

Google har frigivet to modeller fra sin familie af lette, åbne modeller kaldet Gemma.
Mens Googles Gemini-modeller er proprietære eller lukkede modeller, er Gemma-modellerne blevet frigivet som "åbne modeller" og gjort frit tilgængelige for udviklere.
Google frigiver Gemma-modeller i to størrelser, 2B- og 7B-parametre, med prætrænede og instruktionstunede varianter for hver. Google frigiver modelvægtene samt en række værktøjer til udviklere, så de kan tilpasse modellerne til deres behov.
Google siger, at Gemma-modellerne er bygget med den samme teknologi, som driver flagskibsmodellen Gemini. Flere virksomheder har udgivet 7B-modeller i et forsøg på at levere en LLM, der bevarer brugbar funktionalitet, mens den potentielt kører lokalt i stedet for i skyen.
Llama-2-7B og Mistral-7B er bemærkelsesværdige konkurrenter på dette område, men Google siger, at "Gemma overgår betydeligt større modeller på vigtige benchmarks", og tilbød denne benchmark-sammenligning som bevis.
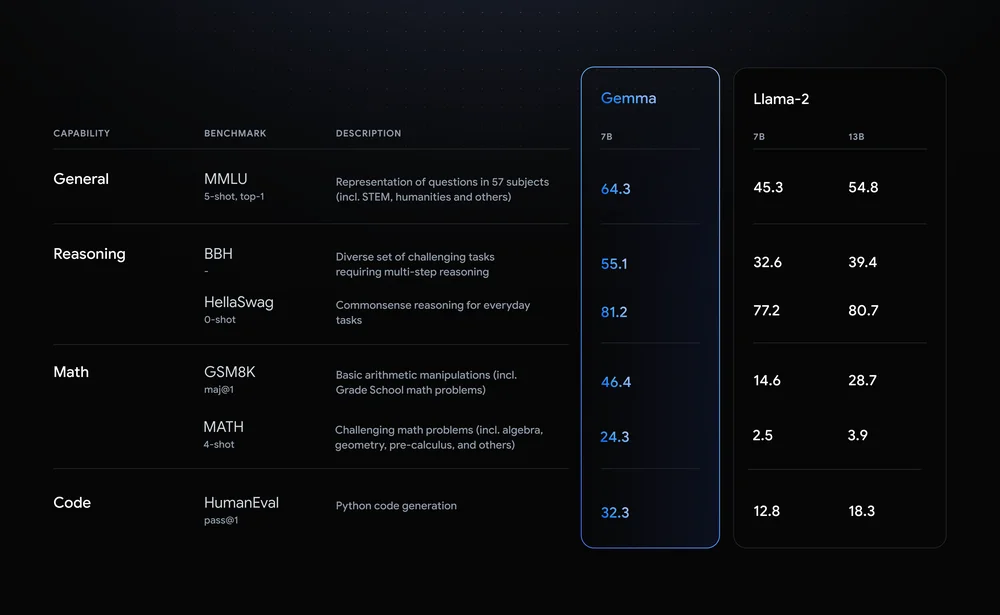
Benchmark-resultaterne viser, at Gemma slår selv den større 12B-version af Llama 2 i alle fire funktioner.
Det virkelig spændende ved Gemma er udsigten til at kunne køre det lokalt. Google har indgået et samarbejde med NVIDIA om at optimere Gemma til NVIDIA GPU'er. Hvis du har en pc med en af NVIDIAs RTX-GPU'er, kan du køre Gemma på din enhed.
NVIDIA siger, at de har en installeret base på over 100 millioner NVIDIA RTX GPU'er. Det gør Gemma til en attraktiv mulighed for udviklere, der forsøger at beslutte, hvilken letvægtsmodel de skal bruge som grundlag for deres produkter.
NVIDIA vil også tilføje understøttelse af Gemma på sin Chat med RTX platform, der gør det nemt at køre LLM'er på RTX-pc'er.
Selv om det teknisk set ikke er open source, er det kun brugsrestriktionerne i licensaftalen, der forhindrer Gemma-modeller i at eje det mærke. Kritikere af åbne modeller peger på de risici, der er forbundet med at holde dem på linje, men Google siger, at de udførte omfattende red-teaming for at sikre, at Gemma var i sikkerhed.
Google siger, at de brugte "omfattende finjustering og forstærkningslæring fra menneskelig feedback (RLHF) til at tilpasse vores instruktionsindstillede modeller til ansvarlig adfærd." De udgav også et Responsible Generative AI Toolkit for at hjælpe udviklere med at holde Gemma på linje efter finjustering.
Tilpassede letvægtsmodeller som Gemma kan give udviklere mere nytte end større modeller som GPT-4 eller Gemini Pro. Muligheden for at køre LLM'er lokalt uden omkostninger til cloud computing eller API-opkald bliver mere tilgængelig hver dag.
Med Gemma åbent tilgængelig for udviklere bliver det interessant at se udvalget af AI-drevne applikationer, der snart kan køre på vores pc'er.



