

Google DeepMind researchers developed NATURAL PLAN, a benchmark for evaluating the capability of LLMs to plan real-world tasks based on natural language prompts.
The next evolution of AI is to have it leave the confines of a chat platform and take on agentic roles to complete tasks across platforms on our behalf. But that’s harder than it sounds.
Planning tasks like scheduling a meeting or compiling a holiday itinerary might seem simple for us. Humans are good at reasoning through multiple steps and predicting whether a course of action will accomplish the desired objective or not.
You might find that easy, but even the best AI models struggle with planning. Could we benchmark them to see which LLM is best at planning?
The NATURAL PLAN benchmark tests LLMs on 3 planning tasks:
- Trip planning – Planning a trip itinerary under flight and destination constraints
- Meeting planning – Scheduling meetings with multiple friends in different locations
- Calendar scheduling – Scheduling work meetings between multiple people given existing schedules and various constraints
The experiment began with few-shot prompting where the models were provided with 5 examples of prompts and corresponding correct answers. They were then prompted with planning prompts of varying difficulty.
Here’s an example of a prompt and solution provided as an example to the models:

Results
The researchers tested GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, and Gemini 1.5 Pro, none of which performed very well on these tests.
The results must have gone down well in the DeepMind office though as Gemini 1.5 Pro came out on top.

As expected, the results got exponentially worse with more complex prompts where the number of people or cities was increased. For example, look at how quickly the accuracy suffered as more people were added to the meeting planning test.
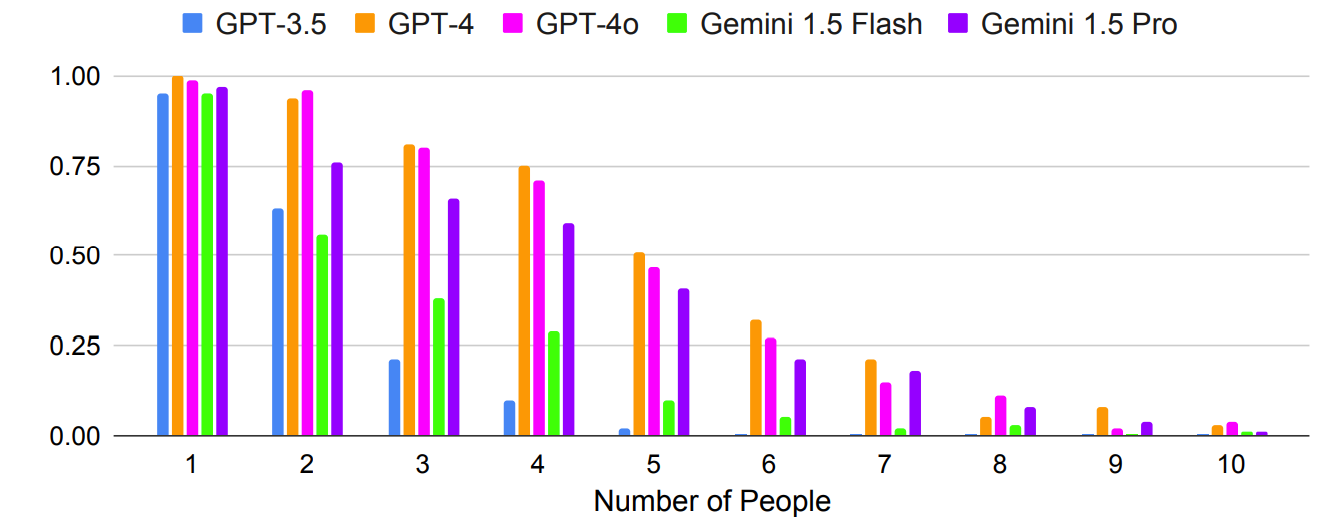
Could multi-shot prompting result in improved accuracy? The results of the research indicate that it can, but only if the model has a large enough context window.
Gemini 1.5 Pro’s larger context window enables it to leverage more in-context examples than the GPT models.
The researchers found that in Trip Planning, increasing the number of shots from 1 to 800 improves the accuracy of Gemini Pro 1.5 from 2.7% to 39.9%.
The paper noted, “These results show the promise of in-context planning where the long-context capabilities enable LLMs to leverage further context to improve Planning.”
A strange result was that GPT-4o was really bad at Trip Planning. The researchers found that it struggled “to understand and respect the flight connectivity and travel date constraints.”
Another strange outcome was that self-correction led to a significant model performance drop across all models. When the models were prompted to check their work and make corrections they made more mistakes.
Interestingly, the stronger models, such as GPT-4 and Gemini 1.5 Pro, suffered bigger losses than GPT-3.5 when self-correcting.
Agentic AI is an exciting prospect and we’re already seeing some practical use cases in Microsoft Copilot agents.
But the results of the NATURAL PLAN benchmark tests show that we’ve got some way to go before AI can handle more complex planning.
The DeepMind researchers concluded that “NATURAL PLAN is very hard for state-of-the-art models to solve.”
It seems AI won’t be replacing travel agents and personal assistants quite yet.



