

Digital kolonialisme refererer til tech-giganters og magtfulde enheders dominans over det digitale landskab, hvor de former strømmen af information, viden og kultur til at tjene deres interesser.
Denne dominans handler ikke kun om at kontrollere den digitale infrastruktur, men også om at påvirke de fortællinger og vidensstrukturer, der definerer vores digitale tidsalder.
Digital kolonialisme og nu AI-kolonialisme er bredt anerkendte begreber, og institutioner som f.eks. MIT har forsket i og skrevet om dem i stor udstrækning.
Topforskere fra Anthropic, Google, DeepMind og andre teknologivirksomheder har åbent diskuteret AI's begrænsede muligheder for at betjene mennesker med forskellige baggrunde, især med henvisning til skævhed i maskinlæringssystemer.
Maskinlæringssystemer fogamentalt afspejler de data, de er trænet på - data, der kankan ses som et produkt af vores digitale tidsånd - en samling af fremherskende fortællinger, billeder og ideer, som dominerer onlineverdenen.
Men hvem får lov til at forme disse informationskræfter? Hvis stemmer bliver forstærket, og hvis bliver dæmpet?
Når AI lærer af træningsdata, arver den specifikke verdensbilleder, som ikke nødvendigvis stemmer overens med eller repræsenterer globale kulturer og erfaringer. Desuden er de kontroller, der styrer output fra generative AI-værktøjer, formet af underliggende sociokulturelle vektorer.
Det har fået udviklere som Anthropic til at søge demokratiske metoder at forme AI-adfærd ved hjælp af offentlige synspunkter.
Som Jack Clark, Anthropics politiske chef, beskrev en nyt eksperiment fra sin virksomhed: "Vi prøver at finde en måde at udvikle en forfatning på, som er udviklet af en hel masse tredjeparter i stedet for af folk, der tilfældigvis arbejder på et laboratorium i San Francisco."
De nuværende generative AI-træningsparadigmer risikerer at skabe et digitalt ekkokammer, hvor de samme ideer, værdier og perspektiver hele tiden forstærkes og yderligere befæster dominansen hos dem, der allerede er overrepræsenteret i dataene.
Efterhånden som AI integreres i kompleks beslutningstagning, fra social velfærd og Rekruttering til økonomiske beslutninger og medicinske diagnoserfører den skæve repræsentation til fordomme og uretfærdigheder i den virkelige verden.
Datasættene er geografisk og kulturelt placeret
En nylig undersøgelse af Data Provenance Initiative undersøgte 1.800 populære datasæt beregnet til naturlig sprogbehandling (NLP), en disciplin inden for AI, der fokuserer på sprog og tekst.
NLP er den dominerende maskinlæringsmetode bag store sprogmodeller (LLM'er), herunder ChatGPT og Metas Llama-modeller.
Undersøgelsen afslører en vestlig-centreret skævhed i sprogrepræsentationen på tværs af datasæt, hvor engelsk og vesteuropæiske sprog definerer tekstdata.
Sprog fra asiatiske, afrikanske og sydamerikanske lande er markant underrepræsenteret.
Derfor kan LLM'er ikke gøre sig håb om præcist at repræsentere de kulturelle og sproglige nuancer i disse regioner i samme grad som vestlige sprog.
Selv når sprog fra det globale syd ser ud til at være repræsenteret, stammer sprogets kilde og dialekt primært fra nordamerikanske eller europæiske skabere og webkilder.

A tidligere Antropisk eksperiment fandt ud af, at det at skifte sprog i modeller som ChatGPT stadig gav vestligt centrerede synspunkter og stereotyper i samtaler.
Antropiske forskere konkluderede: "Hvis en sprogmodel i uforholdsmæssig grad repræsenterer visse meninger, risikerer den at få potentielt uønskede virkninger, såsom at fremme hegemoniske verdensbilleder og homogenisere folks perspektiver og overbevisninger."
Data Provenance-undersøgelsen dissekerede også det geografiske landskab for kuratering af datasæt. Akademiske organisationer fremstår som de primære drivkræfter, idet de bidrager til 69% af datasættene, efterfulgt af industrilaboratorier (21%) og forskningsinstitutioner (17%).
De største bidragydere er især AI2 (12,3%), University of Washington (8,9%) og Facebook AI Research (8,4%).
A separat 2020-undersøgelse fremhæver, at halvdelen af de datasæt, der blev brugt til AI-evaluering på tværs af ca. 26.000 forskningsartikler, stammede fra så få som 12 topuniversiteter og teknologivirksomheder.
Igen viste det sig, at geografiske områder som Afrika, Syd- og Mellemamerika og Centralasien var sørgeligt underrepræsenterede, som det ses nedenfor.
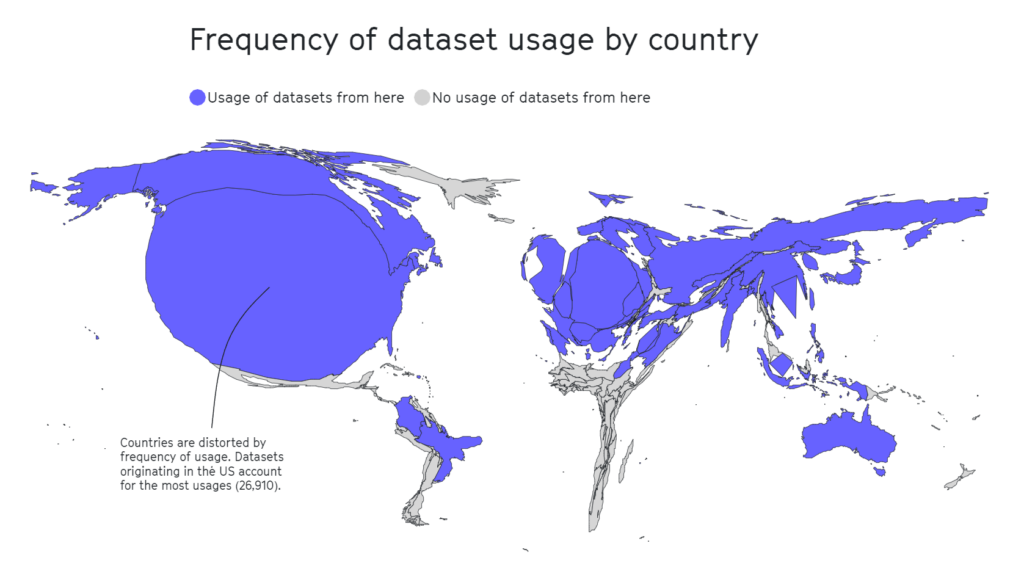
I anden forskning har indflydelsesrige datasæt som MIT's Tiny Images eller Labeled Faces in the Wild primært indeholdt billeder af hvide vestlige mænd, med omkring 77,5% mænd og 83,5% hvidhudede personer i tilfældet med Labeled Faces in the Wild.
I tilfældet med Tiny Images er en 2020-analyse af The Register fandt, at mange Tiny Images indeholdt uanstændige, racistiske og sexistiske etiketter.
Antonio Torralba fra MIT sagde, at de ikke var opmærksomme på mærkerne, og at datasættet blev slettet. Torralba sagde: "Det er klart, at vi burde have screenet dem manuelt."
Engelsk dominerer AI-økosystemet
Pascale Fung, datalog og direktør for Center for AI Research ved Hong Kong University of Science and Technology, diskuterede de problemer, der er forbundet med hegemonisk AI.
Fung henviser til over 15 forskningsartikler, der undersøger LLM'ers flersprogede færdigheder og konsekvent finder dem mangelfulde, især når de oversætter engelsk til andre sprog. For eksempel afslører sprog med ikke-latinske skrifttegn, som koreansk, LLM'ernes begrænsninger.
Ud over dårlig støtte til flere sprog, andre undersøgelser tyder på, at de fleste bias-benchmarks og -målinger er udviklet med engelsksprogede modeller i tankerne.
Der er langt mellem benchmarks for ikke-engelsk bias, hvilket fører til et betydeligt hul i vores evne til at vurdere og rette op på bias i flersprogede sprogmodeller.
Der er tegn på forbedringer, f.eks. Googles indsats med sprogmodellen PaLM 2 og Meta's Massivt flersproget tale (MMS) der kan identificere mere end 4.000 talte sprog, 40 gange mere end andre tilgange. MMS er dog stadig et eksperiment.
Forskere skaber forskellige, flersprogede datasæt, men den overvældende mængde engelske tekstdata, som ofte er gratis og let tilgængelige, gør dem til de facto-valget for udviklere.
Ud over data: strukturelle spørgsmål i AI-arbejde
MIT's store gennemgang af AI-kolonialisme henledte opmærksomheden på et relativt skjult aspekt af AI-udvikling - udnyttende arbejdspraksis.
AI har udløst en voldsom stigning i efterspørgslen efter datamærkningstjenester. Virksomheder som Appen og Sama er dukket op som nøglespillere og tilbyder tjenester til mærkning af tekst, billeder og videoer, sortering af fotos og transskribering af lyd for at fodre maskinlæringsmodeller.
Menneskelige dataspecialister mærker også indholdstyper manuelt, ofte for at sortere data, der indeholder ulovligt, illegalt eller uetisk indhold, såsom beskrivelser af seksuelt misbrug, skadelig adfærd eller andre ulovlige aktiviteter.
Selvom AI-virksomheder automatiserer nogle af disse processer, er det stadig vigtigt at holde "mennesker i gang" for at sikre, at modellerne er nøjagtige, og at sikkerheden overholdes.
Markedsværdien af dette "spøgelsesarbejde", som antropologen Mary Gray og samfundsforskeren Siddharth Suri kalder det, anslås til at være skyder i vejret til $13,7 milliarder i 2030.
Spøgelsesarbejde indebærer ofte udnyttelse af billig arbejdskraft, især fra økonomisk sårbare lande. Venezuela er for eksempel blevet en primær kilde til AI-relateret arbejdskraft på grund af landets økonomiske krise.
Da landet kæmpede med sin værste økonomiske katastrofe i fredstid og en astronomisk inflation, vendte en betydelig del af den veluddannede og internetforbundne befolkning sig mod crowd-working-platforme som et middel til at overleve.
Sammenfaldet af en veluddannet arbejdsstyrke og økonomisk desperation gjorde Venezuela til et attraktivt marked for datamærkningsvirksomheder.
Det er ikke en kontroversiel pointe - når MIT udgiver artikler med titler som "Kunstig intelligens skaber en ny kolonial verdensordenMed henvisning til scenarier som dette er det tydeligt, at nogle i branchen forsøger at trække tæppet væk under denne underhåndspraksis.
Som MIT rapporterer, har den spirende AI-industri været et tveægget sværd for mange venezuelanere. Mens den gav en økonomisk livline midt i desperationen, udsatte den også folk for udnyttelse.
Julian Posada, som er ph.d.-studerende ved University of Toronto, fremhæver den "enorme magtubalance" i disse arbejdsordninger. Platformene dikterer reglerne og efterlader arbejderne med ringe indflydelse og begrænset økonomisk kompensation på trods af udfordringer på jobbet som f.eks. eksponering for forstyrrende indhold.
Denne dynamik minder i uhyggelig grad om historisk kolonipraksis, hvor imperier udnyttede arbejdskraften i sårbare lande, hentede profit og forlod dem, når muligheden svandt ind, ofte fordi "bedre værdi" var tilgængelig andre steder.
Lignende situationer er blevet observeret i Nairobi, Kenya, hvor en gruppe tidligere indholdsmoderatorer, der arbejdede på ChatGPT indgav en begæring med den kenyanske regering.
De påstod, at de blev "udnyttet" under deres ansættelse hos Sama, en amerikansk baseret virksomhed, der leverer dataannotationstjenester, og som OpenAI har indgået kontrakt med. Andragerne hævdede, at de blev udsat for foruroligende indhold uden tilstrækkelig psykosocial støtte, hvilket førte til alvorlige psykiske problemer, herunder PTSD, depression og angst.

Dokumenter anmeldt af TIME viste, at OpenAI havde underskrevet kontrakter med Sama til en værdi af omkring $200.000. Disse kontrakter involverede mærkning af beskrivelser af seksuelt misbrug, hadefuld tale og vold.
Indvirkningen på arbejdernes mentale sundhed var dybtgående. Mophat Okinyi, en tidligere moderator, talte om de psykologiske omkostninger og beskrev, hvordan eksponering for grafisk indhold førte til paranoia, isolation og betydelige personlige tab.
Lønnen for så belastende arbejde var chokerende lav - en talsmand for Sama oplyste, at arbejderne tjente mellem $1,46 og $3,74 i timen.
Modstand mod digital kolonialisme
Hvis AI-industrien er blevet en ny grænse for digital kolonialisme, så er modstanden allerede ved at blive mere sammenhængende.
Aktivister, ofte med støtte fra AI-forskere, kæmper for ansvarlighed, politiske ændringer og udvikling af teknologier, der prioriterer lokalsamfundenes behov og rettigheder.
Nanjala Nyabola's Kiswahili Digital Rights Project er et innovativt eksempel på, hvordan lokale græsrodsprojekter kan installere den infrastruktur, der er nødvendig for at beskytte lokalsamfund mod digitalt hegemoni.
Projektet tager højde for de vestlige reglers hegemoni, når en gruppes digitale rettigheder skal defineres, da ikke alle er beskyttet af de love om intellektuel ejendomsret, ophavsret og privatlivets fred, som mange af os tager for givet. Det betyder, at en stor del af verdens befolkning kan blive udnyttet af teknologivirksomheder.
I erkendelse af, at diskussioner om digitale rettigheder bliver afstumpede, hvis folk ikke kan kommunikere på deres modersmål, oversatte Nyabola og hendes team nøglebegreber om digitale rettigheder og teknologi til kiswahili, som primært tales i Tanzania, Kenya og Mozambique.
Nyabola beskrevet af projektet"I løbet af processen [med Huduma Namba-initiativet] havde vi ikke rigtig sproget og værktøjerne til at forklare ikke-specialister eller ikke-engelsktalende samfund i Kenya, hvad initiativets konsekvenser var."
I et lignende græsrodsprojekt havde Te Hiku Media, en non-profit radiostation, der primært sender på maori-sproget, en stor database med optagelser, der strakte sig over årtier, og hvoraf mange gengav stemmerne fra forfædrenes sætninger, der ikke længere blev talt.
Almindelige talegenkendelsesmodeller, der ligner LLM'er, har en tendens til at levere for lidt, når de bliver bedt om at tale forskellige sprog eller engelske dialekter.
Den Te Hiku Media samarbejdede med forskere og open source-teknologier om at træne en talegenkendelsesmodel, der var skræddersyet til māori-sproget. Māori-aktivisten Te Mihinga Komene bidrog med omkring 4.000 sætninger til de utallige andre, der deltog i projektet.
Den resulterende model og data er beskyttet under Kaitiakitanga Licens - Kaitiakitanga er et Māori-ord uden en specifik engelsk definition, men det svarer til "værge" eller "vogter".
Keoni Mahelona, en af medstifterne af Te Hiku Media, bemærkede gribende: "Data er koloniseringens sidste grænse."
Disse projekter har inspireret andre oprindelige og indfødte samfund, der er under pres fra digital kolonialisme og andre former for social omvæltning, f.eks. mohawk-folket i Nordamerika og indfødte hawaiianere.
Efterhånden som open source AI bliver billigere og lettere at få adgang til, bør det blive enklere at gentage og finjustere modeller ved hjælp af unikke lokaliserede datasæt, hvilket forbedrer den tværkulturelle adgang til teknologien.
Selv om AI-industrien stadig er ung, er tiden inde til at bringe disse udfordringer frem i lyset, så folk i fællesskab kan udvikle løsninger.
Løsninger kan både være på makroniveau i form af regler, politikker og maskinlæringsmetoder og på mikroniveau i form af lokale projekter og græsrodsprojekter.
Sammen kan forskere, aktivister og lokalsamfund finde metoder til at sikre, at AI kommer alle til gode.



