

OpenAI boss Sam Altman swiped at the EU, suggesting the EU draft AI Act was over-regulating and impossible to satisfy. Days later, he tweeted that OpenAI is excited to continue operations in the EU.
Altman has been jet-setting across Europe, meeting politicians from Germany, France, Spain, Poland, and the UK. However, he reportedly canceled an appointment in Brussels, where lawmakers are drafting the EU AI Act.
He’d previously stated OpenAI would struggle to comply with the Act, “if we can comply, we will, and if we can’t, we’ll cease operating. We will try. But there are technical limits to what’s possible.”
After some backlash on social media, Altman appeared to U-turn on his comments; “we are excited to continue to operate here and of course have no plans to leave.”
very productive week of conversations in europe about how to best regulate AI! we are excited to continue to operate here and of course have no plans to leave.
— Sam Altman (@sama) May 26, 2023
Altman had previously told Reuters, “The current draft of the EU AI Act would be over-regulating, but we have heard it’s going to get pulled back.”
The EU responded – Dutch MEP Kim van Sparrentak said lawmakers drafting the AI Act “shouldn’t let ourselves be blackmailed by American companies.”
She went on to say, “If OpenAI can’t comply with basic data governance, transparency, safety, and security requirements, then their systems aren’t fit for the European market.”
AI Act could place large language models (LLMs) in a “high-risk” category
The EU AI Act defines different categories of AI, including a “high risk” category subject to strict rules governing transparency and monitoring. This seems to be the center of Altman’s fears.
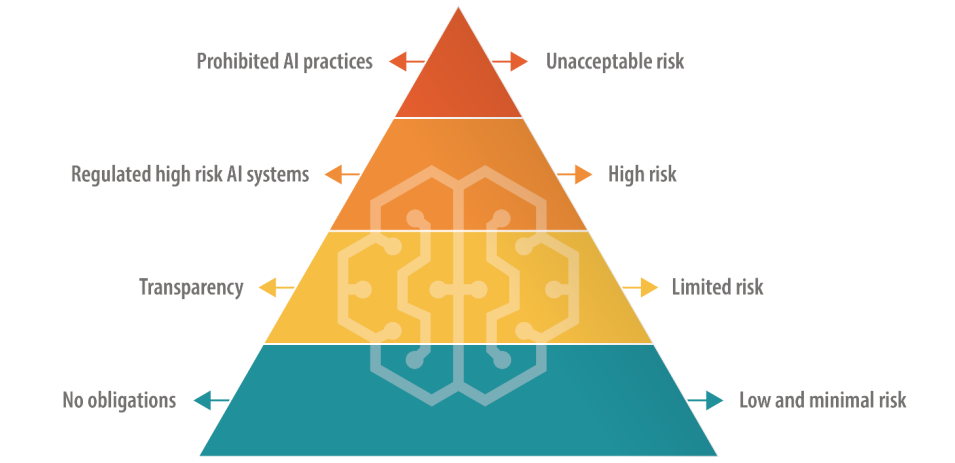
As of the current draft, companies deploying high-risk AIs must disclose any copyrighted material included in training data and log activity to ensure the replicability and traceability of outputs. It could be costly and burdensome for smaller AI companies.
Copyrighted material remains a sticking point
OpenAI is far from an open book regarding copyrighted material in its training data.
The AI has been found to repeat lines from several novels, including Harry Potter and Game of Thrones. Researchers suggest this is likely because passages from books frequently appear in the public domain.
There are many pending copyright-related legal cases against OpenAI, Microsoft, and the creators behind image generators like Midjourney. Right now, we simply don’t know the extent of AI’s use of copyright data and the methods of retrieving it.
The EU wants to change that by introducing transparency rules, which could change how AIs are trained, and, therefore, their performance.
We may be living in an unregulated AI bubble that’s about to burst.



