

Google ha rilasciato due modelli della sua famiglia di modelli leggeri e aperti chiamati Gemma.
Mentre i modelli Gemini di Google sono proprietari, o chiusi, i modelli Gemma sono stati rilasciati come "modelli aperti" e resi liberamente disponibili agli sviluppatori.
Google ha rilasciato i modelli Gemma in due dimensioni, 2B e 7B, con varianti pre-addestrate e ottimizzate per le istruzioni. Google sta rilasciando i pesi dei modelli e una suite di strumenti per gli sviluppatori, per adattare i modelli alle loro esigenze.
Google afferma che i modelli Gemma sono stati costruiti utilizzando la stessa tecnologia che alimenta il suo modello di punta Gemini. Diverse aziende hanno rilasciato modelli 7B nel tentativo di fornire un LLM che mantenga le funzionalità utilizzabili, pur essendo potenzialmente in esecuzione a livello locale anziché nel cloud.
Llama-2-7B e Mistral-7B sono concorrenti di rilievo in questo settore, ma Google afferma che "Gemma supera modelli significativamente più grandi nei principali benchmark" e offre questo confronto come prova.
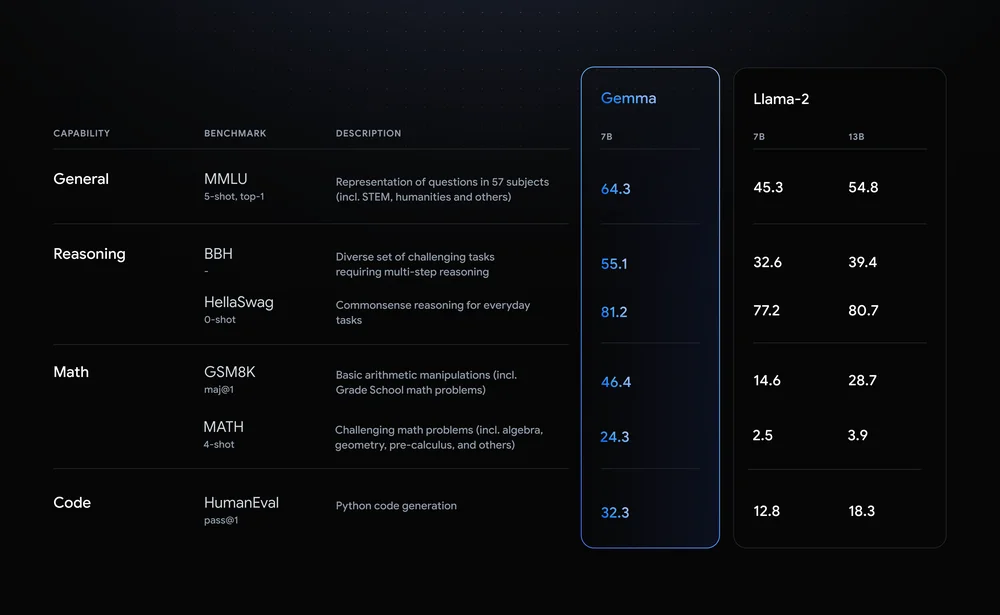
I risultati dei benchmark mostrano che Gemma batte persino la versione più grande 12B di Llama 2 in tutte e quattro le funzionalità.
L'aspetto davvero interessante di Gemma è la prospettiva di eseguirlo localmente. Google ha stretto una partnership con NVIDIA per ottimizzare Gemma per le GPU NVIDIA. Se avete un PC con una delle GPU RTX di NVIDIA, potete eseguire Gemma sul vostro dispositivo.
NVIDIA afferma di avere una base installata di oltre 100 milioni di GPU NVIDIA RTX. Questo rende Gemma un'opzione interessante per gli sviluppatori che stanno cercando di decidere quale modello leggero utilizzare come base per i loro prodotti.
NVIDIA aggiungerà anche il supporto per Gemma sul suo Chiacchierate con RTX che semplifica l'esecuzione di LLM su PC RTX.
Sebbene non sia tecnicamente open-source, sono solo le restrizioni d'uso contenute nel contratto di licenza a impedire ai modelli Gemma di possedere questa etichetta. Critiche ai modelli aperti indicano i rischi insiti nel mantenerli allineati, ma Google afferma di aver effettuato un ampio red-teaming per garantire che Gemma fosse al sicuro.
Google afferma di aver usato "un'ampia messa a punto e l'apprendimento di rinforzo dal feedback umano (RLHF) per allineare i nostri modelli regolati dalle istruzioni con comportamenti responsabili". Ha anche rilasciato un Responsible Generative AI Toolkit per aiutare gli sviluppatori a mantenere Gemma allineata dopo la messa a punto.
I modelli leggeri e personalizzabili come Gemma possono offrire agli sviluppatori più utilità di quelli più grandi come GPT-4 o Gemini Pro. La possibilità di eseguire LLM in locale senza i costi del cloud computing o delle chiamate API diventa ogni giorno più accessibile.
Con Gemma a disposizione degli sviluppatori, sarà interessante vedere la gamma di applicazioni basate sull'intelligenza artificiale che potrebbero presto essere eseguite sui nostri PC.



