

Os investigadores do Google DeepMind desenvolveram o NATURAL PLAN, um parâmetro de referência para avaliar a capacidade dos LLM de planearem tarefas reais com base em instruções de linguagem natural.
A próxima evolução da IA é fazer com que ela saia dos limites de uma plataforma de conversação e assuma funções de agente para concluir tarefas em plataformas em nosso nome. Mas isso é mais difícil do que parece.
Planear tarefas como marcar uma reunião ou compilar um itinerário de férias pode parecer simples para nós. Os seres humanos são bons a raciocinar através de vários passos e a prever se um curso de ação vai ou não atingir o objetivo desejado.
Pode ser fácil, mas até os melhores modelos de IA têm dificuldades em planear. Poderíamos compará-los para ver qual é o melhor LLM em termos de planeamento?
O benchmark NATURAL PLAN testa os LLMs em 3 tarefas de planeamento:
- Planeamento da viagem - Planear um itinerário de viagem com restrições de voo e de destino
- Planeamento de reuniões - Agendar reuniões com vários amigos em diferentes locais
- Programação do calendário - Agendamento de reuniões de trabalho entre várias pessoas, tendo em conta os horários existentes e vários condicionalismos
A experiência começou com um estímulo de poucos disparos, em que os modelos receberam 5 exemplos de estímulos e as correspondentes respostas correctas. Em seguida, foram-lhes dadas instruções de planeamento de dificuldade variável.
Eis um exemplo de um pedido e de uma solução fornecidos como exemplo para os modelos:

Resultados
Os investigadores testaram o GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, e Gemini 1.5 Pronenhum dos quais teve um desempenho muito bom nestes testes.
No entanto, os resultados devem ter caído bem no escritório da DeepMind, uma vez que o Gemini 1.5 Pro ficou em primeiro lugar.

Como era de esperar, os resultados pioraram exponencialmente com as solicitações mais complexas, em que o número de pessoas ou cidades foi aumentado. Por exemplo, veja como a precisão diminuiu rapidamente à medida que mais pessoas foram adicionadas ao teste de planeamento de reuniões.
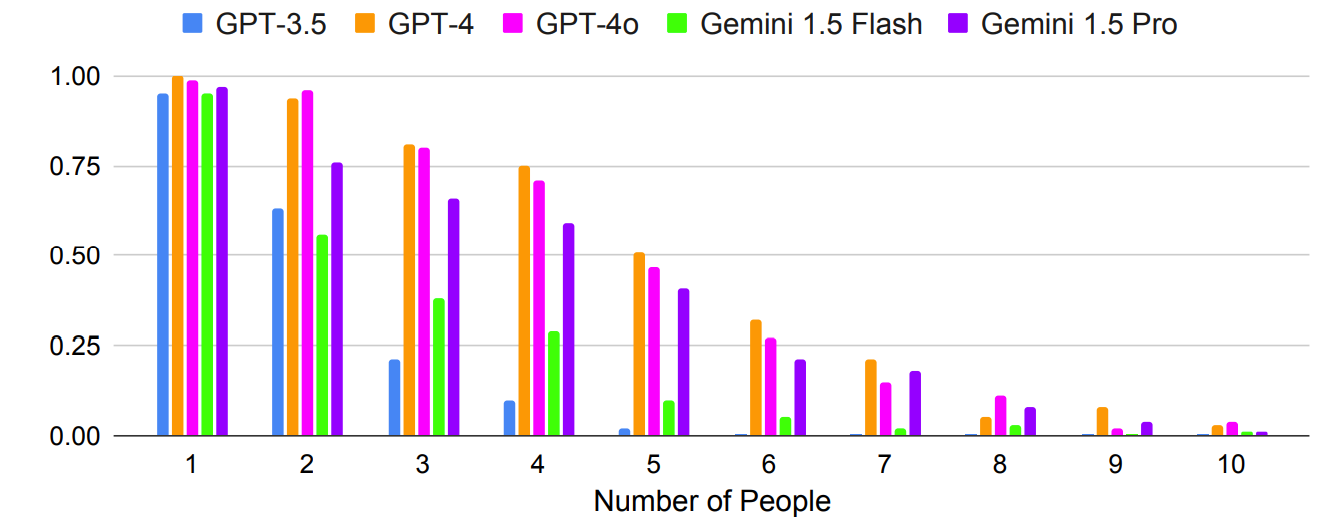
Poderá a solicitação de múltiplos disparos resultar numa maior precisão? Os resultados da investigação indicam que sim, mas apenas se o modelo tiver uma janela de contexto suficientemente grande.
A janela de contexto maior do Gemini 1.5 Pro permite-lhe aproveitar mais exemplos no contexto do que os modelos GPT.
Os investigadores descobriram que, no planeamento de viagens, o aumento do número de disparos de 1 para 800 melhora a precisão do Gemini Pro 1.5 de 2,7% para 39,9%.
O jornal Estes resultados mostram a promessa de um planeamento em contexto, em que as capacidades de contexto longo permitem aos LLM tirar partido de mais contexto para melhorar o planeamento".
Um resultado estranho foi o facto de o GPT-4o ser realmente mau no planeamento de viagens. Os investigadores descobriram que tinha dificuldade em "compreender e respeitar a conetividade dos voos e as restrições de datas de viagem".
Outro resultado estranho foi o facto de a auto-correção ter levado a uma queda significativa do desempenho de todos os modelos. Quando os modelos foram convidados a verificar o seu trabalho e a fazer correcções, cometeram mais erros.
Curiosamente, os modelos mais fortes, como o GPT-4 e o Gemini 1.5 Pro, sofreram perdas maiores do que o GPT-3.5 quando se auto-corrigiram.
A IA agêntica é uma perspetiva empolgante e já estamos a ver alguns casos de utilização prática em Microsoft Copilot agentes.
Mas os resultados dos testes de referência do NATURAL PLAN mostram que ainda temos um longo caminho a percorrer até que a IA possa lidar com um planeamento mais complexo.
Os investigadores da DeepMind concluíram que "o PLANO NATURAL é muito difícil de resolver pelos modelos mais avançados".
Parece que a IA ainda não vai substituir os agentes de viagens e os assistentes pessoais.



