
Meta has released its upgraded Llama 3.1 models in 8B, 70B, and 405B versions and committed to Mark Zuckerberg’s open source vision for the future of AI.
The new additions to Meta’s Llama family of models come with an expanded context length of 128k and support across eight languages.
Meta says its highly anticipated 405B model demonstrates “unmatched flexibility, control, and state-of-the-art capabilities that rival the best closed source models.” It also claims that Llama 3.1 405B is the “the world’s largest and most capable openly available foundation model.”
With eye-watering computing costs being spent to train ever-larger models, there was a lot of speculation that Meta’s flagship 405B model could be its first paid model.
Llama 3.1 405B was trained on over 15 trillion tokens using 16,000 NVIDIA H100s, likely costing hundreds of millions of dollars.
In a blog post, Meta CEO Mark Zuckerberg reaffirmed the company’s view that open source AI is the way forward and that the release of Llama 3.1 is the next step “towards open source AI becoming the industry standard.”
The Llama 3.1 models are free to download and modify or fine-tune with a suite of services from Amazon, Databricks, and NVIDIA.
The models are also available on cloud service providers including AWS, Azure, Google, Oracle.
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet.
Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context… pic.twitter.com/1iKpBJuReD
— AI at Meta (@AIatMeta) July 23, 2024
Performance
Meta says it tested its models on over 150 benchmark datasets and released results for the more common benchmarks to show how its new models stack up against other leading models.
There’s not a lot separating Llama 3.1 405B from GPT-4o and Claude 3.5 Sonnet. Here are the figures for the 405B model and then the smaller 8B and 70B versions.
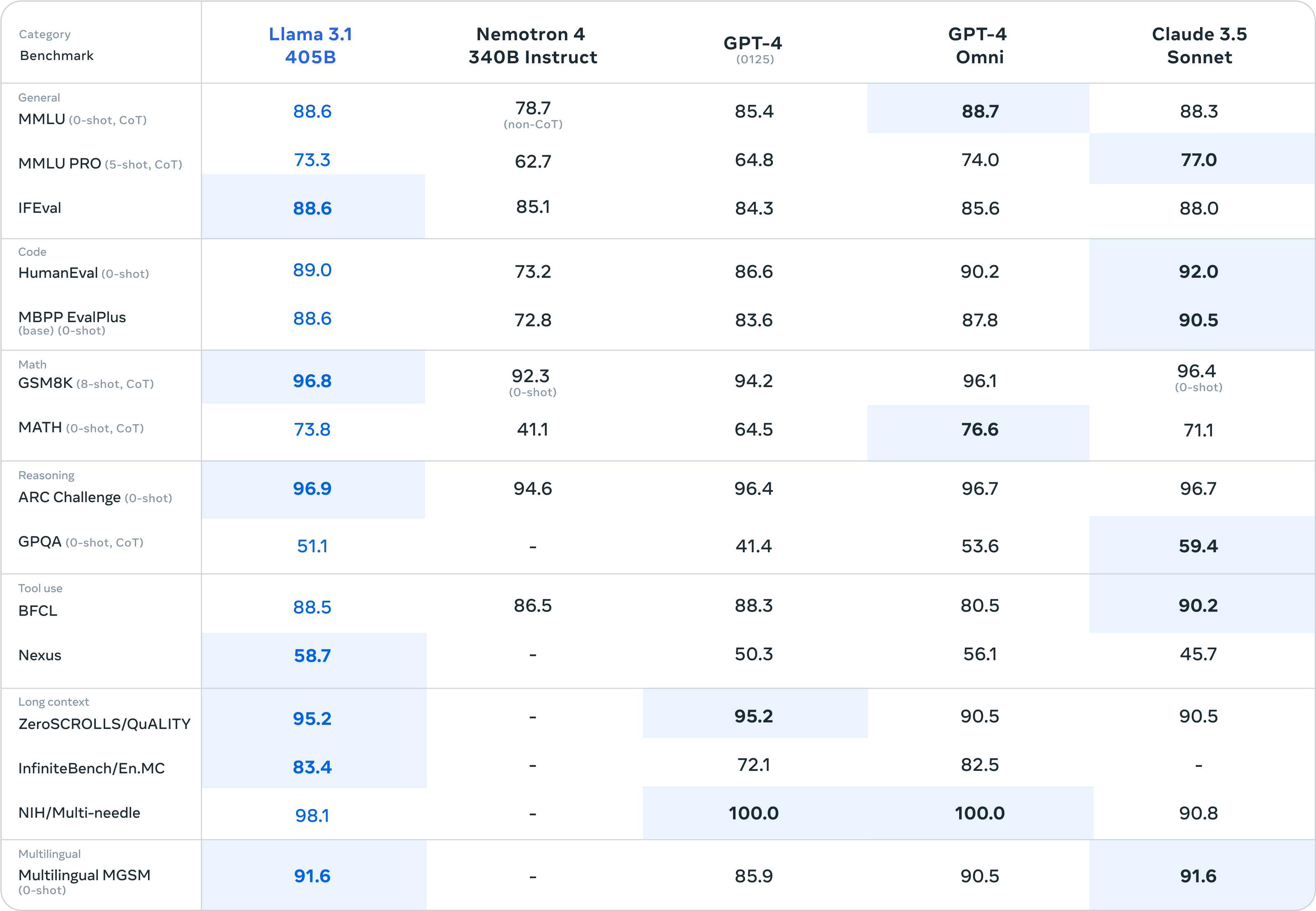
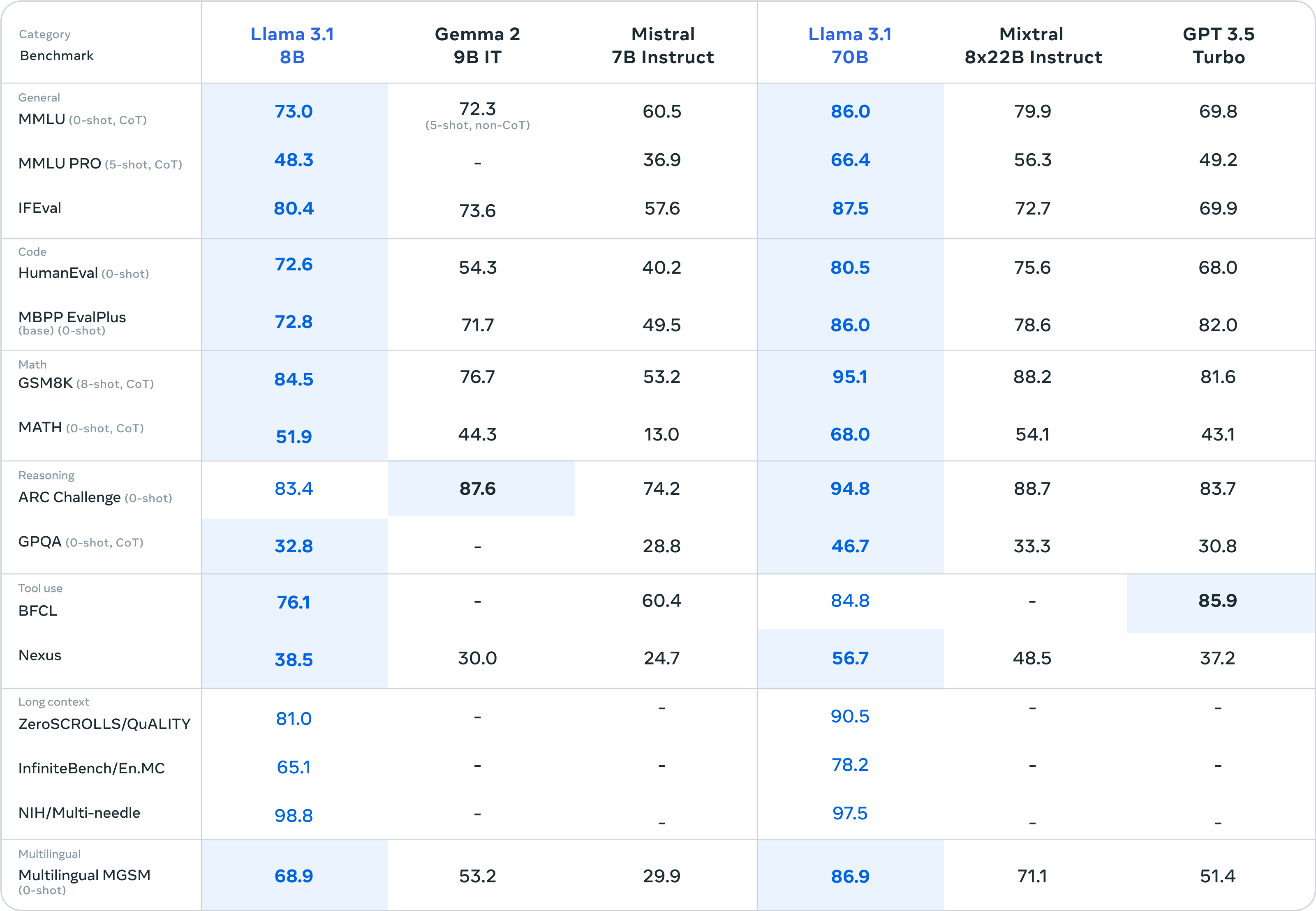
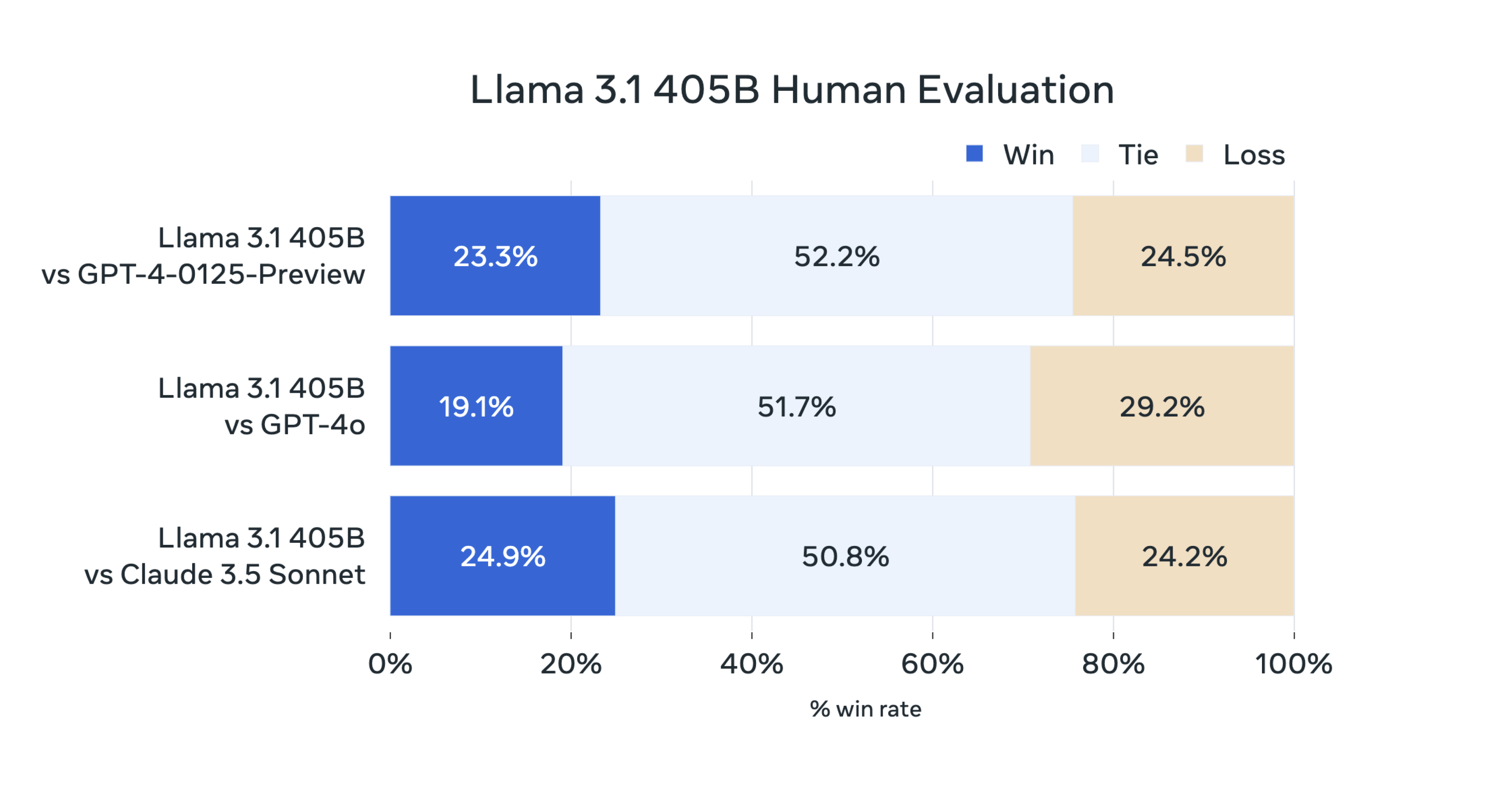
Meta also performed “extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios.”
These figures rely on users to decide whether they prefer the response from one model or another.
The human evaluation of Llama 3.1 405B reflects similar parity that the benchmark figures reveal.
Meta says its model is truly open as Llama 3.1 model weights are also available to download, although the training data has not been shared. The company also amended its license to allow Llama models to be used to improve other AI models.
The freedom to fine-tune, modify, and use Llama models without restrictions will have critics of open source AI ring alarm bells.
Zuckerberg argues that an open source approach is the best way to avoid unintended harm. If an AI model is open to scrutiny, he says it’s less likely to develop dangerous emergent behavior that we would otherwise miss in closed models.
When it comes to the potential for intentional harm Zuckerberg says, “As long as everyone has access to similar generations of models – which open source promotes – then governments and institutions with more compute resources will be able to check bad actors with less compute.”
Addressing the risk of state adversaries like China accessing Meta’s models Zuckerberg says that efforts to keep these out of Chinese hands aren’t going to work.
“Our adversaries are great at espionage, stealing models that fit on a thumb drive is relatively easy, and most tech companies are far from operating in a way that would make this more difficult,” he explained.
The excitement over an open source AI model like Llama 3.1 405B taking on the big closed models is justified.
But with whispers of GPT-5 and Claude 3.5 Opus waiting in the wings, these benchmark results might not age very well.



