

Elon Musk anunciou o lançamento da versão beta do chatbot da xAI chamado Grok e as estatísticas iniciais estão a dar-nos uma ideia de como se compara com outros modelos.
O Grok chatbot baseia-se no modelo de fronteira da xAI chamado Grok-1, que a empresa desenvolveu nos últimos quatro meses. A xAI não disse com quantos parâmetros foi treinado, mas apresentou alguns números para o seu antecessor.
O Grok-0, o protótipo do modelo atual, foi treinado com 33 mil milhões de parâmetros, pelo que podemos provavelmente assumir que o Grok-1 foi treinado com pelo menos o mesmo número.
Não parece muito, mas a xAI afirma que o desempenho do Grok-0 "aproxima-se das capacidades do LLaMA 2 (70B) em benchmarks LM padrão", apesar de ter utilizado metade dos recursos de treino.
Na ausência de um valor de parâmetro, temos de aceitar a palavra da empresa quando descreve o Grok-1 como "topo de gama" e que é "significativamente mais poderoso" do que o Grok-0.
O Grok-1 foi testado avaliando-o nestes padrões de referência de aprendizagem automática:
- GSM8k: Problemas de matemática do ensino médio
- MMLU: Perguntas multidisciplinares de escolha múltipla
- HumanEval: tarefa de conclusão de código Python
- MATH: Problemas de matemática do ensino básico e secundário escritos em LaTeX
Eis um resumo dos resultados.
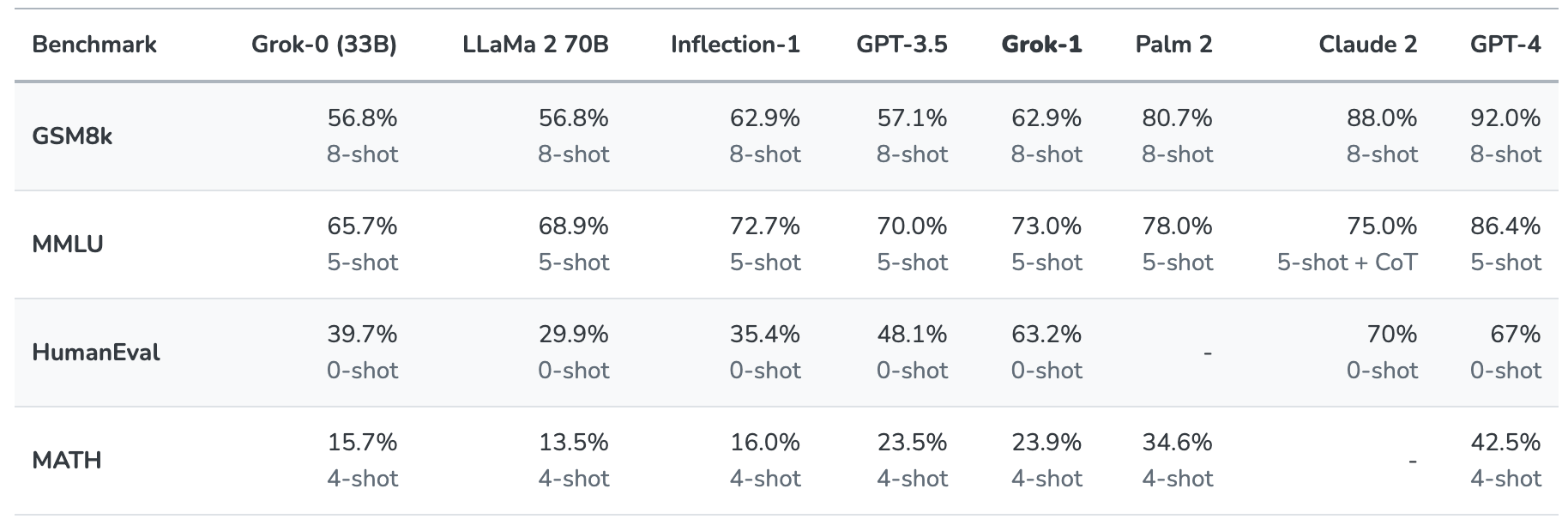
Os resultados são interessantes na medida em que nos dão pelo menos uma ideia de como o Grok se compara com outros modelos de fronteira.
A xAI afirma que estes números mostram que o Grok-1 supera "todos os outros modelos na sua classe de computação" e só foi superado por modelos treinados por uma "quantidade significativamente maior de dados de treino e recursos de computação".
O GPT-3.5 tem 175 biliões de parâmetros, pelo que podemos assumir que o Grok-1 tem menos do que isso, mas provavelmente mais do que os 33 biliões do seu protótipo.
O chatbot Grok destina-se a processar tarefas como resposta a perguntas, recuperação de informações, escrita criativa e assistência na codificação. É mais provável que seja utilizado em interacções mais curtas do que em casos de utilização de super-prontas, devido à sua janela de contexto mais pequena.
Com um comprimento de contexto de 8.192, o Grok-1 tem apenas metade do contexto que o GPT-3.5 tem. Isso é uma indicação de que a xAI provavelmente pretendia que o Grok-1 trocasse um contexto mais longo por uma melhor eficiência.
A empresa afirma que algumas das suas pesquisas actuais se centram na "compreensão e recuperação de contextos longos", pelo que a próxima iteração do Grok poderá ter uma janela de contexto maior.
O conjunto de dados exato que foi utilizado para treinar o Grok-1 não é claro, mas é quase certo que incluía os seus tweets no X, e o chatbot Grok também tem acesso em tempo real à Internet.
Teremos de esperar por mais feedback dos testadores beta para ter uma ideia real da qualidade do modelo.
Será que a Grok nos vai ajudar a desvendar os mistérios da vida, do universo e de tudo o resto? Talvez ainda não, mas é um bom começo.



