

Эпоха ИИ представляет собой сложное взаимодействие между технологиями и общественным мнением.
Возрастающая сложность систем искусственного интеллекта стирает границы между людьми и машинами - является ли технология ИИ отдельной от нас? В какой степени ИИ наследует человеческие недостатки и промахи наряду с навыками и знаниями?
Возможно, заманчиво представить ИИ как эмпирическую технологию, подчёркнутую объективностью математики, кода и вычислений.
Однако мы осознаем, что решения, принимаемые системами искусственного интеллекта, весьма субъективны и основаны на данных, которые они получают, а люди решают, как выбрать и скомпоновать эти данные.
В этом кроется сложность, поскольку данные для обучения ИИ часто воплощают в себе предубеждения, предрассудки и дискриминацию, с которыми борется человечество.
Даже, казалось бы, малозаметные формы неосознанной предвзятости могут быть усилены в процессе обучения модели, что в конечном итоге проявляется в виде неправильного совпадения лиц в правоохранительных органах, отказа в выдаче кредита, неправильной диагностики заболеваний, нарушения работы механизмов безопасности в самодвижущихся автомобилях и т. д.
Попытки человечества предотвратить дискриминацию в обществе еще не завершены, но ИИ уже сейчас помогает принимать важнейшие решения.
Сможем ли мы работать достаточно быстро, чтобы синхронизировать ИИ с современными ценностями и предотвратить необъективные решения и поведение, меняющие жизнь?
Разгадка предвзятости в искусственном интеллекте
За последнее десятилетие системы искусственного интеллекта доказали, что они отражают общественные предрассудки.
Эти системы не являются предвзятыми по своей сути - вместо этого они впитывают предвзятость своих создателей и данные, на которых они обучаются.
Системы искусственного интеллекта, как и люди, учатся путем воздействия. Человеческий мозг - это, казалось бы, бесконечный кладезь информации, библиотека с почти неограниченным количеством полок, где мы храним опыт, знания и воспоминания.
Неврология исследования показывают, что мозг на самом деле не имеет "максимальной емкости" и продолжает сортировать и хранить информацию до глубокой старости.
Хотя мозг далек от совершенства, его прогрессивный, итеративный процесс обучения помогает нам адаптироваться к новым культурным и общественным ценностям - от разрешения женщинам голосовать и принятия различных идентичностей до прекращения рабства и других форм сознательных предрассудков.
WСейчас мы живем в эпоху, когда инструменты искусственного интеллекта используются для принятия важных решений вместо человеческих суждений.
Многие модели машинного обучения (ML) обучаются на основе тренировочных данных, которые составляют основу для принятия решений, и не могут вводить новую информацию так же эффективно, как человеческий мозг. Поэтому они часто не способны принимать актуальные решения, на которые мы привыкли полагаться.
Например, модели ИИ используются для определения совпадений лиц в правоохранительных органах, анализировать резюме для поиска работыи принимать важные для здоровья решения в клинических условиях.
Поскольку общество продолжает внедрять искусственный интеллект в нашу повседневную жизнь, мы должны обеспечить его равные и точные возможности для всех.
В настоящее время это не так.
Тематические исследования в области предвзятости ИИ
В реальном мире существует множество примеров предубеждений, предрассудков и дискриминации, связанных с ИИ.
В одних случаях последствия предвзятости ИИ меняют жизнь, в других - остаются на заднем плане, незаметно влияя на принятие решений.
1. Предвзятость набора данных MIT
Учебный набор данных Массачусетского технологического института, созданный в 2008 году, называется Крошечные изображения содержит около 80 000 000 изображений, относящихся к примерно 75 000 категориям.
Изначально он был задуман для обучения систем искусственного интеллекта распознаванию людей и объектов на изображениях и стал популярным эталонным набором данных для различных приложений в области компьютерного зрения (CV).
A 2020 анализ The Register обнаружил, что многие Tiny Images содержал непристойные, расистские и сексистские надписи.
Антонио Торральба из MIT заявил, что лаборатория не знала об этих оскорбительных надписях, и сказал The Register: "Очевидно, что мы должны были проверять их вручную". Позже MIT выпустила заявление, в котором говорится, что они удалили набор данных из сервиса.

Это не единственный случай, когда бывший эталонный набор данных был признан небезупречным. Labeled Faces in the Wild (LFW), набор данных лиц знаменитостей, широко используемый в задачах распознавания лиц, состоит из 77,5% мужчин и 83,5% белокожих людей.
Многие из этих ветеранских наборов данных нашли свое применение в современных моделях ИИ, но они возникли в эпоху развития ИИ, когда основное внимание уделялось созданию систем, которые просто работать а не те, которые подходят для развертывания в реальных сценариях.
Если система искусственного интеллекта обучена на таком наборе данных, она не обязательно обладает теми же привилегиями, что и человеческий мозг, в плане перекалибровки под современные ценности.
Хотя модели можно обновлять итеративно, это медленный и несовершенный процесс, который не может соответствовать темпам развития человечества.
2: Распознавание образов: предубеждение против темнокожих людей
В 2019 году Правительство США обнаружило что самые совершенные системы распознавания лиц ошибаются в идентификации чернокожих людей в 5-10 раз чаще, чем белых.
Это не просто статистическая аномалия - она имеет серьезные последствия в реальном мире, начиная от Google Photos, идентифицирующих чернокожих людей как горилл, и заканчивая самоуправляемыми автомобилями, не распознающими темнокожих людей и въезжающими в них.
Кроме того, произошла целая серия неправомерных арестов и тюремных заключений, связанных с фальшивыми совпадениями лиц, и, пожалуй, самыми распространенными из них были Ниджир Паркс которого ложно обвинили в краже из магазина и нарушении правил дорожного движения, несмотря на то, что он находился в 30 милях от места происшествия. Впоследствии Паркс провел 10 дней в тюрьме и был вынужден выплатить тысячи за судебные издержки.

Влиятельное исследование 2018 года, Гендерные оттенкиВ дальнейшем исследователи изучили предвзятость алгоритмов. В ходе исследования были проанализированы алгоритмы, созданные компаниями IBM и Microsoft, и было обнаружено, что при работе с темнокожими женщинами их точность снижается, а количество ошибок на 34% больше, чем при работе со светлокожими мужчинами.
Эта закономерность была обнаружена в 189 различных алгоритмах.
Видеоролик, представленный ниже ведущим исследователем Джой Буоламвини (Joy Buolamwini), наглядно демонстрирует, как различаются показатели распознавания лиц при разном цвете кожи.
3: Проект CLIP от OpenAI
OpenAI's Проект CLIPВыпущенный в 2021 году проект, предназначенный для сопоставления изображений с описательным текстом, также проиллюстрировал существующие проблемы с предвзятостью.
В документе, посвященном аудиту, создатели CLIP рассказали о своих опасениях, заявив: "CLIP приписывает некоторые ярлыки, описывающие профессии с высоким статусом, непропорционально часто мужчинам, такие как "руководитель" и "врач". Это похоже на предубеждения, обнаруженные в Google Cloud Vision (GCV), и указывает на исторические гендерные различия".
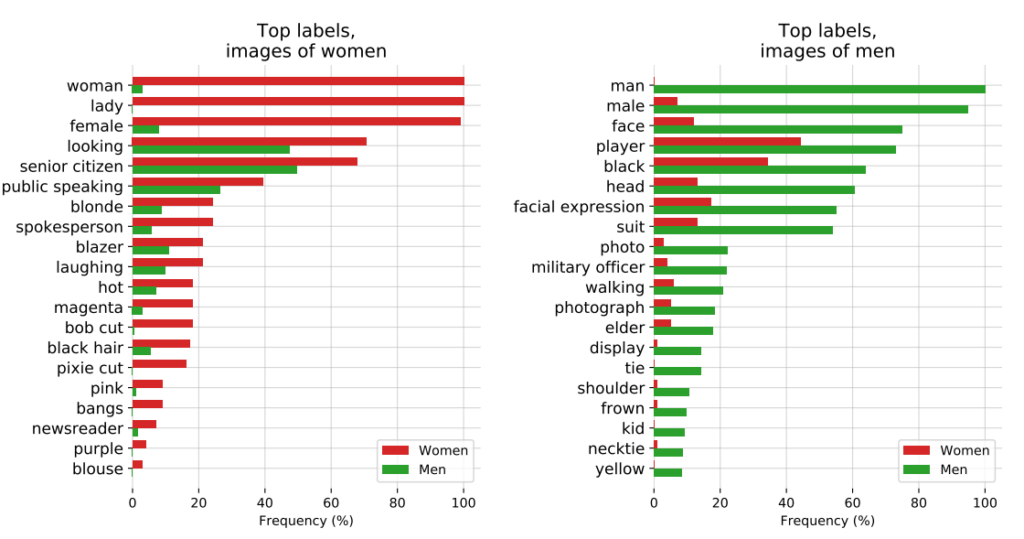
4: Правоохранительные органы: споры вокруг PredPol
Еще одним примером алгоритмической предвзятости на высоких ставках является PredPolалгоритм предиктивной работы полиции, используемый различными полицейскими департаментами США.
PredPol был обучен на исторических данных о преступлениях, чтобы предсказать будущие очаги преступности.
Однако, поскольку эти данные по своей сути отражают предвзятую полицейскую практику, алгоритм подвергся критике за увековечивание расового профилирования и непропорциональное воздействие на районы проживания меньшинств.
5: Предвзятость в дерматологическом искусственном интеллекте
В здравоохранении потенциальные риски предвзятости ИИ становятся еще более очевидными.
Возьмем, к примеру, системы искусственного интеллекта, предназначенные для выявления рака кожи. Многие из этих систем обучаются на массивах данных, состоящих в подавляющем большинстве из светлокожих людей.
A 2021 исследование Оксфордского университета исследовали 21 базу данных с открытым доступом на предмет наличия изображений рака кожи. Они обнаружили, что из 14 наборов данных, которые раскрывали свое географическое происхождение, 11 состояли исключительно из изображений из Европы, Северной Америки и Океании.
Только на 2436 из 106 950 изображений из 21 базы данных была записана информация о типе кожи. Исследователи отметили, что "только 10 изображений принадлежали людям со смуглой кожей, а одно - человеку с темно-коричневой или черной кожей".
Что касается данных об этнической принадлежности, то эту информацию предоставили только 1585 изображений. Исследователи обнаружили, что "ни на одном изображении не было людей с африканским, афро-карибским или южно-азиатским происхождением".
Они пришли к выводу: "В сочетании с географическим происхождением наборов данных, изображения поражений кожи темнокожего населения были представлены крайне недостаточно".
Если такие ИИ будут применяться в клинических условиях, то необъективные наборы данных создадут вполне реальный риск ошибочного диагноза.
Выявление предвзятости в обучающих наборах данных ИИ: продукт их создателей?
Обучающие данные - чаще всего текст, речь, изображения и видео - обеспечивают модели машинного обучения (ML) основу для изучения концепций.
Системы искусственного интеллекта изначально представляют собой не более чем чистые холсты. Они учатся и формируют ассоциации на основе наших данных, по сути, рисуя картину мира, изображенную на их обучающих наборах данных.
Обучаясь на обучающих данных, мы надеемся, что модель будет применять изученные концепции к новым, еще не изученным данным.
После развертывания некоторые продвинутые модели могут обучаться на новых данных, но их учебные данные по-прежнему определяют их фундаментальную производительность.
Первый вопрос, на который необходимо ответить, - откуда берутся данные? Данные, собранные из нерепрезентативных, часто однородных и исторически неравноправных источников, являются проблематичными.
Это, вероятно, относится к значительному количеству онлайн-данных, включая текстовые и графические данные, взятые из "открытых" или "публичных" источников.
Созданный всего несколько десятилетий назад, интернет не является панацеей для человеческих знаний и далеко не справедлив. Половина мира не пользуется Интернетом, не говоря уже о вкладе в его развитие, а это значит, что он в корне не отражает глобальное общество и культуру.
Более того, хотя разработчики ИИ постоянно работают над тем, чтобы преимущества технологии не ограничивались только англоязычным миром, большинство обучающих данных (текст и речь) создаются на английском языке, а значит, англоязычные участники определяют результаты моделирования.
Исследователи из компании Anthropic недавно выпустила документ в котором говорится: "Если языковая модель непропорционально представляет определенные мнения, она рискует вызвать потенциально нежелательные эффекты, такие как продвижение гегемонистского мировоззрения и гомогенизация взглядов и убеждений людей".
В конечном итоге, хотя системы ИИ работают на основе "объективных" принципов математики и программирования, они, тем не менее, существуют внутри и формируются под влиянием глубоко субъективного человеческого социального контекста.
Возможные решения проблемы предвзятости алгоритмов
Если основной проблемой являются данные, то решение для создания справедливых моделей может показаться простым: нужно просто сделать наборы данных более сбалансированными, верно?
Не совсем. A исследование 2019 года показал, что сбалансированность наборов данных недостаточна, поскольку алгоритмы по-прежнему непропорционально воздействуют на защищенные характеристики, такие как пол и раса.
Авторы пишут: "Удивительно, но мы показали, что даже когда наборы данных сбалансированы таким образом, что каждая метка одинаково часто встречается с каждым полом, выученные модели усиливают ассоциацию между метками и полом настолько же, как если бы данные не были сбалансированы!"
Они предлагают метод де-биасинга, при котором такие метки полностью удаляются из набора данных. Другие методы включают добавление случайных возмущений и искажений, которые снижают внимание алгоритма к конкретным защищенным характеристикам.
Кроме того, хотя изменение методов обучения и оптимизации машинного обучения является неотъемлемой частью получения непредвзятых результатов, продвинутые модели подвержены изменениям или "дрейфу", что означает, что их производительность не обязательно остается неизменной в долгосрочной перспективе.
Модель может быть абсолютно беспристрастной на этапе развертывания, но впоследствии, при увеличении количества новых данных, стать необъективной.
Движение за прозрачность алгоритмов
В своей провокационной книге Искусственный интеллект: Как компьютеры неправильно понимают мирМередит Бруссард выступает за повышение "прозрачности алгоритмов", чтобы подвергнуть системы искусственного интеллекта многоуровневой проверке.
Это означает предоставление четкой информации о том, как работает система, как она обучалась и на каких данных.
В то время как инициативы по обеспечению прозрачности легко вписываются в ландшафт ИИ с открытым исходным кодом, собственные модели, такие как GPT, Bard и Anthropic's Claude, являются "черными ящиками", и только их разработчики знают, как именно они работают - и даже это является предметом споров.
Проблема "черного ящика" в ИИ означает, что внешние наблюдатели видят только то, что поступает в модель (входные данные) и что выходит (выходные данные). Внутренняя механика полностью неизвестна, за исключением ее создателей - подобно тому, как магический круг скрывает секреты фокусников. ИИ просто вытаскивает кролика из шляпы.
Проблема "черного ящика" недавно выкристаллизовалась вокруг сообщений о Потенциальное снижение производительности GPT-4. Пользователи GPT-4 утверждают, что возможности модели стремительно падают, и хотя OpenAI признала, что это так, они не совсем ясно объяснили, почему это происходит. Возникает вопрос, а знают ли они вообще?
Исследователь ИИ доктор Саша Лучиони говорит, что недостаточная прозрачность OpenAI - это проблема, которая касается и других разработчиков проприетарных или закрытых моделей ИИ. "Любые результаты, полученные с помощью закрытых моделей, не воспроизводятся и не проверяются, поэтому с научной точки зрения мы сравниваем енота с белкой".
“Ученые не обязаны постоянно следить за развернутыми LLM. Создатели моделей должны предоставить доступ к базовым моделям, хотя бы для целей аудита", - говорит она.
Лучиони подчеркнул, что разработчики моделей ИИ должны предоставлять необработанные результаты стандартных эталонов, таких как SuperGLUE и WikiText, а также эталонов смещения, таких как BOLD и HONEST.
Борьба с предвзятостью и предубеждениями, вызванными ИИ, скорее всего, будет вестись постоянно, требуя постоянного внимания и исследований, чтобы держать результаты работы моделей под контролем по мере совместного развития ИИ и общества.
Несмотря на то, что регулирование будет предписывать формы мониторинга и отчетности, жестких и быстрых решений проблемы алгоритмической предвзятости не существует, и это не последнее, что мы слышим о ней.



