

De Forenede Arabiske Emiraters Technology Innovation Institute (TII) frigav sin Falcon 180B LLM på Hugging Face i sidste uge, og den leverede en imponerende præstation i de første tests.
Modellen, som er frit tilgængelig for forskere og kommercielle brugere, er et produkt af en spirende AI-industri i Mellemøsten.
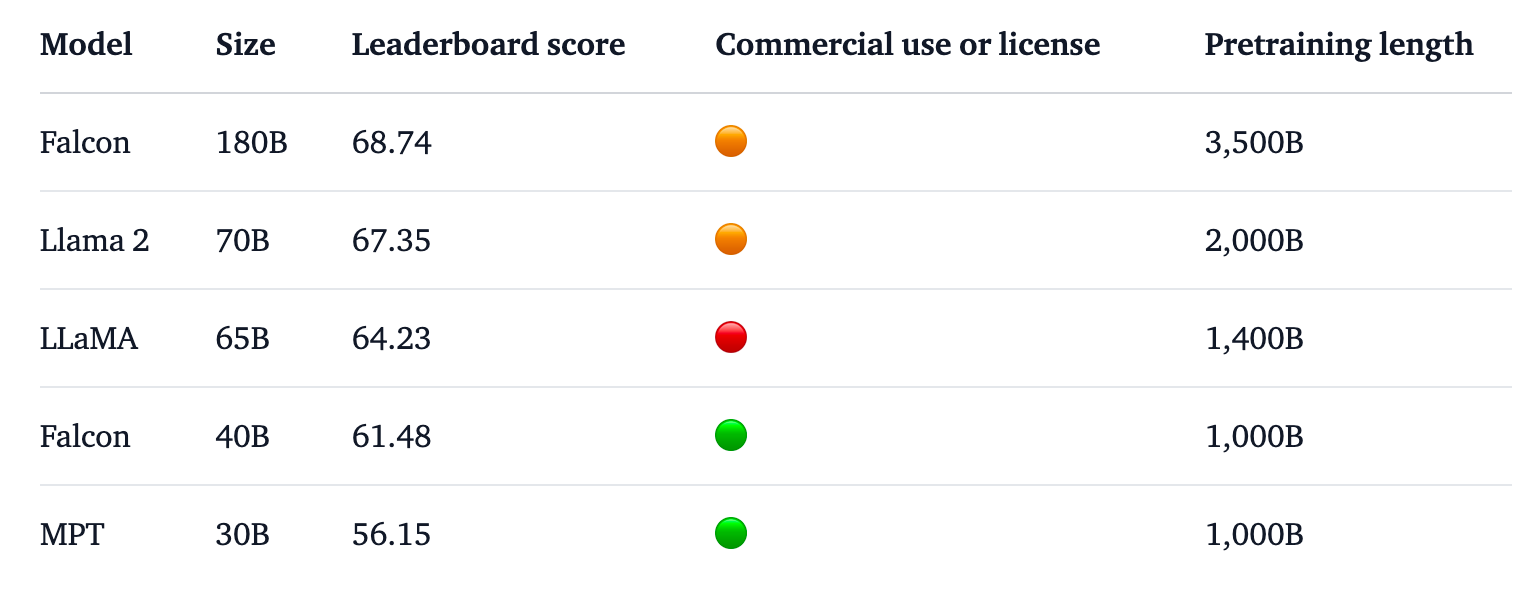
Falcon 180B er 2,5 gange større end Metas Lama 2 og blev trænet med 4 gange mere computerkraft. TII trænede modellen på hele 3,5 billioner tokens. Det er den unikke datasættilgang, der i høj grad er ansvarlig for modellens imponerende præstation.
For at træne en model har man ikke bare brug for en masse data, man har typisk brug for en masse kuraterede data af god kvalitet. Det koster mange penge at producere, og der er ikke mange virkelig store kuraterede datasæt, som er offentligt tilgængelige. TII besluttede at prøve en ny tilgang for at undgå behovet for kuratering.
I juni brugte forskere omhyggelig filtrering og deduplikering af offentligt tilgængelige CommonCrawl-data for at skabe RefinedWeb-datasættet. Dette datasæt var ikke kun lettere at producere, men det giver også bedre resultater end blot at bruge kuraterede korpora eller webdata.
Falcon 180B blev trænet på hele 3,5 billioner tokens fra RefinedWeb-datasættet, hvilket er betydeligt mere end de 2 billioner tokens fra Llama 2's prætræningsdatasæt.
Falcon 180B's ydeevne
Falcon 180B topper Hugging Face-ranglisten for LLM'er med åben adgang. Modellen klarer sig bedre end Llama 2, den tidligere leder, på en række benchmarks, herunder ræsonnement, kodning, færdigheder og videnstest.
Falcon 180B scorer endda højt, når den sammenlignes med lukkede, proprietære modeller. Den ligger lige efter GPT-4 og er på niveau med Googles PaLM 2 Large, som er dobbelt så stor som Falcon 180B.
Kilde: Kramende ansigt
TII siger, at de på trods af den allerede imponerende præstation med den prætrænede model har til hensigt "at levere stadig mere effektive versioner af Falcon i fremtiden, baseret på forbedrede datasæt og RLHF/RLAIF."
Du kan prøve en chat-version af modellen med dette Demo af Falcon 180B på Hugging Face.
Chatversionen er finjusteret og renset, men basismodellen har endnu ikke justeringsværn på plads. TII sagde, at da den endnu ikke havde været igennem en finjusterings- eller tilpasningsproces, kunne den give "problematiske" svar.
Det vil tage noget tid at få det justeret til et punkt, hvor det kan anvendes kommercielt med tillid.
Alligevel fremhæver denne models imponerende ydeevne mulighederne for forbedring ud over blot at skalere computerressourcer.
Falcon 180B viser, at mindre modeller, der er trænet på datasæt af god kvalitet, kan være en mere omkostningseffektiv og effektiv retning for AI-udvikling.
Udgivelsen af denne imponerende model understreger den meteoriske vækst i AI-udvikling i Mellemøstenpå trods af de seneste eksportrestriktioner for GPU'er til regionen.
Mens firmaer som TII og Meta fortsætter med at frigive deres stærke modeller under åbne licenser, bliver det interessant at se, hvad Google og OpenAI gør for at fremme udbredelsen af deres lukkede modeller.
Forskellen i performance mellem open access og proprietære modeller ser bestemt ud til at blive mindre.



