

Large Language Models (LLM) are often mislead by bias or irrelevant context in a prompt. Researchers at Meta have found a seemingly simple way to fix that.
As context windows increase the prompts that we enter into an LLM can become longer and increasingly detailed. LLMs have become better at picking up on the nuances or smaller details in our prompts, but sometimes this can confuse them.
Early machine learning used a “hard attention” approach that singled out the most relevant part of an input and responded only to that. This works fine when you’re trying to caption an image, but poorly when translating a sentence or answering a multi-layered question.
Most LLMs now use a “soft attention” approach which tokenizes the entire prompt and assigns weights to each one.
Meta proposes an approach called System 2 Attention (S2A) to get the best of both worlds. S2A uses the natural language processing ability of an LLM to take your prompt and strip out bias and irrelevant information before getting to work on a response.
Here’s an example.

S2A gets rid of the info relating to Max as it’s irrelevant to the question. S2A regenerates an optimized prompt before starting to work on it. LLMs are notoriously bad at math so making the prompt less confusing is a big help.
LLMs are people pleasers and are happy to agree with you, even when you’re wrong. S2A strips out any bias in a prompt and then only processes the relevant parts of the prompt. This reduces what AI researchers call “sycophancy”, or an AI model’s propensity for butt kissing.

S2A is really just a system prompt instructing the LLM to refine the original prompt a bit before getting to work on it. The results the researchers achieved with math, factual, and long-form questions were impressive.
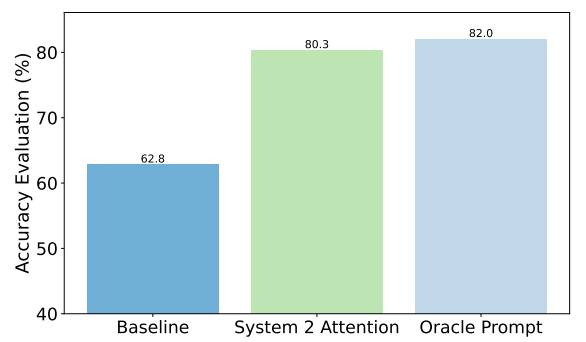
As an example, here are the improvements S2A achieved on factual questions. The baseline was responses to questions that contained bias, while the Oracle prompt was a human-refined ideal prompt.
S2A gets really close to the Oracle prompt results and delivers almost 50% improvement in accuracy over the baseline prompt.
So what’s the catch? Pre-processing the original prompt before answering it adds additional computation requirements to the process. If the prompt is long and has a lot of relevant information then regenerating the prompt can add significant costs.
Users are unlikely to get better at writing well-crafted prompts so S2A may be a good way to get around that.
Will Meta be building S2A into its Llama model? We don’t know, but you can leverage the S2A approach yourself.
If you’re careful to omit opinions or leading suggestions from your prompts then you’re more likely to get accurate responses from these models.



