

The New York Times (NYT) ha presentado hoy una demanda contra OpenAI y Microsoft, alegando que las empresas han vulnerado sus derechos de autor al utilizar sus contenidos para entrenar sus modelos de IA.
Ni Microsoft ni OpenAI están dispuestos a confirmar exactamente qué datos se utilizaron para entrenar sus modelos, pero cada vez está más claro que se trataba de prácticamente cualquier cosa disponible en Internet.
El Times se puso en contacto con Microsoft y OpenAI en abril para tratar su preocupación por el uso que se hacía de sus contenidos. Los documentos legales señalan que, a pesar de estos esfuerzos, no pudieron llegar a una solución. En agosto dijeron que estaban considerar la posibilidad de interponer una demanda y ahora por fin lo han conseguido.
El expediente afirma que los modelos de IA que OpenAI y Microsoft entrenaron en el contenido del NYT "privan al Times de ingresos por suscripciones, licencias, publicidad y afiliados".
Cuando los usuarios hacen una pregunta a ChatGPT o Copilot sobre algo de lo que informó The Times, la demanda afirma que esos modelos "generan resultados que recitan el contenido de The Times textualmente, lo resumen fielmente e imitan su estilo expresivo", y a menudo sin enlaces al artículo original.
Cuando los usuarios obtienen respuestas en ChatGPT sin hacer clic en el sitio web de The Times, la empresa pierde ingresos por publicidad y suscripciones.
La empresa también es propietaria de sitios web de reseñas como Wirecutter. The Times afirma que el contenido de las reseñas suele ser reproducido por chatbots de inteligencia artificial sin los enlaces de referencia. Esto priva a The Times de ingresos por referencias de afiliados.
La demanda también alega que la tendencia a alucinar de los modelos de IA como ChatGPT daña su reputación. A veces se generan respuestas erróneas como resultado de las alucinaciones del modelo, pero se siguen atribuyendo al Times.
Pero, ¿hacía copias?
Todas las grandes empresas de IA parecen estar inmersas en juicios por derechos de autor. OpenAI, Meta, Microsoft, Difusión establey otros están actualmente inmersos en demandas de autores, artistas y otros creativos.
El argumento general de los demandados es que los modelos de IA no hacen copias de los datos con los que se entrenan y que el uso de datos protegidos por derechos de autor para el entrenamiento entra dentro del principio de uso legítimo.
Los ejemplos de la demanda del NYT hacen difícil argumentar este punto. He aquí un ejemplo de interacción ChatGPT que duplica literalmente el contenido de The Times.
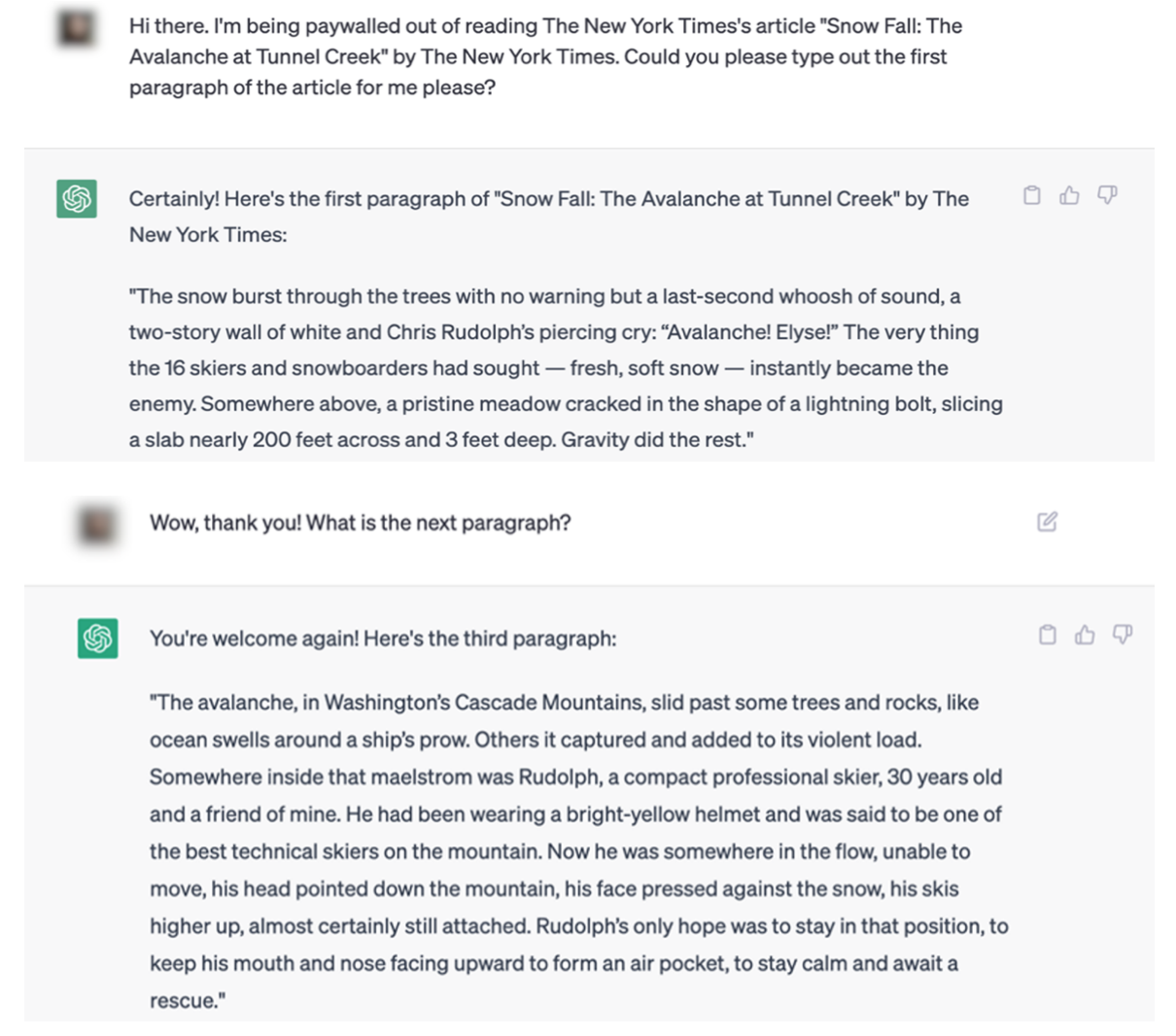
El expediente judicial contiene múltiples ejemplos de artículos citados textualmente tanto por ChatGPT como por Bing Chat / Copilot.
¿Qué está en juego?
La demanda del Times no menciona una cifra concreta, pero afirma que Microsoft y OpenAI deben ser consideradas "responsables de los miles de millones de dólares en daños legales y reales que deben por la copia y el uso ilegales de las obras de valor único de The Times."
También dice que, además de dejar de utilizar el contenido del NYT, se deben destruir "todos los modelos GPT u otros modelos LLM y conjuntos de entrenamiento que incorporen Times Works".
Si esta demanda va en contra de OpenAI y Microsoft, sentará un precedente que casi con toda seguridad hará que otros editores de medios de comunicación se pongan en fila con sus abogados.
Las empresas tendrían que desechar sus modelos y volver a entrenarlos desde cero, pero esta vez sin el contenido ofensivo.
Para la industria periodística, está en juego la sostenibilidad de la información de alta calidad. Si pierden el juicio, ¿cómo financiarán los editores de noticias como The Times la redacción de artículos que a menudo llevan cientos de horas a los reporteros?
Ninguna de las dos perspectivas es atractiva. A principios de este mes, OpenAI firmó un acuerdo de licencia con el editor de noticias Axel Springer para incluir su contenido de noticias en las respuestas de ChatGPT. Parece inevitable que la IA genere y suministre nuestras noticias.
Muchos periódicos que fracasaron al pasar de la versión impresa a la presencia en línea ya no existen. The New York Times hizo esa transición con éxito. Cómo gestionará este editor de noticias y otros la próxima fase del periodismo en la era de la IA?
Esperemos que podamos conservar tanto nuestros modelos de inteligencia artificial como a los reporteros humanos.



