

Store sprogmodeller (LLM) bliver ofte vildledt af bias eller irrelevant kontekst i en prompt. Forskere hos Meta har fundet en tilsyneladende enkel måde at løse det på.
Efterhånden som kontekstvinduerne bliver større, kan de beskeder, vi giver til en LLM, blive længere og mere detaljerede. LLM'er er blevet bedre til at opfange nuancer eller mindre detaljer i vores beskeder, men nogle gange kan det forvirre dem.
Tidlig maskinlæring brugte en "hård opmærksomhed"-tilgang, der udpegede den mest relevante del af et input og kun reagerede på det. Det fungerer fint, når man skal lave en billedtekst til et billede, men dårligt, når man skal oversætte en sætning eller besvare et spørgsmål med flere lag.
De fleste LLM'er bruger nu en "soft attention"-tilgang, som tokeniserer hele beskeden og tildeler vægt til hver enkelt.
Meta foreslår en tilgang kaldet System 2 Opmærksomhed (S2A) for at få det bedste fra begge verdener. S2A bruger en LLM's evne til at behandle naturligt sprog til at tage din forespørgsel og fjerne bias og irrelevante oplysninger, før du går i gang med at udarbejde et svar.
Her er et eksempel.

S2A fjerner oplysningerne om Max, da de er irrelevante for spørgsmålet. S2A regenererer en optimeret prompt, før den begynder at arbejde på den. LLM'er er notorisk dårlige til at matematik så det er en stor hjælp at gøre beskeden mindre forvirrende.
LLM'er er behagelige mennesker og er glade for at være enige med dig, selv når du tager fejl. S2A fjerner enhver bias i en forespørgsel og behandler derefter kun de relevante dele af forespørgslen. Det reducerer det, som AI-forskere kalder "sycophancy", eller en AI-models tilbøjelighed til at kysse røv.

S2A er egentlig bare en systemprompt, der beder LLM'en om at forfine den oprindelige prompt en smule, før den går i gang med at arbejde på den. De resultater, forskerne opnåede med matematiske, faktuelle og lange spørgsmål, var imponerende.
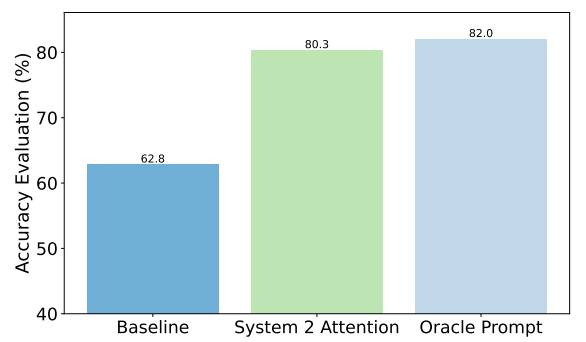
Her er et eksempel på de forbedringer, S2A opnåede på faktuelle spørgsmål. Baseline var svar på spørgsmål, der indeholdt bias, mens Oracle-prompten var en menneskelig raffineret idealprompt.
S2A kommer meget tæt på resultaterne af Oracle-prompten og leverer næsten 50% forbedring i nøjagtighed i forhold til baseline-prompten.
Hvad er så problemet? Forbehandling af den oprindelige forespørgsel, før den besvares, tilføjer yderligere beregningskrav til processen. Hvis spørgsmålet er langt og indeholder mange relevante oplysninger, kan det medføre betydelige omkostninger at genskabe spørgsmålet.
Det er usandsynligt, at brugerne bliver bedre til at skrive velformulerede beskeder, så S2A kan være en god måde at komme uden om det på.
Vil Meta bygge S2A ind i sin Lama model? Vi ved det ikke, men du kan selv udnytte S2A-tilgangen.
Hvis du er omhyggelig med at udelade meninger eller ledende forslag fra dine spørgsmål, er det mere sandsynligt, at du får nøjagtige svar fra disse modeller.



