

A OpenAI não lançou quaisquer novos modelos no seu evento Dev Day, mas as novas funcionalidades da API irão entusiasmar os programadores que pretendam utilizar os seus modelos para criar aplicações poderosas.
A OpenAI tem tido umas semanas difíceis com a sua CTO, Mira Murati, e outros investigadores principais a juntarem-se à lista cada vez maior de antigos funcionários. A empresa está sob pressão crescente de outros modelos emblemáticos, incluindo modelos de código aberto que oferecem aos programadores opções mais baratas e altamente capazes.
As novas funcionalidades que a OpenAI revelou foram a API em tempo real (em versão beta), o aperfeiçoamento da visão e as ferramentas de aumento da eficiência, como o armazenamento em cache e a destilação de modelos.
API em tempo real
A API em tempo real é a nova funcionalidade mais interessante, embora em versão beta. Permite que os programadores criem experiências de voz para voz de baixa latência nas suas aplicações sem utilizar modelos separados para reconhecimento de voz e conversão de texto em voz.
Com esta API, os programadores podem agora criar aplicações que permitem conversas em tempo real com IA, como assistentes de voz ou ferramentas de aprendizagem de línguas, tudo através de uma única chamada de API. Não é exatamente a experiência perfeita que o Modo de Voz Avançado do GPT-4o oferece, mas está perto.
No entanto, não é barato, custando aproximadamente $0,06 por minuto de entrada de áudio e $0,24 por minuto de saída de áudio.
A nova API em tempo real da OpenAI é incrível...
Vejam-no encomendar 400 morangos ligando para a loja com o twillio. Tudo com voz. 🍓🎤 pic.twitter.com/J2BBoL9yFv
- Ty (@FieroTy) 1 de outubro de 2024
Afinação da visão
O ajuste fino da visão dentro da API permite aos programadores melhorar a capacidade dos seus modelos para compreender e interagir com imagens. Ao afinar o GPT-4o utilizando imagens, os programadores podem criar aplicações que se destacam em tarefas como a pesquisa visual ou a deteção de objectos.
Esta funcionalidade já está a ser aproveitada por empresas como a Grab, que melhorou a precisão do seu serviço de mapas, afinando o modelo para reconhecer sinais de trânsito a partir de imagens ao nível da rua.
A OpenAI também deu um exemplo de como o GPT-4o poderia gerar conteúdo adicional para um sítio Web depois de ser ajustado para corresponder estilisticamente ao conteúdo existente do sítio.
Cache de prompts
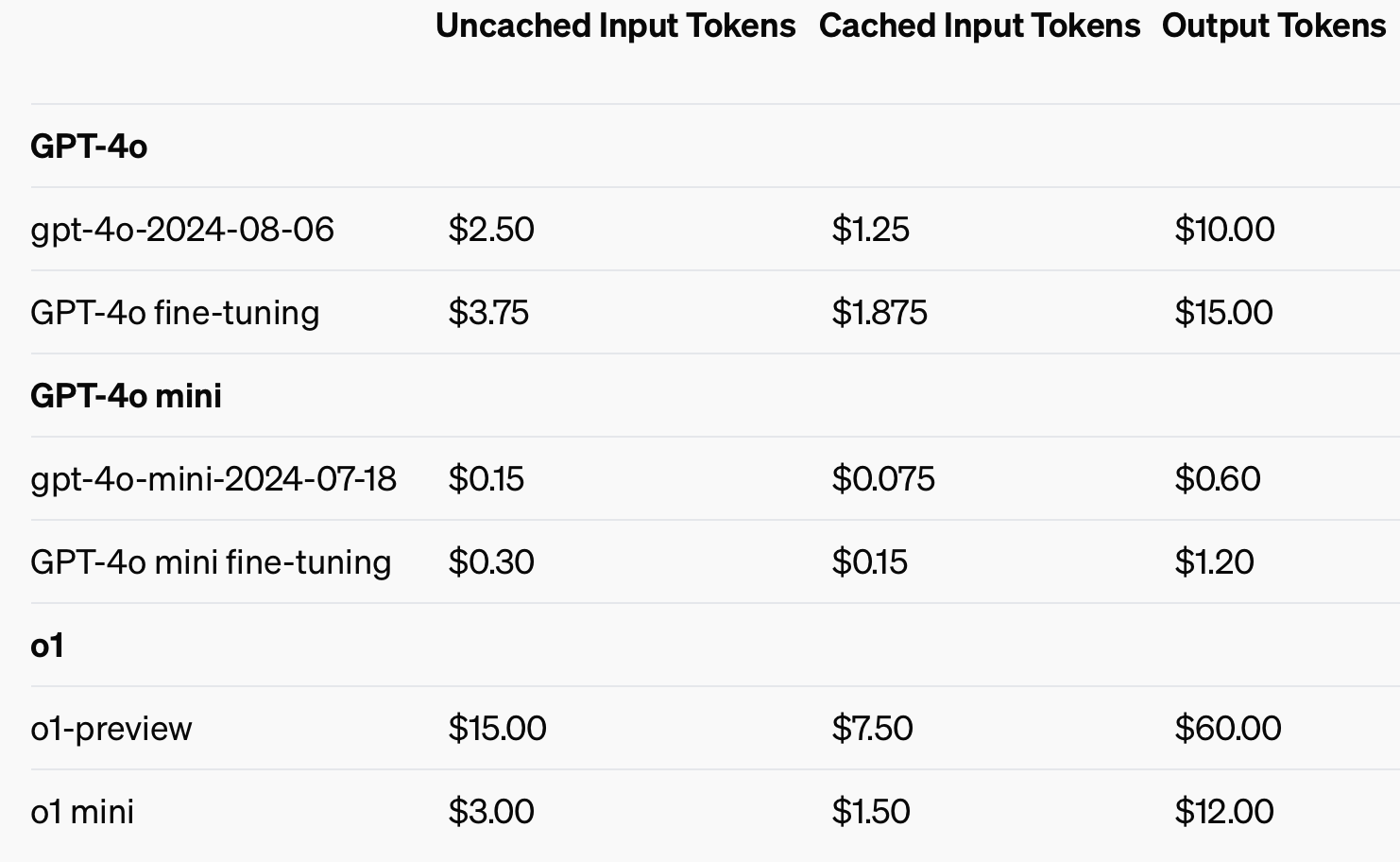
Para melhorar a eficiência dos custos, a OpenAI introduziu o prompt caching, uma ferramenta que reduz o custo e a latência das chamadas API frequentemente utilizadas. Ao reutilizar entradas processadas recentemente, os programadores podem reduzir os custos em 50% e reduzir os tempos de resposta. Esta funcionalidade é especialmente útil para aplicações que requerem longas conversas ou contextos repetidos, como chatbots e ferramentas de apoio ao cliente.
A utilização de entradas em cache pode poupar até 50% em custos de fichas de entrada.
Modelo de destilação
A destilação de modelos permite aos programadores afinar modelos mais pequenos e mais económicos, utilizando os resultados de modelos maiores e mais capazes. Trata-se de um fator de mudança porque, anteriormente, a destilação exigia vários passos e ferramentas desconexas, tornando-a num processo moroso e propenso a erros.
Antes da funcionalidade integrada de destilação de modelos da OpenAI, os programadores tinham de orquestrar manualmente diferentes partes do processo, como a geração de dados a partir de modelos maiores, a preparação de conjuntos de dados de afinação e a medição do desempenho com várias ferramentas.
Os programadores podem agora armazenar automaticamente os pares de resultados de modelos maiores como o GPT-4o e utilizar esses pares para afinar modelos mais pequenos como o GPT-4o-mini. Todo o processo de criação de conjuntos de dados, afinação e avaliação pode ser efectuado de uma forma mais estruturada, automatizada e eficiente.
O processo de desenvolvimento simplificado, a menor latência e os custos reduzidos farão do modelo GPT-4o da OpenAI uma perspetiva atractiva para os programadores que procuram implementar rapidamente aplicações poderosas. Será interessante ver quais as aplicações que as funcionalidades multimodais tornam possíveis.



