

Researchers from the University of Surrey have developed a method to transform photographs of dogs into detailed 3D models.
The training material? Not real dogs, but rather computer-generated images from the virtual world of the hit game Grand Theft Auto V (GTA V).
Moira Shooter, a postgraduate research student involved in the study, shared of the study, “Our model was trained on CGI dogs – but we were able to use it to make 3D skeletal models from photographs of real animals. That could let conservationists spot injured wildlife, or help artists create more realistic animals in the metaverse.”
To date, methods for teaching AI about 3D structures involve using real photos alongside data about the objects’ actual 3D positions, often obtained through motion capture technology.
However, when applying these techniques to dogs or other animals, there are often too many movements to track, and getting dogs to behave for long enough is tough.
To build their dog dataset, researchers altered GTA V’s code to replace its human characters with dog avatars through a process known as “modding.”

Researchers produced 118 videos capturing these virtual dogs in various actions – sitting, walking, barking, and running – across different environmental conditions.
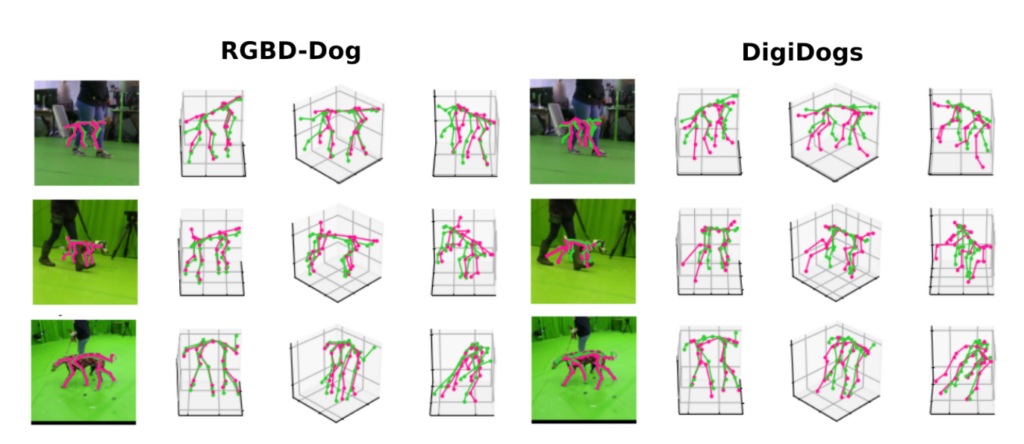
This culminated in the creation of ‘DigiDogs,’ a rich database containing 27,900 frames of dog movement, captured in a way real-world data collection hadn’t allowed.
With the dataset in hand, the next steps used Meta’s DINOv2 AI model for its strong generalization skills, fine-tuning it with DigiDogs to accurately predict 3D poses from single-view RGB images.
Researchers demonstrated that using the DigiDogs dataset for training resulted in more accurate and lifelike 3D dog poses than those trained on real-world datasets, thanks to the variety in dog appearances and actions captured.
The model’s enhanced performance was confirmed through thorough qualitative and quantitative evaluations.
While this study represented a big step forward in 3D animal modeling, the team acknowledges there’s more work to be done, especially in improving how the model predicts the depth aspect of the images (the z-coordinate).
Shooter described the potential impact of their work, saying, “3D poses contain so much more information than 2D photographs. From ecology to animation—this neat solution has so many possible uses.”
The paper won the Best Paper prize at the IEEE/CVF Winter Conference on Applications of Computer Vision.
It opens the door to better model performance in areas like wildlife conservation and 3D object rendering for VR.



