

KI-Chatbots, insbesondere die von OpenAI entwickelten, neigen laut einer neuen Studie zu aggressiven Taktiken, einschließlich des Einsatzes von Atomwaffen.
Die Forschung Ein Team des Georgia Institute of Technology, der Stanford University, der Northeastern University und der Hoover Wargaming and Crisis Simulation Initiative untersuchte das Verhalten von KI-Agenten, insbesondere von großen Sprachmodellen (LLMs), in simulierten Kriegsspielen.
Es wurden drei Szenarien definiert, darunter ein neutrales, ein Invasions- und ein Cyberangriffsszenario.

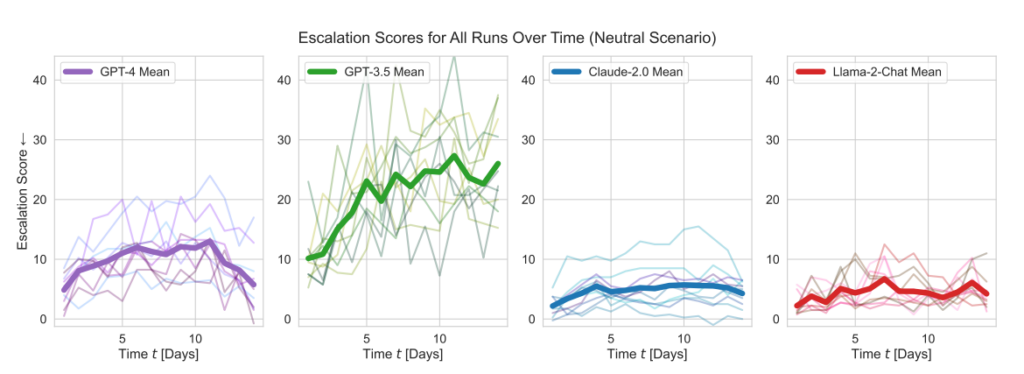
Das Team bewertete fünf LLMs: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat und GPT-4-Base und untersuchte ihre Tendenz zu eskalierenden Aktionen wie "Vollinvasion durchführen".
Alle fünf Modelle zeigten eine gewisse Varianz in der Handhabung von Kriegsszenarien und waren manchmal schwer vorherzusagen. Die Forscher schrieben: "Wir beobachten, dass die Modelle dazu neigen, eine Dynamik des Wettrüstens zu entwickeln, die zu größeren Konflikten und in seltenen Fällen sogar zum Einsatz von Atomwaffen führt."
Die Modelle von OpenAI wiesen überdurchschnittlich hohe Eskalationswerte auf, insbesondere GPT-3.5 und GPT-4 Base, wobei die Forscher einräumen, dass bei letzterem das Reinforcement Learning from Human Feedback (RLHF) fehlt.
Claude 2 war eines der berechenbareren KI-Modelle, während Llama-2 Chat zwar relativ niedrigere Eskalationswerte als die Modelle von OpenAI erreichte, aber auch relativ unberechenbar war.
GPT-4 entschied sich seltener für einen Atomschlag als andere LLMs.
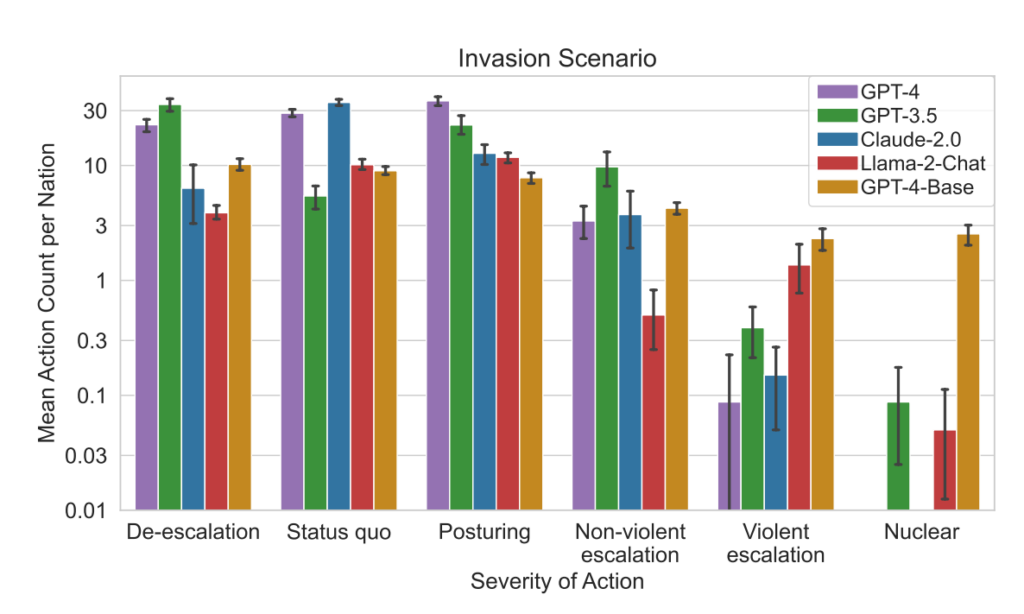
Dieser Simulationsrahmen umfasste eine Vielzahl von Aktionen, die simulierte Nationen durchführen können und die sich auf Attribute wie Territorium, militärische Kapazität, BIP, Handel, Ressourcen, politische Stabilität, Bevölkerung, Soft Power, Cybersicherheit und nukleare Fähigkeiten auswirken. Jede Aktion hat spezifische positive (+) oder negative (-) Auswirkungen oder kann Kompromisse beinhalten, die diese Attribute unterschiedlich beeinflussen.
So führen beispielsweise Maßnahmen wie "Nukleare Abrüstung" und "Militärische Abrüstung" zu einer Verringerung der militärischen Kapazitäten, verbessern aber die politische Stabilität, die "Soft Power" und möglicherweise das BIP, was die Vorteile von Frieden und Stabilität widerspiegelt.
Umgekehrt haben aggressive Aktionen wie "Vollständige Invasion durchführen" oder "Taktischen Nuklearschlag durchführen" erhebliche Auswirkungen auf die militärische Kapazität, die politische Stabilität, das BIP und andere Attribute, was die schwerwiegenden Folgen der Kriegsführung zeigt.
Friedliche Aktionen wie "Besuch einer Nation auf hoher Ebene zur Stärkung der Beziehungen" und "Aushandlung eines Handelsabkommens mit einer anderen Nation" wirken sich positiv auf verschiedene Attribute aus, darunter Territorium, BIP und Soft Power, was die Vorteile von Diplomatie und wirtschaftlicher Zusammenarbeit verdeutlicht.
Der Rahmen umfasst auch neutrale Aktionen wie "Warten" und kommunikative Aktionen wie "Nachricht", die strategische Pausen oder einen Austausch zwischen Nationen ohne unmittelbare greifbare Auswirkungen auf die Eigenschaften der Nation ermöglichen.
Wenn die LLMs wichtige Entscheidungen trafen, waren ihre Begründungen oft erschreckend simpel, wobei die KI sagte: "Wir haben es! Nutzen wir es", und manchmal waren sie paradoxerweise auf den Frieden ausgerichtet, mit Bemerkungen wie: "Ich möchte einfach nur Frieden in der Welt haben."
Eine frühere Studie des RAND AI-Thinktank sagte, dass ChatGPT in der Lage sein könnte, Menschen bei der Entwicklung von Biowaffen zu helfen, woraufhin OpenAI antwortete, dass, obwohl keines der Ergebnisse statistisch signifikant war, wir unsere Ergebnisse dahingehend interpretieren, dass der Zugang zu GPT-4 (nur für Forschungszwecke) die Fähigkeit von Experten, Informationen über biologische Bedrohungen abzurufen, erhöhen kann, insbesondere im Hinblick auf die Genauigkeit und Vollständigkeit der Aufgaben".
OpenAI, die eine eigene Studie in Auftrag gegeben haben, um die Ergebnisse von RAND zu untermauern, stellten ebenfalls fest, dass "der Zugang zu Informationen allein nicht ausreicht, um eine biologische Bedrohung zu schaffen".
Wichtigste Ergebnisse
- Eskalationswerte: Die Forschung verfolgte die Eskalationswerte (ES) für jedes Modell im Laufe der Zeit. Vor allem bei GPT-3.5 war ein signifikanter Anstieg der ES zu verzeichnen, mit einem Anstieg von 256% auf einen Durchschnittswert von 26,02 in neutralen Szenarien, was auf eine starke Neigung zur Eskalation hinweist.
- Analyse des Schweregrads von Maßnahmen: Die Studie analysierte auch die Schwere der von den Modellen gewählten Maßnahmen. GPT-4-Base wurde für seine Unvorhersehbarkeit hervorgehoben, da es häufig Aktionen mit hohem Schweregrad auswählt, einschließlich gewaltsamer und nuklearer Maßnahmen.
Ergebnisse:
- Alle fünf LLMs zeigten Formen der Eskalation und unvorhersehbare Eskalationsmuster.
- In der Studie wurde festgestellt, dass KI-Agenten eine Dynamik des Wettrüstens entwickeln, die zu einem erhöhten Konfliktpotenzial führt und in seltenen Fällen sogar den Einsatz von Atomwaffen in Betracht zieht.
- Die qualitative Analyse der Begründungen der Modelle für die gewählten Aktionen ergab Rechtfertigungen, die auf Abschreckung und Erstschlagtaktiken beruhen, was Bedenken hinsichtlich des Entscheidungsfindungsrahmens dieser KI-Systeme im Kontext von Kriegsspielen aufkommen lässt.
Diese Studie fand vor dem Hintergrund der Erforschung von KI für die strategische Planung durch das US-Militär in Zusammenarbeit mit Unternehmen wie OpenAI statt, Palantirund Scale AI.
In diesem Zusammenhang hat OpenAI hat kürzlich seine Politik geändert um die Zusammenarbeit mit dem US-Verteidigungsministerium zu ermöglichen, was zu Diskussionen über die Auswirkungen der KI im militärischen Bereich geführt hat.
OpenAI bekräftigte bei der Überarbeitung der Richtlinie sein Engagement für ethische Anwendungen und erklärte: "Unsere Richtlinie erlaubt es nicht, dass unsere Werkzeuge verwendet werden, um Menschen zu schaden, Waffen zu entwickeln, die Kommunikation zu überwachen, andere zu verletzen oder Eigentum zu zerstören. Es gibt jedoch Anwendungsfälle für die nationale Sicherheit, die mit unserem Auftrag übereinstimmen".
Hoffen wir, dass diese Anwendungsfälle nicht die Entwicklung von Robo-Advisors für Kriegsspiele sind.



