

HyperWrite founder and CEO Matt Shumer announced that his new model, Reflection 70B, uses a simple trick to solve LLM hallucinations and delivers impressive benchmark results that beat larger and even closed models like GPT-4o.
Shumer collaborated with synthetic data provider, Glaive, to create the new model which is based on Meta’s Llama 3.1-70B Instruct model.
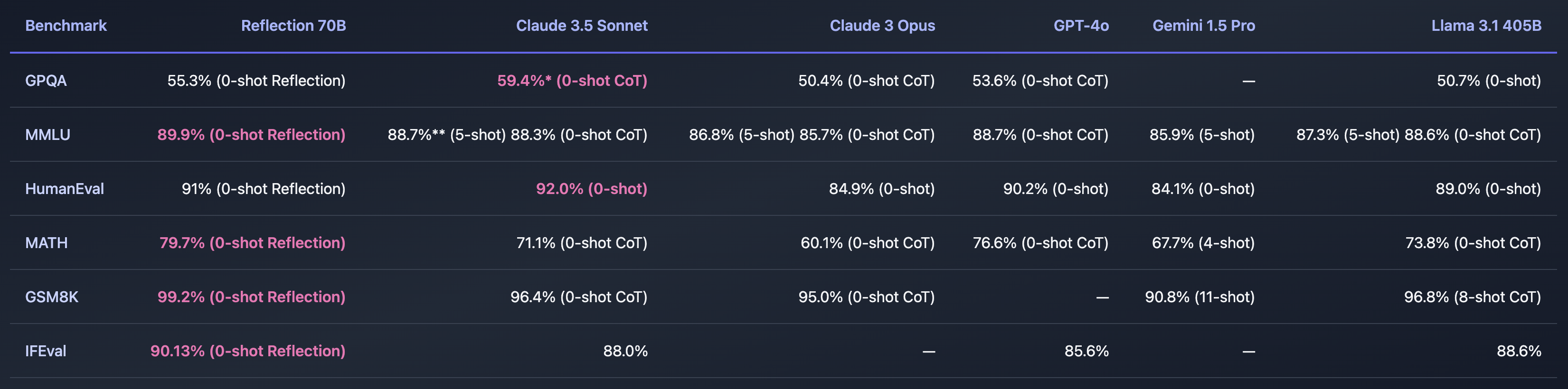
In the launch announcement on Hugging Face, Shumer said. “Reflection Llama-3.1 70B is (currently) the world’s top open-source LLM, trained with a new technique called Reflection-Tuning that teaches a LLM to detect mistakes in its reasoning and correct course.”
If Shumer found a way to solve the issue of AI hallucinations then that would be incredible. The benchmarks he shared seem to indicate that Reflection 70B is way ahead of other models.
The model’s name is a reference to its ability to self-correct during inference. Shumer doesn’t give too much away but explains that the model reflects on its initial answer to a prompt and only outputs it once satisfied that it is correct.
Shumer says that a 405B version of Reflection is in the works and will blow other models, including GPT-4o, away when it is unveiled next week.
Is Reflection 70B a scam?
Is this all too good to be true? Reflection 70B is available for download on Huging Face but early testers weren’t able to duplicate the impressive performance Shumer’s benchmarks showed.
The Reflection playground let’s you try the model out but says that due to high demand the demo is temporarily down. The “Count ‘r’s in strawberry” and “9.11 vs 9.9” prompt suggestions hint that the model gets these tricky prompts right. But some users claim Reflection has been tuned specifically to answer these prompts.
Some users questioned the impressive benchmarks. The GSM8K of over 99% looked especially suspect.
Hey Matt! This is super interesting, but I’m quite surprised to see a GSM8k score of over 99%. My understanding is that it’s likely that more than 1% of GSM8k is mislabeled (the correct answer is actually wrong)!
— Hugh Zhang (@hughbzhang) September 5, 2024
Some of the ground truth answers in the GSM8K dataset are actually wrong. In other words, the only way to score over 99% on the GSM8K was to provide the same incorrect answers to those problems.
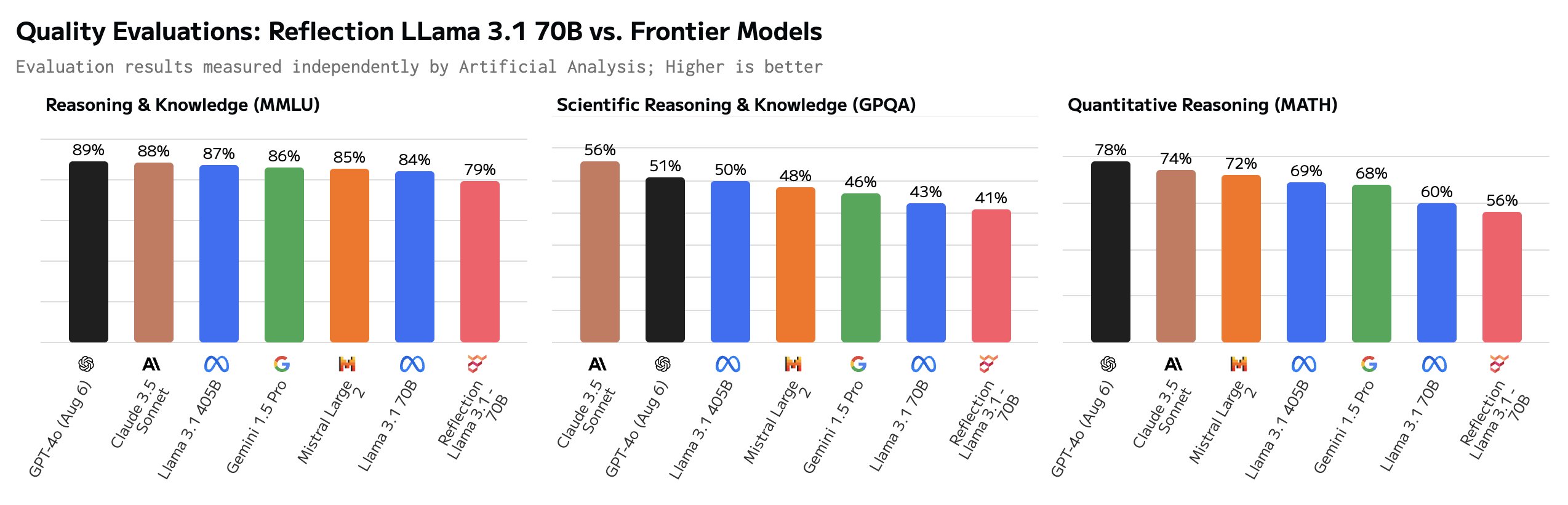
After some testing, users say that Reflection is actually worse than Llama 3.1 and that it was actually just Llama 3 with LoRA tuning applied.
In response to the negative feedback, Shumer posted an explanation on X saying, “Quick update — we re-uploaded the weights but there’s still an issue. We just started training over again to eliminate any possible issue. Should be done soon.”
Shumer explained that there was a glitch with the API and that they were working on it. In the meanwhile, he provided access to a secret, private API so that doubters could try Reflection out while they worked on the fix.
And that’s where the wheels seem to come off, as some careful prompting seems to show the API is really just a Claude 3.5 Sonnet wrapper.
“Reflection API” is a sonnet 3.5 wrapper with prompt. And they are currently disguising it by filtering out the string ‘claude’.https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
— Joseph (@RealJosephus) September 8, 2024
Subsequent testing reportedly had the API returning outputs from Llama and GPT-4o. Shumer insists the original results are accurate and that they’re working on fixing the downloadable model.
Are the skeptics a little premature in calling Shumer a grifter? Maybe the release was just poorly handled and Reflection 70B really is a groundbreaking open-source model. Or maybe it’s another example of AI hype to raise venture capital from investors looking for the next big thing in AI.
We’ll have to wait a day or two to see how this plays out.



