

Microsoft launched Phi-3 Mini, a tiny language model that is part of the company’s strategy to develop lightweight, function-specific AI models.
The progression of language models has seen ever larger parameters, training datasets, and context windows. Scaling the size of these models delivered more powerful capabilities but at a cost.
The traditional approach to training an LLM is to have it consume massive amounts of data which requires huge computing resources. Training an LLM like GPT-4, for example, is estimated to have taken around 3 months and to have cost over $21m.
GPT-4 is a great solution for tasks that require complex reasoning but overkill for simpler tasks like content creation or a sales chatbot. It’s like using a Swiss Army knife when all you need is a simple letter opener.
At only 3.8B parameters, Phi-3 Mini is tiny. Still, Microsoft says it is an ideal lightweight, low-cost solution for tasks like summarizing a document, extracting insights from reports, and writing product descriptions or social media posts.
The MMLU benchmark figures show Phi-3 Mini and the yet-to-be-released larger Phi models beating larger models like Mistral 7B and Gemma 7B.
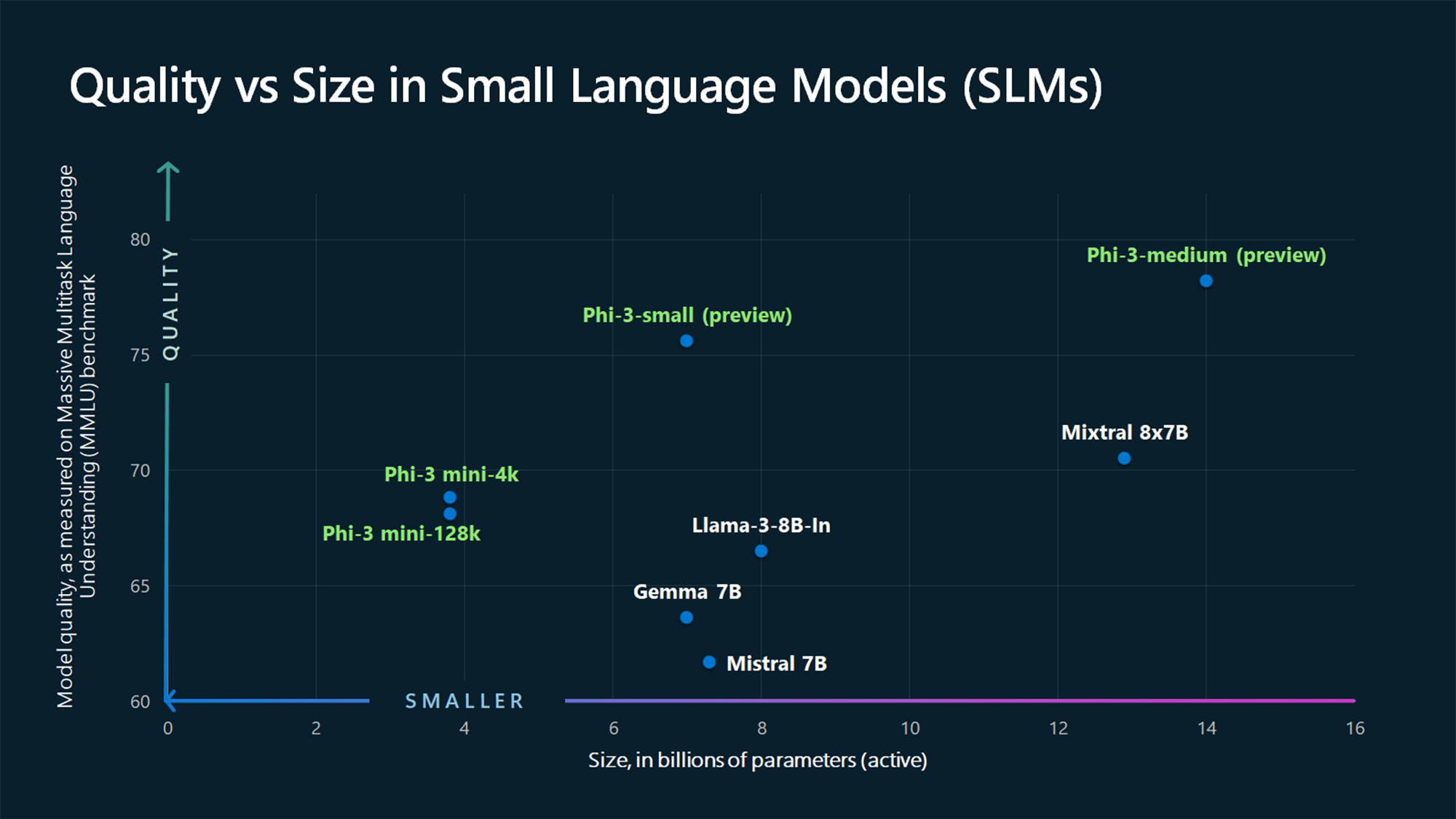
Microsoft says Phi-3-small (7B parameters) and Phi-3-medium (14B parameters) will be available in the Azure AI Model Catalog “shortly”.
Larger models like GPT-4 are still the gold standard and we can probably expect that GPT-5 will be even bigger.
SLMs like Phi-3 Mini offer some important benefits that larger models don’t. SLMs are cheaper to fine-tune, require less compute, and could run on-device even in situations where no internet access is available.
Deploying an SLM at the edge results in less latency and maximum privacy because there’s no need to send data back and forth to the cloud.
Here’s Sebastien Bubeck, VP of GenAI research at Microsoft AI with a demo of Phi-3 Mini. It’s super fast and impressive for such a small model.
phi-3 is here, and it’s … good :-).
I made a quick short demo to give you a feel of what phi-3-mini (3.8B) can do. Stay tuned for the open weights release and more announcements tomorrow morning!
(And ofc this wouldn’t be complete without the usual table of benchmarks!) pic.twitter.com/AWA7Km59rp
— Sebastien Bubeck (@SebastienBubeck) April 23, 2024
Curated synthetic data
Phi-3 Mini is a result of discarding the idea that huge amounts of data are the only way to train a model.
Sebastien Bubeck, Microsoft vice president of generative AI research asked “Instead of training on just raw web data, why don’t you look for data which is of extremely high quality?”
Microsoft Research machine learning expert Ronen Eldan was reading bedtime stories to his daughter when he wondered if a language model could learn using only words a 4-year-old could understand.
This led to an experiment where they created a dataset starting with 3,000 words. Using only this limited vocabulary they prompted an LLM to create millions of short children’s stories which were compiled into a dataset called TinyStories.
The researchers then used TinyStories to train an extremely small 10M parameter model which was subsequently able to generate “fluent narratives with perfect grammar.”
They continued to iterate and scale this synthetic data generation approach to create more advanced, but carefully curated and filtered synthetic datasets that were eventually used to train Phi-3 Mini.
The result is a tiny model that will be more affordable to run while offering performance comparable to GPT-3.5.
Smaller but more capable models will see companies move away from simply defaulting to large LLMs like GPT-4. We could also soon see solutions where an LLM handles the heavy lifting but delegates simpler tasks to lightweight models.



