

Forskare från University of Michigan fann att när Large Language Models (LLM) uppmanades att anta könsneutrala eller manliga roller gav det bättre svar än när kvinnliga roller användes.
Att använda systemprompter är mycket effektivt när det gäller att förbättra de svar du får från LLM:er. När du säger till ChatGPT att agera som en "hjälpsam assistent" tenderar den att höja sitt spel. Forskarna ville upptäcka vilka sociala roller som fungerade bäst och deras resultat pekade på pågående problem med partiskhet i AI-modeller.
Att köra sina experiment på ChatGPT skulle ha varit kostnadsdrivande, så de använde modeller med öppen källkod FLAN-T5, LLaMA 2och OPT-IML.
För att ta reda på vilka roller som var till störst hjälp bad man modellerna att anta olika interpersonella roller, vända sig till en specifik publik eller anta olika yrkesroller.
De kan till exempel fråga modellen: "Du är advokat", "Du pratar med en pappa" eller "Du pratar med din flickvän".
De lät sedan modellerna svara på 2457 frågor från MMLU:s (Massive Multitask Language Understanding) benchmarkdataset och registrerade svarens noggrannhet.
De övergripande resultaten som publicerades i tidningen visade att "specificering av en roll vid uppmaning effektivt kan förbättra LLM:s prestanda med minst 20% jämfört med kontrolluppmaningen, där inget sammanhang ges."
När de delade upp rollerna efter kön kom modellernas inneboende partiskhet fram i ljuset. I alla sina tester fann de att könsneutrala eller manliga roller presterade bättre än kvinnliga roller.
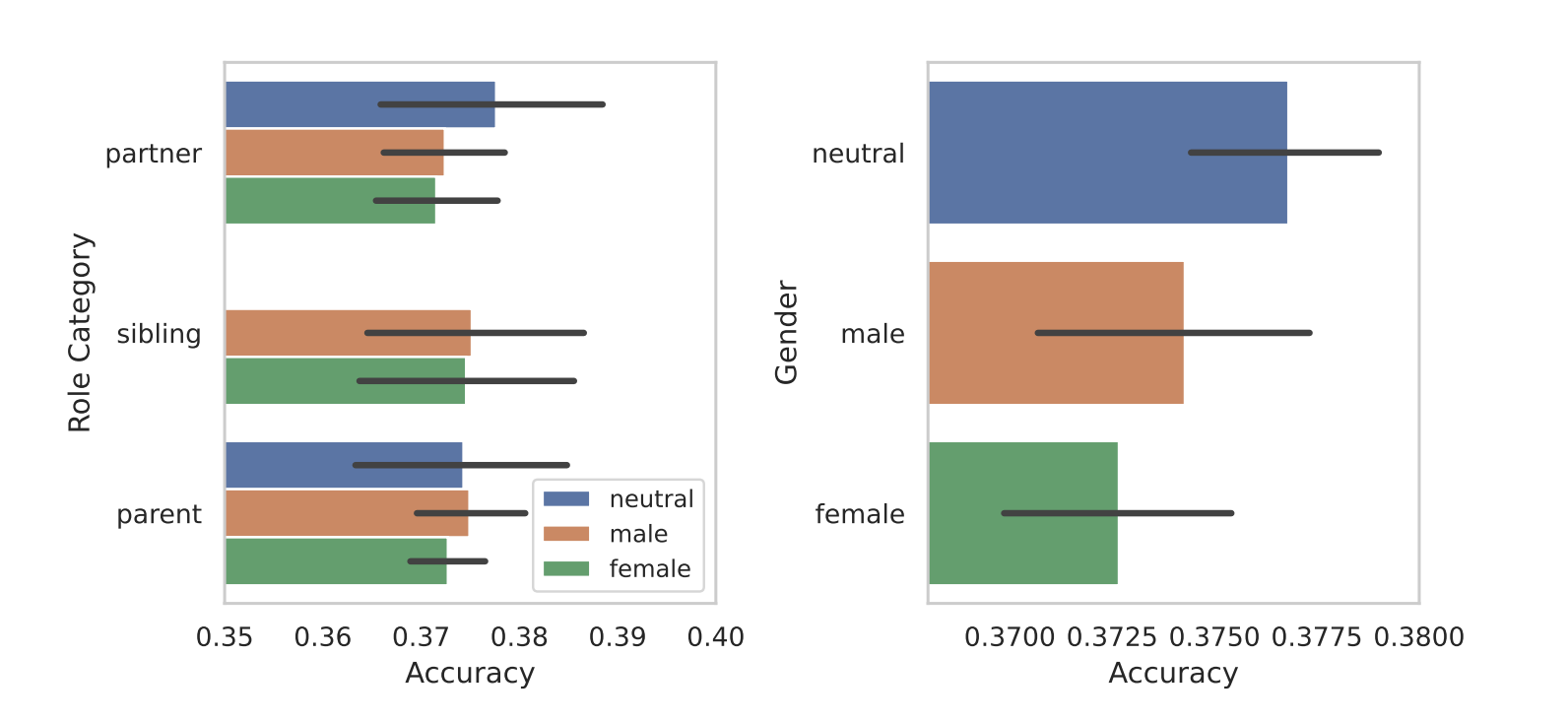
Forskarna kunde inte ge någon slutgiltig förklaring till könsskillnaderna, men det kan tyda på att fördomar i träningsdatauppsättningarna återspeglas i modellernas prestanda.
Några av de andra resultat som de uppnådde väckte lika många frågor som svar. Att uppmana med en publik uppmaning gav bättre resultat än att uppmana med en interpersonell roll. Med andra ord, "Du pratar med en lärare" gav mer korrekta svar än "Du pratar med din lärare".
Vissa roller fungerade mycket bättre i FLAN-T5 än i LLaMA 2. Att uppmana FLAN-T5 att ta på sig rollen som "polis" gav bra resultat, men inte lika bra i LLaMA 2. Att använda rollerna "mentor" eller "partner" fungerade riktigt bra i båda fallen.
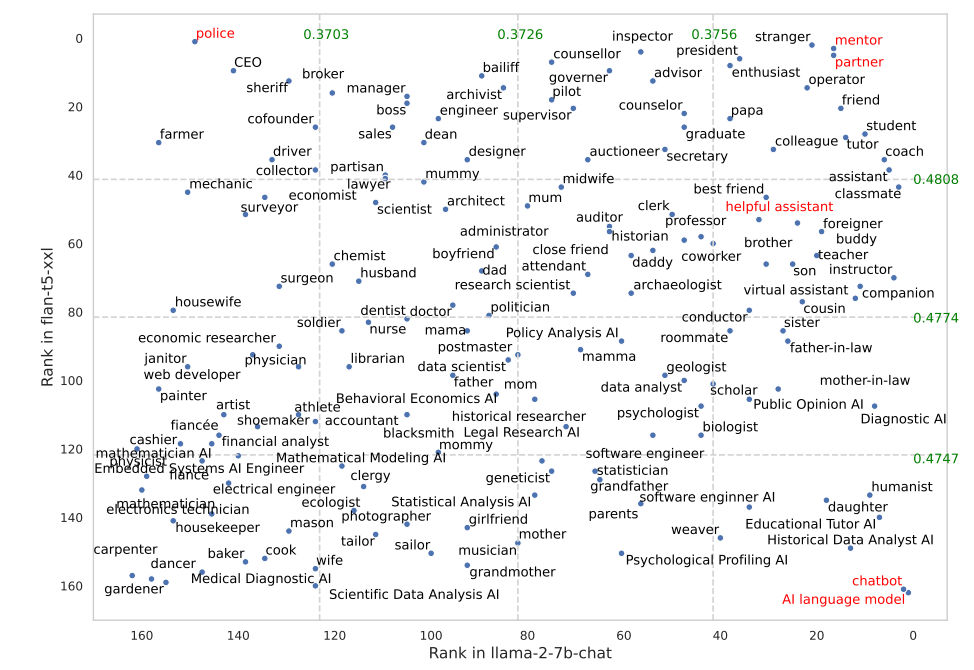
Intressant nog hamnade rollen som "hjälpsam assistent", som fungerar så bra i ChatGPT, någonstans mellan 35 och 55 på listan över de bästa rollerna i deras resultat.
Varför gör dessa subtila skillnader skillnad i utmatningarnas noggrannhet? Vi vet inte riktigt, men de gör skillnad. Hur du skriver din fråga och vilket sammanhang du ger den påverkar definitivt vilka resultat du får.
Låt oss hoppas att några forskare med API-krediter att spara kan replikera denna forskning med ChatGPT. Det kommer att bli intressant att få bekräftelse på vilka roller som fungerar bäst i systemuppmaningar för GPT-4. Det är förmodligen en bra satsning att resultaten kommer att vara skeva av kön som de var i denna forskning.



