

Apesar dos rápidos avanços nos LLMs, a nossa compreensão de como estes modelos lidam com entradas mais longas continua a ser fraca.
Mosh Levy, Alon Jacoby e Yoav Goldberg, da Universidade de Bar-Ilan e do Allen Institute for AI, investigaram a forma como o desempenho dos modelos de linguagem de grande dimensão (LLM) varia com as alterações no comprimento do texto de entrada que lhes é dado para processar.
Desenvolveram uma estrutura de raciocínio especificamente para este fim, permitindo-lhes dissecar a influência do comprimento da entrada no raciocínio LLM num ambiente controlado.
O quadro de perguntas propunha diferentes versões da mesma pergunta, cada uma contendo a informação necessária para responder à pergunta, complementada com texto adicional irrelevante de diferentes comprimentos e tipos.
Isto permite isolar o comprimento da entrada como uma variável, assegurando que as alterações no desempenho do modelo podem ser atribuídas diretamente ao comprimento da entrada.
Principais conclusões
Levy, Jacoby e Goldberg descobriram que os LLMs exibem um declínio notável no desempenho do raciocínio em comprimentos de entrada muito abaixo do que os programadores afirmam que eles podem lidar. Eles documentaram as suas descobertas neste estudo.
O declínio foi observado de forma consistente em todas as versões do conjunto de dados, indicando um problema sistémico com o tratamento de entradas mais longas e não um problema relacionado com amostras de dados ou arquitecturas de modelos específicos.
Como descrevem os investigadores, "as nossas descobertas mostram uma degradação notável no desempenho de raciocínio dos LLMs com comprimentos de entrada muito mais curtos do que o seu máximo técnico. Mostramos que a tendência de degradação aparece em todas as versões do nosso conjunto de dados, embora com intensidades diferentes."

Além disso, o estudo destaca o facto de as métricas tradicionais, como a perplexidade, normalmente utilizadas para avaliar os LLM, não estarem correlacionadas com o desempenho dos modelos em tarefas de raciocínio que envolvem entradas longas.
Uma análise mais aprofundada revelou que a degradação do desempenho não dependia apenas da presença de informação irrelevante (padding), mas era observada mesmo quando esse padding consistia em informação relevante duplicada.
Quando mantemos os dois vãos principais juntos e adicionamos texto à volta deles, a precisão já diminui. Se introduzirmos parágrafos entre os intervalos, os resultados baixam muito mais. A queda ocorre tanto quando os textos que adicionamos são semelhantes aos textos da tarefa, como quando são completamente diferentes. 3/7 pic.twitter.com/c91l9uzyme
- Mosh Levy (@mosh_levy) 26 de fevereiro de 2024
Isto sugere que o desafio para os LLMs reside na filtragem do ruído e no processamento inerente de sequências de texto mais longas.
Ignorar instruções
Uma área crítica do modo de falha destacada no estudo é a tendência dos LLMs de ignorar instruções embutidas na entrada à medida que o comprimento da entrada aumenta.
Por vezes, os modelos também geravam respostas que indicavam incerteza ou falta de informação suficiente, como "Não há informação suficiente no texto", apesar de toda a informação necessária.
De um modo geral, os LLM parecem ter dificuldade em dar prioridade e concentrar-se em informações importantes, incluindo instruções directas, à medida que o comprimento dos dados aumenta.
Apresentar enviesamentos nas respostas
Outra questão notável foi o aumento dos enviesamentos nas respostas dos modelos à medida que as entradas se tornavam mais longas.
Especificamente, os LLMs foram tendenciosos a responder "Falso" à medida que o comprimento da entrada aumentava. Este enviesamento indica uma distorção na estimativa de probabilidades ou nos processos de tomada de decisão no modelo, possivelmente como um mecanismo de defesa em resposta ao aumento da incerteza devido a comprimentos de entrada mais longos.
A tendência para favorecer as respostas "falsas" também pode refletir um desequilíbrio subjacente nos dados de treino ou um artefacto do processo de treino dos modelos, em que as respostas negativas podem estar sobre-representadas ou associadas a contextos de incerteza e ambiguidade.
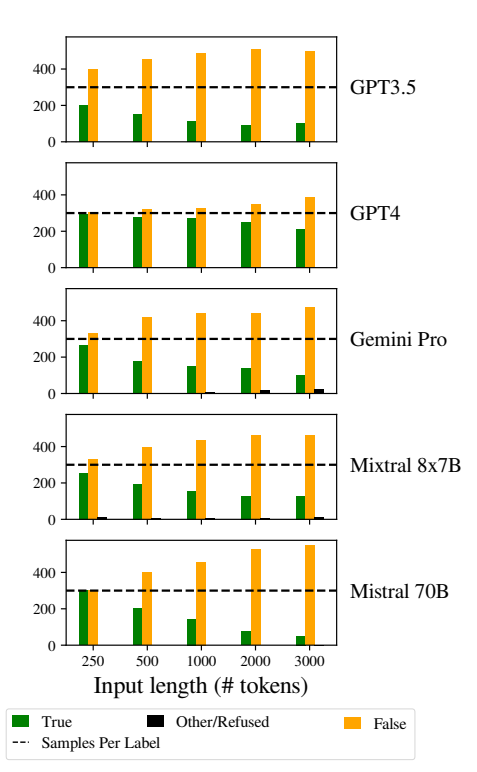
Este enviesamento afecta a exatidão dos resultados dos modelos e suscita preocupações quanto à fiabilidade e justiça dos MLT em aplicações que requerem uma compreensão diferenciada e imparcialidade.
A implementação de estratégias robustas de deteção e atenuação de enviesamentos durante as fases de treino e afinação do modelo é essencial para reduzir enviesamentos injustificados nas respostas do modelo.
Essegurar que os conjuntos de dados de treino são diversificados, equilibrados e representativos de uma vasta gama de cenários também pode ajudar a minimizar os enviesamentos e a melhorar a generalização do modelo.
Este facto contribui para outros estudos recentes que, da mesma forma, evidenciam questões fundamentais no funcionamento dos LLM, levando a uma situação em que essa "dívida técnica" pode ameaçar a funcionalidade e a integridade do modelo ao longo do tempo.



