

Os parâmetros de referência estão a ter dificuldade em acompanhar o avanço das capacidades dos modelos de IA e o projeto Humanity's Last Exam quer a sua ajuda para resolver este problema.
O projeto é uma colaboração entre o Centro para a Segurança da IA (CAIS) e a empresa de dados de IA Scale AI. O projeto visa medir o grau de proximidade em relação a sistemas de IA de nível especializado, algo parâmetros de referência existentes não são capazes de o fazer.
A OpenAI e o CAIS desenvolveram o popular benchmark MMLU (Massive Multitask Language Understanding) em 2021. Nessa altura, diz o CAIS, "os sistemas de IA não tinham um desempenho melhor do que o aleatório".
O impressionante desempenho do modelo o1 da OpenAI "destruiu os mais populares benchmarks de raciocínio", de acordo com Dan Hendrycks, diretor executivo do CAIS.
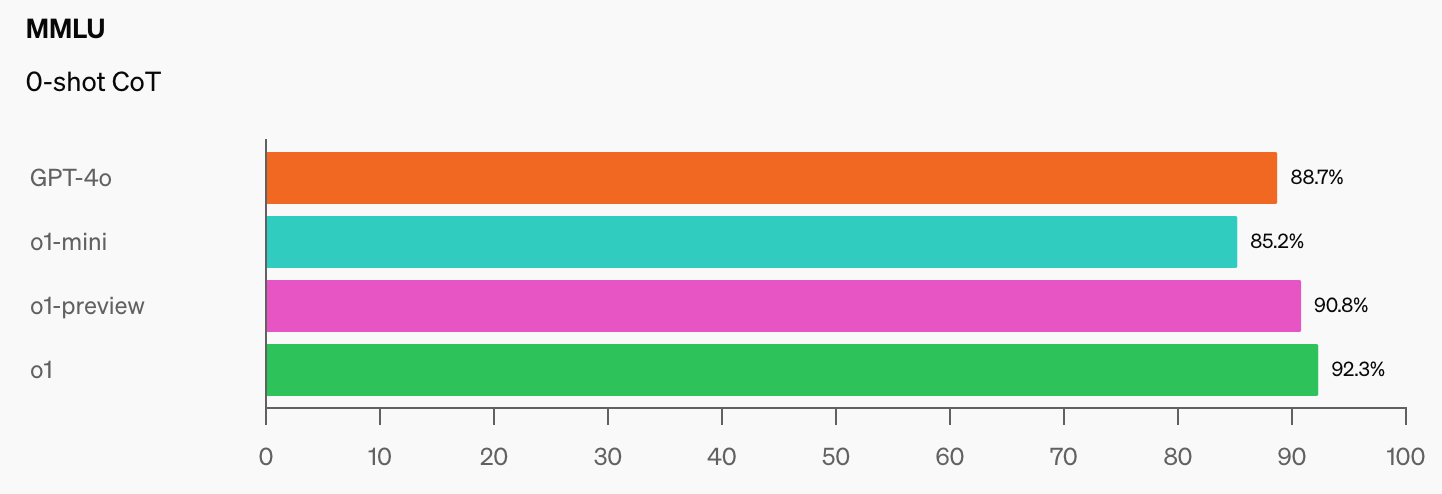
Quando os modelos de IA atingirem 100% no MMLU, como é que os vamos medir? O CAIS afirma que "os testes existentes tornaram-se demasiado fáceis e já não podemos acompanhar bem os desenvolvimentos da IA, ou a distância a que estão de se tornarem especialistas".
Quando se vê o salto nas pontuações de benchmark que o1 adicionou aos já impressionantes números do GPT-4o, não demorará muito até que um modelo de IA vença o MMLU.
Isto é objetivamente verdade. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17 de setembro de 2024
A Humanity's Last Exam está a pedir às pessoas que enviem perguntas que o surpreenderiam genuinamente se um modelo de IA desse a resposta correta. Pretendem perguntas de exame de nível de doutoramento, não do tipo "quantos Rs tem um morango", que engana alguns modelos.
Scale explicou que "à medida que os testes existentes se tornam demasiado fáceis, perdemos a capacidade de distinguir entre os sistemas de IA que podem ter sucesso nos exames de licenciatura e aqueles que podem contribuir verdadeiramente para a investigação de ponta e para a resolução de problemas".
Se tiver uma pergunta original que possa surpreender um modelo avançado de IA, o seu nome poderá ser adicionado como coautor do artigo do projeto e participar num fundo comum de $500.000 que será atribuído às melhores perguntas.
Para dar uma ideia do nível a que o projeto se destina, Scale explicou que "se um estudante universitário selecionado aleatoriamente consegue compreender o que é pedido, é provável que seja demasiado fácil para os LLMs de hoje e de amanhã".
Existem algumas restrições interessantes quanto ao tipo de perguntas que podem ser apresentadas. Não querem nada relacionado com armas químicas, biológicas, radiológicas, nucleares ou armas cibernéticas utilizadas para atacar infra-estruturas críticas.
Se acha que tem uma pergunta que cumpre os requisitos, pode enviá-la aqui.



