

À mesure que l'ère de l'IA générative progresse, un large éventail d'entreprises se sont lancées dans la bataille, et les modèles eux-mêmes sont devenus de plus en plus diversifiés.
Dans ce contexte d'essor de l'IA, de nombreuses entreprises ont vanté leurs modèles comme étant "open source", mais qu'est-ce que cela signifie réellement dans la pratique ?
Le concept d'open source trouve son origine dans la communauté des développeurs de logiciels. Les logiciels libres traditionnels mettent le code source à la disposition de tous, qui peuvent le consulter, le modifier et le distribuer.
Par essence, le logiciel libre est un dispositif collaboratif de partage des connaissances alimenté par l'innovation logicielle, qui a conduit à des développements tels que le système d'exploitation Linux, le navigateur web Firefox et le langage de programmation Python.
Cependant, l'application de l'éthique du logiciel libre aux modèles d'IA massifs d'aujourd'hui est loin d'être simple.
Ces systèmes sont souvent formés sur de vastes ensembles de données contenant des téraoctets ou des pétaoctets de données, à l'aide d'architectures de réseaux neuronaux complexes comportant des milliards de paramètres.
Les ressources informatiques nécessaires coûtent des millions de dollars, les talents sont rares et la propriété intellectuelle est souvent bien protégée.
Nous pouvons l'observer à l'OpenAI, qui, comme son nom l'indique, était un laboratoire de recherche sur l'IA largement dédié à l'éthique de la recherche ouverte.
Toutefois, cette une éthique rapidement érodée une fois que l'entreprise a senti l'odeur de l'argent et qu'elle a eu besoin d'attirer des investissements pour atteindre ses objectifs.
Pourquoi ? Parce que les produits à code source ouvert ne sont pas axés sur le profit, et que l'IA est coûteuse et précieuse.
Cependant, avec l'explosion de l'IA générative, des entreprises comme Mistral, Meta, BLOOM et xAI publient des modèles libres pour faire avancer la recherche tout en empêchant des entreprises comme Microsoft et Google de s'accaparer trop d'influence.
Mais combien de ces modèles sont réellement ouverts par nature, et pas seulement par leur nom ?
Clarifier le degré d'ouverture réel des modèles de logiciels libres
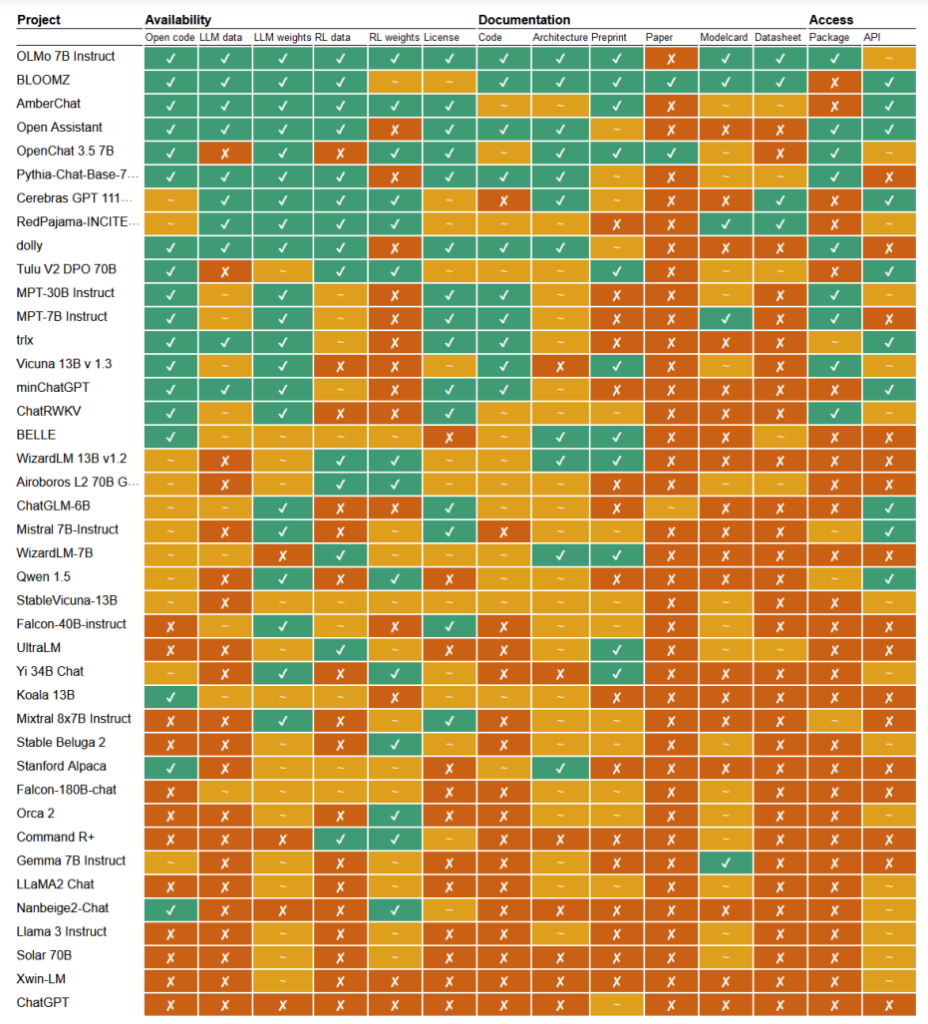
Dans un récent étudeLes chercheurs Mark Dingemanse et Andreas Liesenfeld de l'université Radboud, aux Pays-Bas, ont analysé de nombreux modèles d'intelligence artificielle de premier plan pour déterminer leur degré d'ouverture. Ils ont étudié plusieurs critères, tels que la disponibilité du code source, des données d'entraînement, des poids des modèles, des documents de recherche et des API.
Par exemple, le modèle LLaMA de Meta et le modèle Gemma de Google ont été jugés simplement "à poids ouvert", ce qui signifie que le modèle formé est mis à la disposition du public pour être utilisé sans transparence totale sur son code, son processus d'apprentissage, ses données et ses méthodes de mise au point.
À l'autre bout du spectre, les chercheurs ont mis en avant BLOOM, un grand modèle multilingue développé par une collaboration de plus de 1 000 chercheurs dans le monde entier, comme un exemple de véritable IA à source ouverte. Chaque élément du modèle est librement accessible à des fins d'inspection et de recherche.
Le document a évalué plus de 30 modèles (texte et image), mais ceux-ci démontrent l'immense variation au sein de ceux qui prétendent être des sources ouvertes :
- BloomZ (BigScience): Entièrement ouvert sur tous les critères, y compris le code, les données d'entraînement, les poids des modèles, les documents de recherche et l'API. Mis en avant comme un exemple d'IA véritablement open-source.
- OLMo (Allen Institute for AI) : Code ouvert, données d'entraînement, poids et documents de recherche. L'API n'est que partiellement ouverte.
- Mistral 7B-Instruct (Mistral AI): Modèle ouvert de poids et d'API. Le code et les documents de recherche ne sont que partiellement ouverts. Les données d'entraînement ne sont pas disponibles.
- Orca 2 (Microsoft): Poids des modèles et documents de recherche partiellement ouverts. Code, données d'entraînement et API fermés.
- Instructeur Gemma 7B (Google): Code et poids partiellement ouverts. Les données d'entraînement, les documents de recherche et l'API sont fermés. Décrit comme "ouvert" par Google plutôt que comme "open source".
- Llama 3 Instruct (Meta): Poids partiellement ouverts. Code, données d'entraînement, documents de recherche et API fermés. Un exemple de modèle de "poids ouvert" sans transparence plus complète.
Un manque de transparence
Le manque de transparence entourant les modèles d'IA, en particulier ceux développés par les grandes entreprises technologiques, soulève de sérieuses inquiétudes quant à la responsabilité et à la surveillance.
Sans un accès complet au code du modèle, aux données d'entraînement et à d'autres éléments clés, il devient extrêmement difficile de comprendre le fonctionnement de ces modèles et de prendre des décisions. Il est donc difficile d'identifier et de corriger les biais, les erreurs ou l'utilisation abusive de matériel protégé par le droit d'auteur.
La violation des droits d'auteur dans les données d'entraînement de l'IA est un excellent exemple des problèmes qui découlent de ce manque de transparence. De nombreux modèles d'IA propriétaires, tels que GPT-3.5/4/40/Claude 3/Gemini, sont probablement formés à partir de matériel protégé par le droit d'auteur.
Cependant, comme les données de formation sont conservées sous clé, il est pratiquement impossible d'identifier des données spécifiques dans ce matériel.
Le New York Times procès récent contre l'OpenAI démontre les conséquences de ce défi dans le monde réel. OpenAI a accusé le NYT d'utiliser des attaques d'ingénierie rapide pour exposer les données d'entraînement et inciter ChatGPT à reproduire ses articles mot pour mot, prouvant ainsi que les données d'entraînement d'OpenAI contiennent des éléments protégés par le droit d'auteur.
"Le Times a payé quelqu'un pour pirater les produits d'OpenAI", a déclaré OpenAI.
En réponse, Ian Crosby, principal conseiller juridique du NYT, a déclaré : "Ce qu'OpenAI qualifie bizarrement de "piratage", c'est simplement l'utilisation des produits d'OpenAI pour chercher des preuves qu'ils ont volé et reproduit les œuvres protégées par le droit d'auteur du Times. Et c'est exactement ce que nous avons trouvé.
En effet, il ne s'agit là que d'un exemple parmi tant d'autres de poursuites judiciaires qui sont actuellement bloquées en partie à cause de la nature opaque et impénétrable des modèles d'IA.
Il ne s'agit là que de la partie émergée de l'iceberg. En l'absence de mesures robustes de transparence et de responsabilité, nous risquons de nous retrouver dans un avenir où des systèmes d'IA inexplicables prendront des décisions qui auront un impact profond sur nos vies, notre économie et notre société, tout en restant à l'abri d'un examen minutieux.
Appel à l'ouverture
Des appels ont été lancés pour que des entreprises comme Google et OpenAI donner accès au fonctionnement interne de leurs modèles aux fins de l'évaluation de la sécurité.
Cependant, la vérité est que même les entreprises spécialisées dans l'IA ne comprennent pas vraiment le fonctionnement de leurs modèles.
C'est ce qu'on appelle le problème de la "boîte noire", qui se pose lorsqu'on essaie d'interpréter et d'expliquer les décisions spécifiques du modèle d'une manière compréhensible pour l'homme.
Par exemple, un développeur peut savoir qu'un modèle d'apprentissage profond est précis et performant, mais il peut avoir du mal à déterminer exactement les caractéristiques que le modèle utilise pour prendre ses décisions.
Anthropic, qui a développé les modèles Claude, a récemment a mené une expérience pour identifier le fonctionnement de Claude 3 Sonnet, en expliquant : "Nous traitons généralement les modèles d'IA comme une boîte noire : quelque chose entre et une réponse sort, sans que l'on sache exactement pourquoi le modèle a donné cette réponse particulière plutôt qu'une autre. Il est donc difficile de croire que ces modèles sont sûrs : si nous ne savons pas comment ils fonctionnent, comment pouvons-nous savoir qu'ils ne donneront pas de réponses nuisibles, biaisées, mensongères ou autrement dangereuses ? Comment pouvons-nous être sûrs qu'ils sont sûrs et fiables ?".
Le fait que le créateur d'une technologie ne comprenne pas son produit à l'ère de l'IA est un aveu assez remarquable.
Cette expérience anthropique a montré que l'explication objective des résultats est une tâche exceptionnellement délicate. En fait, Anthropic a estimé qu'il faudrait plus de puissance de calcul pour "ouvrir la boîte noire" que pour entraîner le modèle lui-même !
Les développeurs tentent de lutter activement contre le problème des boîtes noires en menant des recherches telles que l'"IA explicable" (XAI), qui vise à développer des techniques et des outils pour rendre les modèles d'IA plus transparents et plus faciles à interpréter.
Les méthodes XAI visent à fournir des informations sur le processus de prise de décision du modèle, à mettre en évidence les caractéristiques les plus influentes et à générer des explications lisibles par l'homme. L'IAO a déjà été appliquée à des modèles déployés dans le cadre d'enquêtes à enjeux élevés. applications telles que le développement de médicamentsoù la compréhension du fonctionnement d'un modèle peut être déterminante pour la sécurité.
Les initiatives en matière de logiciels libres sont essentielles pour l'IAO et d'autres recherches qui cherchent à pénétrer la boîte noire et à assurer la transparence des modèles d'IA.
Sans accès au code du modèle, aux données d'entraînement et à d'autres éléments clés, les chercheurs ne peuvent pas développer et tester des techniques permettant d'expliquer le fonctionnement réel des systèmes d'IA et d'identifier les données spécifiques sur lesquelles ils ont été entraînés.
Les réglementations risquent de rendre la situation encore plus confuse en ce qui concerne les logiciels libres
L'Union européenne Loi sur l'IA récemment adoptée s'apprête à introduire de nouvelles réglementations pour les systèmes d'IA, avec des dispositions qui concernent spécifiquement les modèles à source ouverte.
En vertu de la loi, les modèles d'usage général à source ouverte, jusqu'à une certaine taille, seront exemptés d'exigences de transparence étendues.
Toutefois, comme le soulignent Dingemanse et Liesenfeld dans leur étude, la définition exacte de l'"IA open source" dans le cadre de la loi sur l'IA n'est pas encore claire et pourrait devenir un point de discorde.
La loi définit actuellement les modèles à source ouverte comme ceux qui sont publiés sous une licence "libre et ouverte" qui permet aux utilisateurs de modifier le modèle. Cependant, elle ne précise pas les exigences relatives à l'accès aux données de formation ou à d'autres éléments clés.
Cette ambiguïté laisse place à l'interprétation et au lobbying potentiel des entreprises. Les chercheurs préviennent que l'affinement de la définition de l'open source dans la loi sur l'IA "constituera probablement un point de pression unique qui sera pris pour cible par les lobbies d'entreprises et les grandes sociétés".
En l'absence de critères clairs et solides pour définir ce qu'est une IA véritablement libre, la réglementation pourrait involontairement créer des lacunes ou inciter les entreprises à s'engager dans le "lavage ouvert", c'est-à-dire à revendiquer l'ouverture pour des raisons juridiques et de relations publiques tout en conservant des aspects importants de leurs modèles exclusifs.
En outre, la nature mondiale du développement de l'IA signifie que des réglementations différentes d'une juridiction à l'autre pourraient compliquer davantage le paysage.
Si les principaux producteurs d'IA, comme les États-Unis et la Chine, adoptent des approches divergentes en matière d'ouverture et de transparence, il pourrait en résulter un écosystème fragmenté dans lequel le degré d'ouverture varierait considérablement en fonction de l'origine d'un modèle.
Les auteurs de l'étude soulignent la nécessité pour les régulateurs de collaborer étroitement avec la communauté scientifique et les autres parties prenantes afin de s'assurer que toute disposition relative aux sources ouvertes dans la législation sur l'IA repose sur une compréhension approfondie de la technologie et des principes d'ouverture.
Comme le concluent Dingemanse et Liesenfeld dans un discussion avec la natureIl est juste de dire que le terme "open source" aura un poids juridique sans précédent dans les pays régis par la loi européenne sur l'IA.
La façon dont cela se déroulera dans la pratique aura des répercussions considérables sur l'orientation future de la recherche et du déploiement de l'IA.



