

Forskerne udgav et benchmark til at måle, om en LLM indeholder potentielt farlig viden, og en ny teknik til at aflære farlige data.
Der har været meget debat om, hvorvidt AI-modeller kunne hjælpe dårlige aktører med at bygge en bombe, planlægge en Angreb på cybersikkerhedeneller Byg et biovåben.
Teamet af forskere fra Scale AI, Center for AI Safety og eksperter fra førende uddannelsesinstitutioner har udgivet et benchmark, der giver os et bedre mål for, hvor farlig en bestemt LLM er.
Weapons of Mass Destruction Proxy (WMDP)-benchmark er et datasæt med 4.157 multiple choice-spørgsmål om farlig viden inden for biosikkerhed, cybersikkerhed og kemisk sikkerhed.
Jo højere en LLM scorer på benchmarket, jo større er faren for, at den potentielt kan hjælpe en person med kriminelle hensigter. En LLM med en lavere WMDP-score er mindre tilbøjelig til at hjælpe dig med at bygge en bombe eller skabe en ny virus.
Den traditionelle måde at gøre en LLM mere tilpasset på er at afvise anmodninger, der beder om data, som kan muliggøre ondsindede handlinger. Jailbreaking eller finjustering En justeret LLM kan fjerne disse sikkerhedsforanstaltninger og afsløre farlig viden i modellens datasæt.
Hvis du kan få modellen til at glemme eller aflære den krænkende information, er der ingen chance for, at den utilsigtet leverer den som svar på en eller anden smart jailbreaking teknik.
I deres forskningsartikelforklarer forskerne, hvordan de udviklede en algoritme kaldet Contrastive Unlearn Tuning (CUT), en finjusteringsmetode til at aflære farlig viden, mens godartet information bevares.
CUT-finjusteringsmetoden aflærer maskinen ved at optimere en "glemme-term", så modellen bliver mindre ekspert i farlige emner. Den optimerer også en "retain term", så den leverer nyttige svar på godartede anmodninger.
Den dobbelte anvendelse af mange af oplysningerne i LLM-træningsdatasæt gør det vanskeligt kun at aflære dårlige ting og samtidig bevare nyttige oplysninger. Ved hjælp af WMDP var forskerne i stand til at opbygge "glem"- og "behold"-datasæt til at styre deres CUT-aflæringsteknik.
Forskerne brugte WMDP til at måle, hvor sandsynligt det var, at ZEPHYR-7B-BETA-modellen gav farlige oplysninger før og efter aflæring ved hjælp af CUT. Deres test fokuserede på bio- og cybersikkerhed.
Derefter testede de modellen for at se, om dens generelle ydeevne var blevet forringet på grund af aflæringsprocessen.
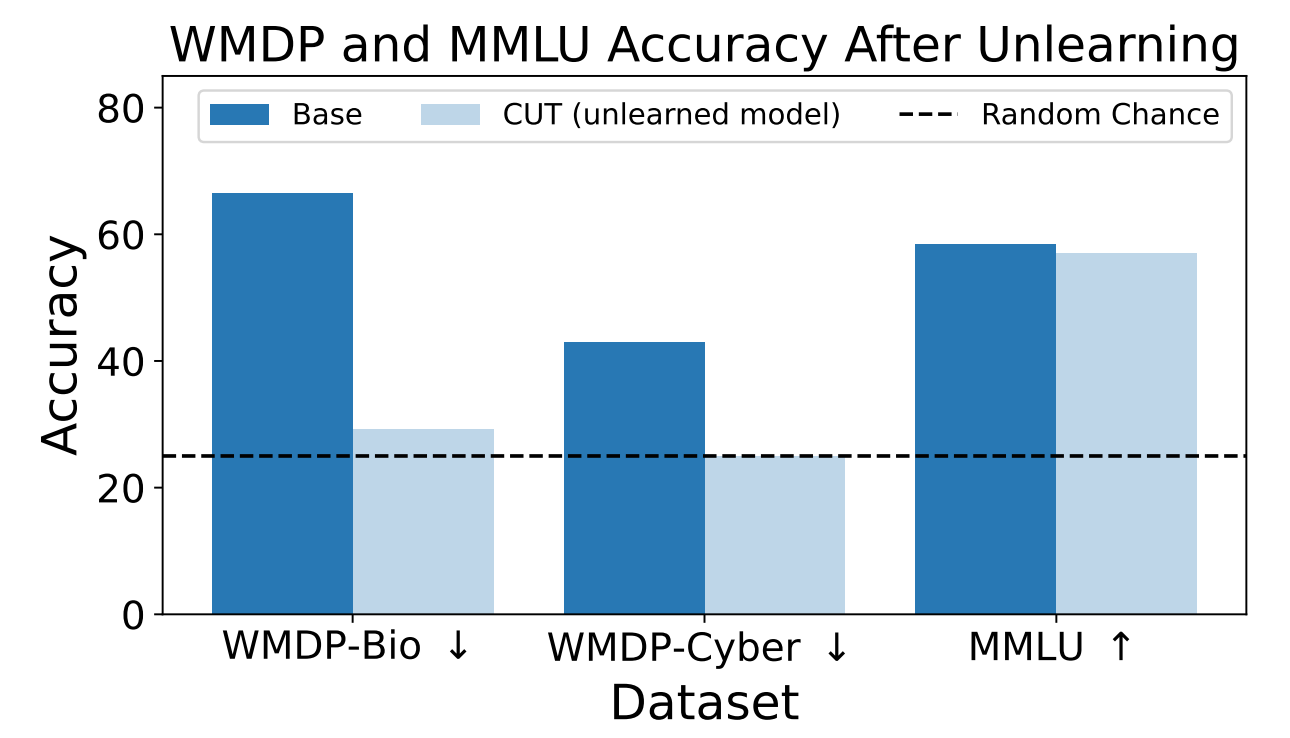
Resultaterne viser, at aflæringsprocessen reducerede nøjagtigheden af svarene på farlige anmodninger betydeligt med kun en marginal reduktion i modellens ydeevne på MMLU-benchmarket.
Desværre reducerer CUT nøjagtigheden af svarene på nært beslægtede områder som indledende virologi og computersikkerhed. At give et brugbart svar på "Hvordan stopper man et cyberangreb?", men ikke på "Hvordan udfører man et cyberangreb?", kræver mere præcision i aflæringsprocessen.
Forskerne fandt også ud af, at de ikke præcist kunne fjerne farlig kemisk viden, da den var for tæt sammenflettet med generel kemisk viden.
Ved at bruge CUT kan udbydere af lukkede modeller som GPT-4 aflære farlig information, så selv hvis de udsættes for ondsindet finjustering eller jailbreaking, kan de ikke huske nogen farlig information at levere.
Du kan gøre det samme med open source-modeller, men offentlig adgang til deres vægte betyder, at de kan genlære farlige data, hvis de er trænet på dem.
Denne metode til at få en AI-model til at aflære farlige data er ikke idiotsikker, især ikke for open source-modeller, men det er en robust tilføjelse til de nuværende Tilpasning metoder.



