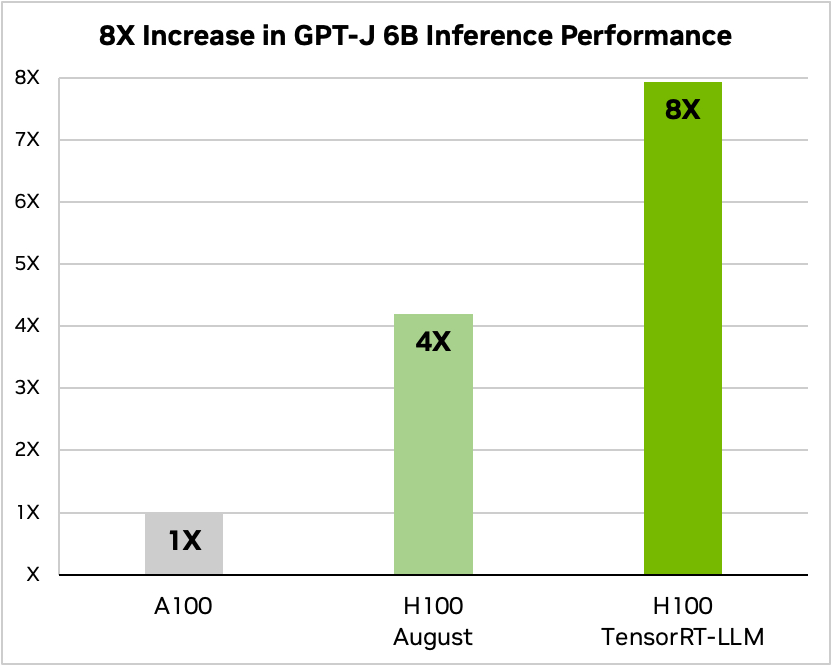
Kilde: Nvidia
Og her er en sammenligning når du kjører Meta's Llama 2
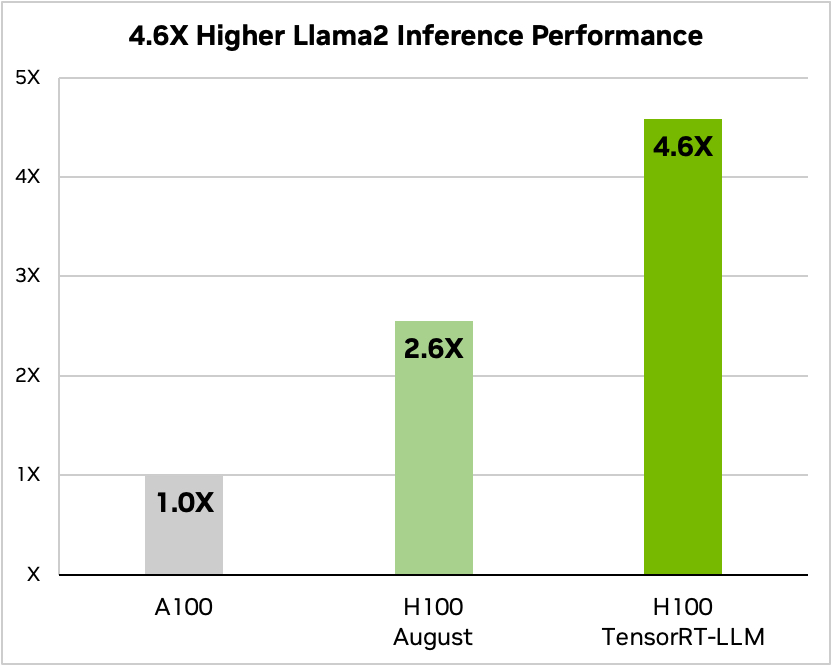
Kilde: Nvidia
Nvidia sa at testingen viste at en H100 som kjører TensorRT-LLM, avhengig av modell, bruker mellom 3,2 og 5,6 ganger mindre energi enn en A100 under inferens.
Hvis du kjører AI-modeller på H100-maskinvare, betyr dette at ikke bare vil slutningsytelsen din nesten dobles, men strømregningen din vil også bli mye mindre når du installerer denne programvaren.
TensorRT-LLM vil også bli gjort tilgjengelig for Nvidias Grace Hopper Superchips men selskapet har ikke offentliggjort ytelsestall for GH200 med den nye programvaren.
Den nye programvaren var ennå ikke klar da Nvidia kjørte sin GH200 Superchip gjennom bransjestandarden MLPerf AI-ytelsestester. Resultatene viste at GH200 presterte opptil 17% bedre enn en enkeltbrikke H100 SXM.
Hvis Nvidia oppnår selv en beskjeden økning i inferensytelsen ved hjelp av TensorRT-LLM med GH200, vil det gi selskapet et stort forsprang på de nærmeste konkurrentene. Å være salgsrepresentant for Nvidia må være den enkleste jobben i verden akkurat nå.



