
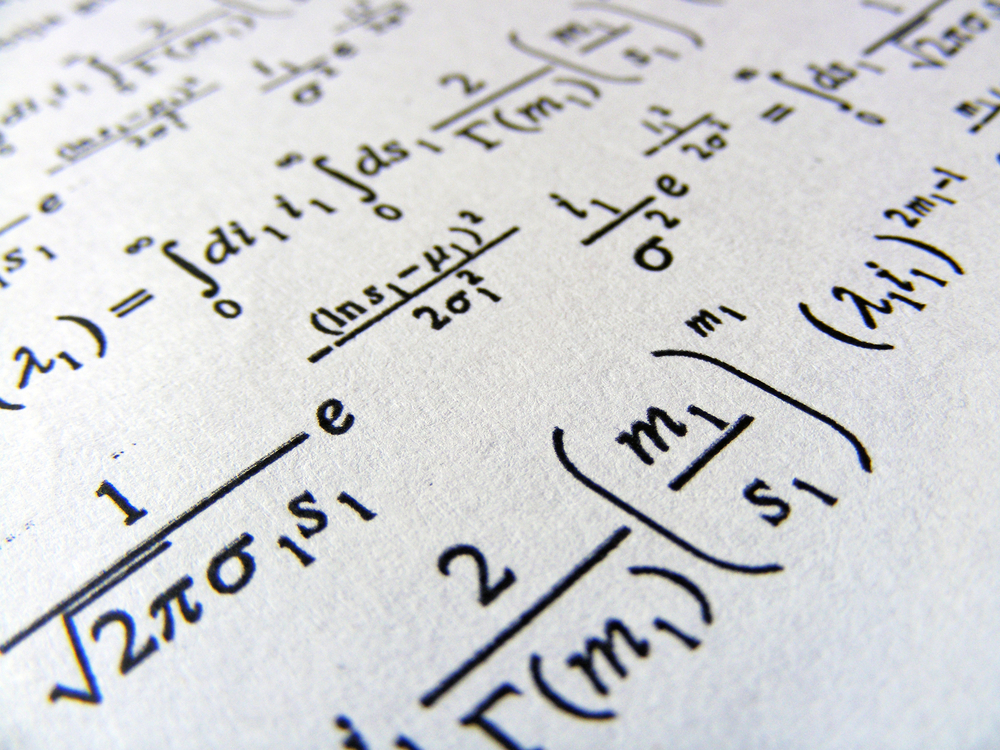
Meta a développé un nouveau modèle d'IA appelé Nougat qui peut transformer de manière fiable un texte scientifique en texte lisible par une machine.
Si vous avez déjà essayé de lire un document de recherche scientifique, vous commencez à comprendre pourquoi il est difficile de le traiter électroniquement. Les outils actuels de reconnaissance optique de caractères (OCR) analysent le texte ligne par ligne.
C'est une bonne chose pour les documents purement textuels, mais les articles scientifiques ajoutent un niveau de complexité que ces outils standard ne peuvent pas gérer.
Les documents scientifiques comportent des symboles et des formules mathématiques et scientifiques qui sont souvent ajoutés en indice ou en exposant. Même les meilleurs OCR ont du mal à les capturer correctement.
Le défi est d'autant plus grand qu'un grand nombre de ces documents de recherche sont mal numérisés et que les originaux ne sont plus disponibles. Nougat, qui signifie Neural Optical Understanding for Academic Documents, est prêt à relever le défi.
Au lieu de scanner ligne par ligne, Nougat traite la page entière en utilisant une variante du Vision Transformer de Meta pour l'analyse d'images. Le modèle a été entraîné sur un ensemble d'articles publiés sur PubMed Central et arXiv, dont le code source LaTeX correspondait.
LaTeX est un logiciel utilisé pour rédiger des articles scientifiques qui font appel à des formules complexes et à des symboles mathématiques. Le modèle a été formé en examinant l'image du document et en la comparant au code qui a généré le texte complexe.
Voici un exemple de l'une des expériences de Meta en matière de numérisation d'un ancien document de recherche.

Source : Méta
Il existe d'autres exemples impressionnants sur le site Page de recherche Facebook.
Nougat n'est pas parfait, mais il a tout de même obtenu un score BLEU de plus de 91% et une précision de plus de 96% avec du texte continu. Le score BLEU mesure la similarité du texte traduit par la machine avec un ensemble de traductions de référence de haute qualité.
Pour les formules et les tableaux, il s'en sort un peu moins bien avec une précision d'un peu plus de 75%. C'est tout de même beaucoup mieux que des modèles concurrents comme GROBID, qui ne réussit à avoir raison que dans 11% des cas.
Des millions de pages de recherche ne sont pas indexables ou consultables parce qu'elles ne peuvent être lues que par des humains. Nougat change la donne en permettant de convertir en texte lisible par une machine même les PDF de recherche mal numérisés.
Comme pour la plupart de ses autres nouveaux outils, Meta a fait en sorte que celui-ci soit librement utilisable. disponible sur GitHub. Cette évolution peut toutefois présenter un certain intérêt personnel. Une fois que les anciens documents de recherche sont lisibles par machine, ils deviennent disponibles pour l'entraînement d'autres modèles d'intelligence artificielle.
Il sera intéressant de voir quels joyaux de la recherche, perdus depuis longtemps, seront redécouverts grâce à Nougat.



