

Специалисты Оксфордского университета разработали способ проверки того, когда языковые модели "не уверены" в своих выводах и рискуют вызвать галлюцинации.
Под "галлюцинациями" ИИ понимается явление, когда большие языковые модели (LLM) генерируют беглые и правдоподобные ответы, которые не являются правдивыми или последовательными.
Галлюцинации сложно - если вообще возможно - отделить от моделей ИИ. Разработчики ИИ, такие как OpenAI, Google и Anthropic, признали, что галлюцинации, скорее всего, останутся побочным продуктом взаимодействия с ИИ.
Как отметил доктор Себастьян Фаркухар, один из авторов исследования, объясняет в своем блогеМагистранты обладают большой способностью говорить об одном и том же разными способами, что может затруднить определение того, когда они уверены в ответе, а когда буквально просто что-то выдумывают".
Кембриджский словарь даже добавил Определение слова, связанного с искусственным интеллектом в 2023 году и назвал его "Словом года".
Этот Оксфордский университет исследованиеОпубликовано в журнале Nature, Цель исследования - ответить на вопрос, как определить, когда эти галлюцинации наиболее вероятны.
Она вводит понятие "семантическая энтропия", которое измеряет неопределенность результатов работы LLM на уровне смысла, а не только конкретных слов или фраз.
Вычисляя семантическую энтропию ответов LLM, исследователи могут оценить степень уверенности модели в своих выводах и определить случаи, когда она, скорее всего, галлюцинирует.
Семантическая энтропия в LLM объясняется
Семантическая энтропия, согласно определению исследования, измеряет неопределенность или противоречивость смысла ответов LLM. Это помогает обнаружить, когда LLM может галлюцинировать или генерировать недостоверную информацию.
Проще говоря, семантическая энтропия измеряет, насколько "запутанным" является вывод LLM.
LLM, скорее всего, предоставит достоверную информацию, если смысл его результатов будет тесно связан и согласован. Но если значения разрозненны и непоследовательны, это тревожный сигнал о том, что у LLM могут быть галлюцинации или он генерирует неточную информацию.
Вот как это работает:
- Исследователи активно побуждали LLM генерировать несколько возможных ответов на один и тот же вопрос. Это достигается путем подачи вопроса на LLM несколько раз, каждый раз с разными случайными семенами или небольшими изменениями в исходных данных.
- Семантическая энтропия изучает ответы и группирует те, которые имеют одинаковый основной смысл, даже если в них используются разные слова или формулировки.
- Если ЛЛМ уверен в ответе, его ответы должны иметь схожий смысл, что приведет к низкому показателю семантической энтропии. Это говорит о том, что ЛЛМ четко и последовательно понимает информацию.
- Однако если ЛЛМ неуверен или растерян, его ответы будут иметь более широкий спектр значений, некоторые из которых могут быть непоследовательными или не иметь отношения к вопросу. Это приводит к высокому показателю семантической энтропии, указывая на то, что ЛЛМ может галлюцинировать или генерировать недостоверную информацию.
Чтобы оценить его эффективность, исследователи применили семантическую энтропию к разнообразным задачам, связанным с ответами на вопросы. Для этого использовались такие эталоны, как Вопросы о мелочах, понимание прочитанного, задачи на слова и биографии.
Семантическая энтропия превзошла все существующие методы для обнаружения случаев, когда LLM, скорее всего, генерирует неправильный или противоречивый ответ.
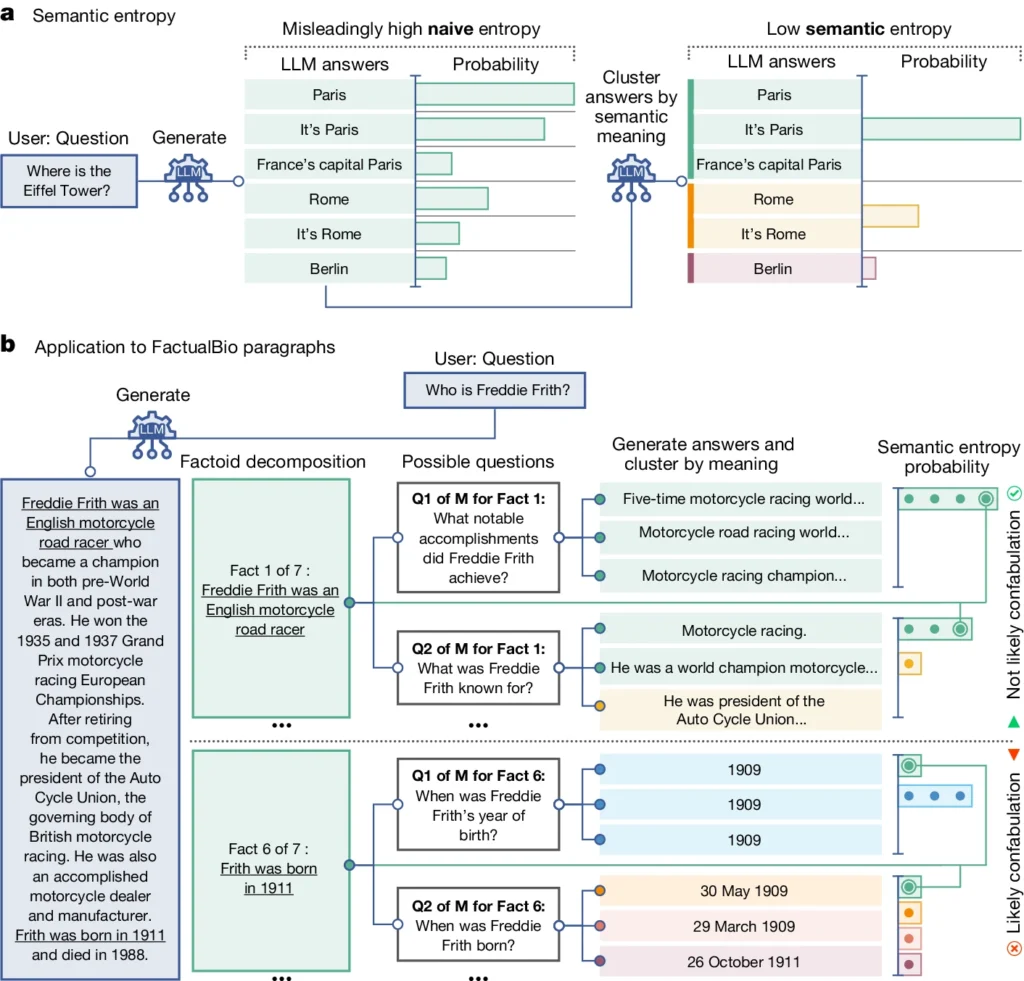
На приведенной выше диаграмме видно, как некоторые подсказки заставляют LLM генерировать конфабулированный (неточный, галлюцинаторный) ответ. Например, он выдает день и месяц рождения для вопросов в нижней части диаграммы, когда информация, необходимая для ответа на них, не была предоставлена в исходной информации.
Последствия обнаружения галлюцинаций
Эта работа может помочь объяснить галлюцинации и сделать LLM более надежными и заслуживающими доверия.
Семантическая энтропия, позволяющая обнаружить, когда LLM не уверен в себе или склонен к галлюцинациям, открывает путь для применения этих инструментов ИИ в областях с высокими ставками, где точность фактов имеет решающее значение, таких как здравоохранение, юриспруденция и финансы.
Ошибочные результаты могут иметь потенциально катастрофические последствия, когда они влияют на ситуации с высокими ставками, как показали некоторые неудачная предиктивная полиция и системы здравоохранения.
Однако важно помнить, что галлюцинации - это лишь один из видов ошибок, которые могут совершать магистранты.
Как объясняет доктор Фаркухар, "если LLM постоянно совершает ошибки, новый метод этого не заметит". Самые опасные сбои в работе ИИ происходят, когда система делает что-то плохое, но при этом уверенно и систематически. Нам предстоит еще много работы".
Тем не менее, метод семантической энтропии, разработанный оксфордской командой, представляет собой большой шаг вперед в нашей способности понять и смягчить ограничения языковых моделей ИИ.
Предоставление объективных средств для их обнаружения приближает нас к будущему, в котором мы сможем использовать потенциал ИИ, обеспечивая при этом его надежность и надежность инструмента на службе человечества.



