

Forscher haben FANToM eingeführt, einen neuartigen Benchmark, mit dem das Verständnis und die Anwendung der Theory of Mind (ToM) von großen Sprachmodellen (LLMs) rigoros getestet und bewertet werden kann.
Unter Theory of Mind versteht man die Fähigkeit, sich selbst und anderen Überzeugungen, Wünsche und Wissen zuzuordnen und zu verstehen, dass andere andere Überzeugungen und Sichtweisen haben als man selbst.
ToM wird als Grundlage für das Bewusstsein intelligenter Tiere angesehen. Neben dem Menschen verfügen auch Primaten wie Orang-Utans, Gorillas und Schimpansen sowie einige Nichtprimaten wie Papageien und Rabenvögel (Krähen) über ToM.
Da KI-Modelle immer komplexer werden, suchen KI-Forscher nach neuen Methoden zur Bewertung von Fähigkeiten wie ToM.
Ein neuer Benchmark namens FANToMdas von Forschern des Allen Institute for AI, der University of Washington, der Carnegie Mellon University und der Seoul National University entwickelt wurde, unterzieht Modelle für maschinelles Lernen dynamischen Szenarien, die reale Interaktionen widerspiegeln.
In FANToM treten die Charaktere in Gespräche ein und aus, was die KI-Modelle vor die Herausforderung stellt, genau zu wissen, wer was zu einem bestimmten Zeitpunkt weiß.
Bei der Prüfung großer Sprachmodelle (LLMs) mit FANToM zeigte sich, dass selbst die fortschrittlichsten Modelle Schwierigkeiten haben, eine konsistente ToM aufrechtzuerhalten.
Die Leistung der Modelle war deutlich geringer als die der menschlichen Teilnehmer, was die Grenzen der KI beim Verstehen und Steuern komplexer sozialer Interaktionen verdeutlicht.
Tatsächlich dominierten die Menschen in jeder Kategorie, wie unten dargestellt.
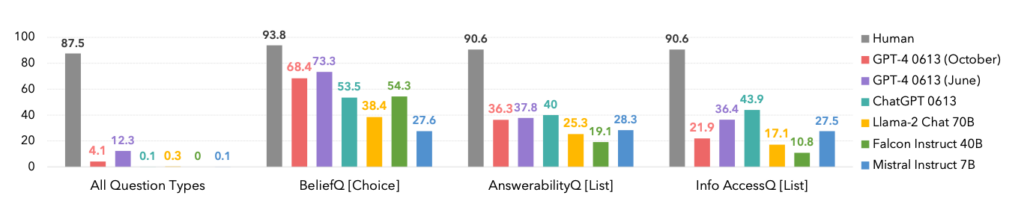
Ein interessanter Nebenaspekt ist, dass die Oktober-Version des GPT-4-Modells von einer früheren Juni-Version übertroffen wurde, was die jüngsten Anekdoten von Nutzern bestätigen könnte, dass ChatGPT wird immer schlechter.
FANToM hat auch Techniken zur Verbesserung des LLM ToM aufgezeigt, wie z.B. das Denken in Gedankenketten und andere Feinabstimmungsmethoden.
Die Kluft zwischen KI und menschlichen ToM-Fähigkeiten ist jedoch nach wie vor groß.
KI nähert sich menschenähnlichen Sprachkenntnissen
In einem etwas verwandten, aber separaten Studie veröffentlicht in Naturehaben Wissenschaftler ein neuronales Netz entwickelt, das in der Lage ist, Sprache ähnlich wie der Mensch zu verallgemeinern.
Dieses neue neuronale Netz zeigte eine beeindruckende Fähigkeit, neu gelernte Wörter in seinen bestehenden Wortschatz zu integrieren. Es konnte diese Wörter dann in verschiedenen Kontexten verwenden - eine kognitive Fähigkeit, die als systematische Generalisierung bekannt ist.
Menschen zeigen von Natur aus eine systematische Verallgemeinerung und nehmen neue Vokabeln nahtlos in ihr Repertoire auf.
Wenn jemand zum Beispiel den Begriff "Fotobombe" gelernt hat, kann er ihn fast sofort in verschiedenen Situationen anwenden. Ständig tauchen neue Slangs auf, und die Menschen nehmen sie ganz natürlich in ihren Wortschatz auf.
Die Forscher unterzogen sowohl ihr eigenes benutzerdefiniertes neuronales Netzwerk als auch ChatGPT einer Reihe von Tests und stellten fest, dass ChatGPT in der Leistung hinter dem benutzerdefinierten Modell zurückblieb.
Während LLMs wie ChatGPT in vielen Konversationsszenarien hervorragende Leistungen erbringen, weisen sie in anderen Szenarien auffällige Inkonsistenzen und Lücken auf, ein Problem, das dieses neue neuronale Netzwerk angeht.
Um diesen Aspekt der sprachlichen Kommunikation zu untersuchen, führten die Forscher ein Experiment mit 25 menschlichen Teilnehmern durch, bei dem ihre Fähigkeit, neu gelernte Wörter in verschiedenen Kontexten anzuwenden, bewertet wurde. Die Probanden wurden in eine Pseudosprache eingeführt, die aus Nonsens-Wörtern besteht, die verschiedene Handlungen und Regeln darstellen.
Nach einer Trainingsphase wendeten die Teilnehmer diese abstrakten Regeln mit Bravour auf neue Situationen an und zeigten so eine systematische Generalisierung.
Als das neu entwickelte neuronale Netz mit dieser Aufgabe konfrontiert wurde, entsprach es der menschlichen Leistung. Als ChatGPT jedoch der gleichen Herausforderung ausgesetzt wurde, hatte es erhebliche Schwierigkeiten und versagte je nach Aufgabe in 42 bis 86% der Zeit.
Dies ist aus zwei Gründen von Bedeutung. Erstens könnte man argumentieren, dass dieses neue neuronale Netz das GPT-4 bei dieser speziellen Aufgabe tatsächlich übertrifft - was schon beeindruckend genug ist. Zweitens zeigt diese Studie neue Methoden auf, mit denen KI-Modellen beigebracht werden kann, neue Sprache wie Menschen zu verallgemeinern.
Wie Elia Bruni, Spezialist für die Verarbeitung natürlicher Sprache an der Universität Osnabrück in Deutschland, beschreibt, "ist es eine große Sache, Systematik in neuronale Netze zu bringen".
Zusammen bieten diese beiden Studien neue Ansätze für das Training intelligenterer KI-Modelle, die es in wichtigen Bereichen wie Linguistik und Theory of Mind mit dem Menschen aufnehmen können.



