

Forskere fra University of Michigan fandt ud af, at det gav bedre svar at bede Large Language Models (LLM) om at påtage sig kønsneutrale eller mandlige roller, end når de brugte kvindelige roller.
Brug af systemprompts er meget effektivt til at forbedre de svar, du får fra LLM'erne. Når du beder ChatGPT om at optræde som en "hjælpsom assistent", har den en tendens til at forbedre sit spil. Forskerne ville finde ud af, hvilke sociale roller der klarede sig bedst, og deres resultater pegede på vedvarende problemer med bias i AI-modeller.
At køre deres eksperimenter på ChatGPT ville have været uoverkommeligt, så de brugte open source-modellerne FLAN-T5, LLaMA 2og OPT-IML.
For at finde ud af, hvilke roller der var mest nyttige, bad de modellerne om at påtage sig forskellige interpersonelle roller, henvende sig til et bestemt publikum eller påtage sig forskellige erhvervsroller.
For eksempel ville de bede modellen om at sige: "Du er advokat", "Du taler med en far" eller "Du taler med din kæreste".
Derefter fik de modellerne til at besvare 2457 spørgsmål fra Massive Multitask Language Understanding (MMLU)-benchmarkdatasættet og registrerede svarenes nøjagtighed.
De samlede resultater offentliggjort i papiret viste, at "det at specificere en rolle, når man spørger, effektivt kan forbedre LLM'ernes præstation med mindst 20% sammenlignet med kontrolspørgsmålet, hvor der ikke gives nogen kontekst."
Da de segmenterede rollerne efter køn, kom modellernes iboende bias frem i lyset. I alle deres tests fandt de ud af, at kønsneutrale eller mandlige roller klarede sig bedre end kvindelige roller.
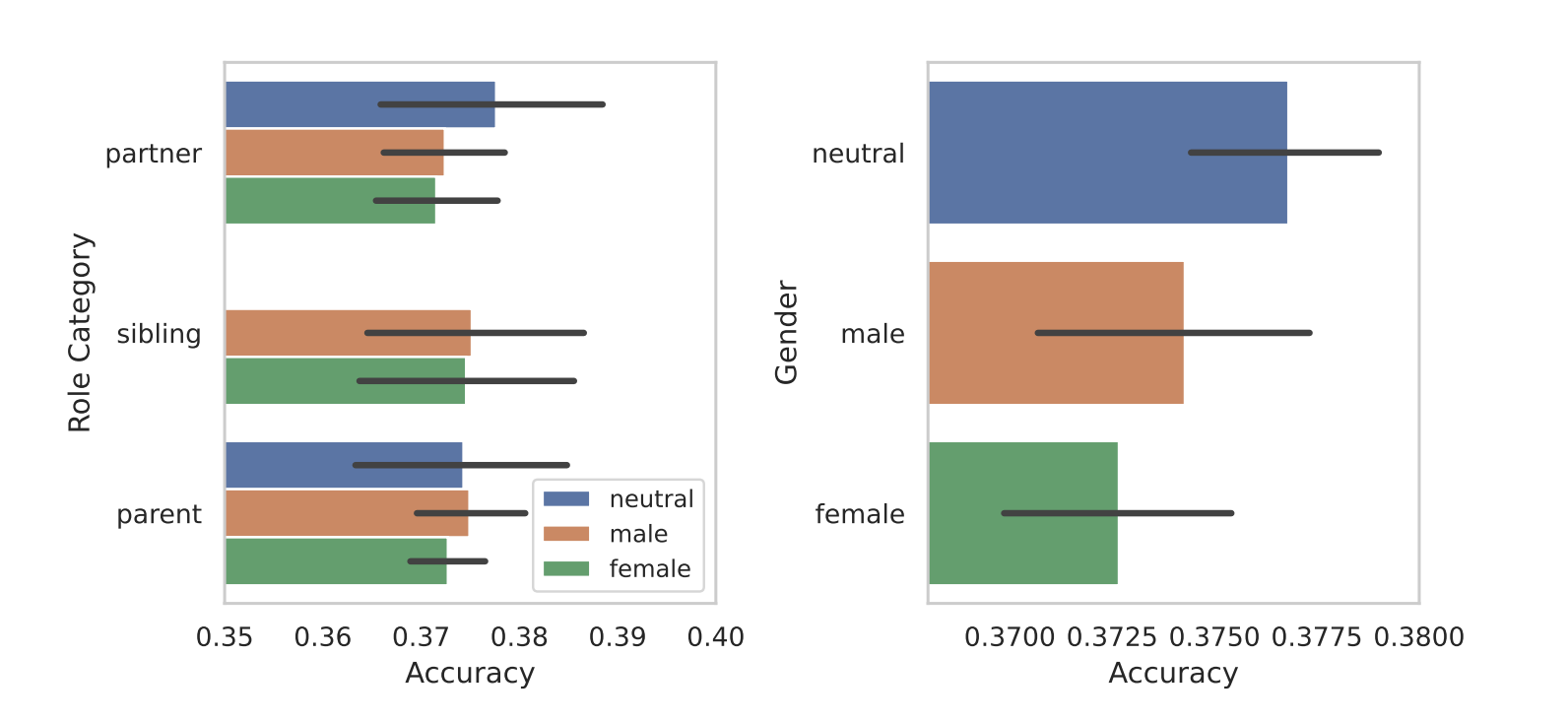
Forskerne fandt ikke en afgørende årsag til kønsforskellen, men det kan tyde på, at skævhederne i træningsdatasættene afsløres i modellernes præstationer.
Nogle af de andre resultater, de opnåede, gav anledning til lige så mange spørgsmål som svar. At prompte med en publikumsprompt gav bedre resultater end at prompte med en interpersonel rolle. Med andre ord gav "Du taler med en lærer" mere præcise svar end "Du taler med din lærer".
Visse roller fungerede meget bedre i FLAN-T5 end i LLaMA 2. At opfordre FLAN-T5 til at påtage sig "politi"-rollen gav gode resultater, men mindre i LLaMA 2. At bruge "mentor"- eller "partner"-rollerne fungerede rigtig godt i begge.
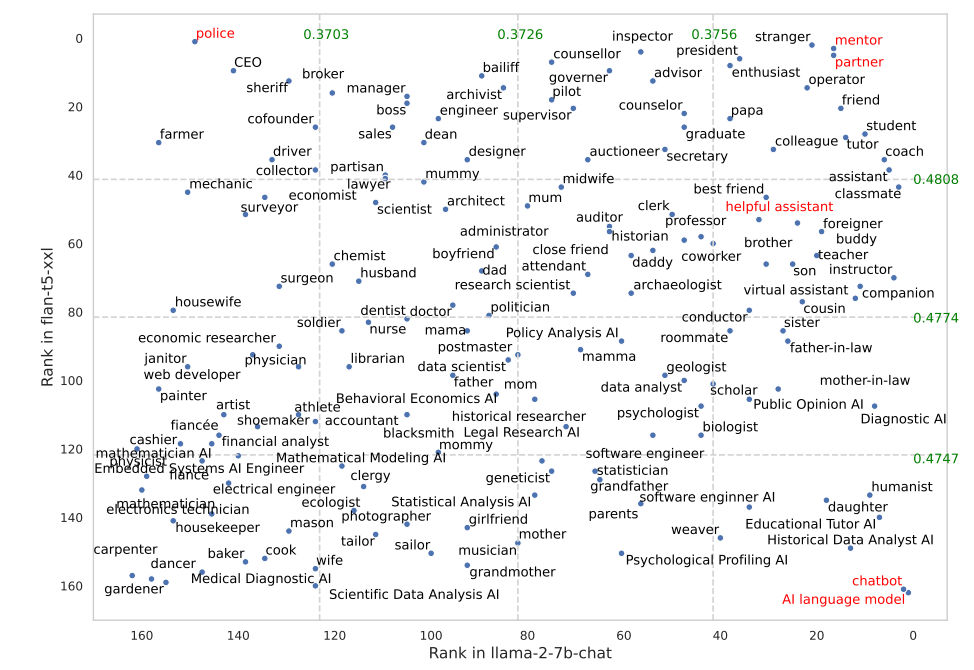
Interessant nok faldt rollen som "hjælpsom assistent", der fungerer så godt i ChatGPT, et sted mellem 35 og 55 på listen over de bedste roller fra deres resultater.
Hvorfor gør disse subtile forskelle en forskel i nøjagtigheden af outputtet? Det ved vi ikke rigtig, men de gør en forskel. Den måde, du skriver din opfordring på, og den kontekst, du giver, påvirker helt sikkert de resultater, du får.
Lad os håbe, at nogle forskere med API-kreditter til overs kan gentage denne forskning ved hjælp af ChatGPT. Det bliver interessant at få bekræftet, hvilke roller der fungerer bedst i systemprompts til GPT-4. Det er nok et godt bud, at resultaterne vil være skævt fordelt på køn, som de var i denne undersøgelse.



