

Um estudo da Universidade de Oxford desenvolveu um meio de testar quando os modelos linguísticos estão "inseguros" quanto aos seus resultados e correm o risco de alucinar.
As "alucinações" da IA referem-se a um fenómeno em que os modelos de linguagem de grande dimensão (LLM) geram respostas fluentes e plausíveis que não são verdadeiras ou consistentes.
As alucinações são difíceis - se não mesmo impossíveis - de separar dos modelos de IA. Os criadores de IA como a OpenAI, a Google e a Anthropic admitiram que as alucinações continuarão provavelmente a ser um subproduto da interação com a IA.
Como afirma o Dr. Sebastian Farquhar, um dos autores do estudo, explica numa publicação no blogueOs LLM são muito capazes de dizer a mesma coisa de muitas maneiras diferentes, o que pode tornar difícil perceber quando têm a certeza de uma resposta e quando estão literalmente a inventar alguma coisa".
O Cambridge Dictionary acrescentou mesmo um Definição da palavra relacionada com a IA em 2023 e nomeou-a "Palavra do Ano".
Esta Universidade de Oxford estudo, publicado na Nature, procura responder como podemos detetar quando é mais provável que essas alucinações ocorram.
Introduz um conceito chamado "entropia semântica", que mede a incerteza dos resultados de um LLM ao nível do significado e não apenas das palavras ou frases específicas utilizadas.
Ao calcular a entropia semântica das respostas de um LLM, os investigadores podem estimar a confiança do modelo nos seus resultados e identificar os casos em que é provável que tenha alucinações.
Explicação da entropia semântica em LLMs
A entropia semântica, tal como definida pelo estudo, mede a incerteza ou a inconsistência do significado das respostas de um LLM. Ajuda a detetar quando um LLM pode estar a alucinar ou a gerar informações pouco fiáveis.
Em termos mais simples, a entropia semântica mede o quão "confuso" é o resultado de um LLM.
O LLM fornecerá provavelmente informações fiáveis se o significado dos seus resultados estiver intimamente relacionado e for consistente. Mas se os significados forem dispersos e inconsistentes, isso é um sinal de alerta de que o LLM pode estar a alucinar ou a gerar informações imprecisas.
Eis como funciona:
- Os investigadores incitaram ativamente o LLM a gerar várias respostas possíveis à mesma pergunta. Para o efeito, a pergunta é colocada várias vezes ao LLM, cada vez com uma semente aleatória diferente ou uma ligeira variação na entrada.
- A entropia semântica examina as respostas e agrupa as que têm o mesmo significado subjacente, mesmo que utilizem palavras ou frases diferentes.
- Se o LLM estiver confiante na resposta, suas respostas deverão ter significados semelhantes, resultando em uma pontuação baixa de entropia semântica. Isto sugere que o MLT compreende a informação de forma clara e consistente.
- No entanto, se o MLT estiver incerto ou confuso, suas respostas terão uma variedade maior de significados, alguns dos quais podem ser inconsistentes ou não relacionados à pergunta. Isso resulta em uma alta pontuação de entropia semântica, indicando que o MLT pode ter alucinações ou gerar informações não confiáveis.
Para avaliar a sua eficácia, os investigadores aplicaram a entropia semântica a um conjunto diversificado de tarefas de resposta a perguntas. Isto envolveu testes de referência como perguntas de trivialidades, compreensão de leitura, problemas de palavras e biografias.
De um modo geral, a entropia semântica superou os métodos existentes para detetar quando um LLM era suscetível de gerar uma resposta incorrecta ou inconsistente.
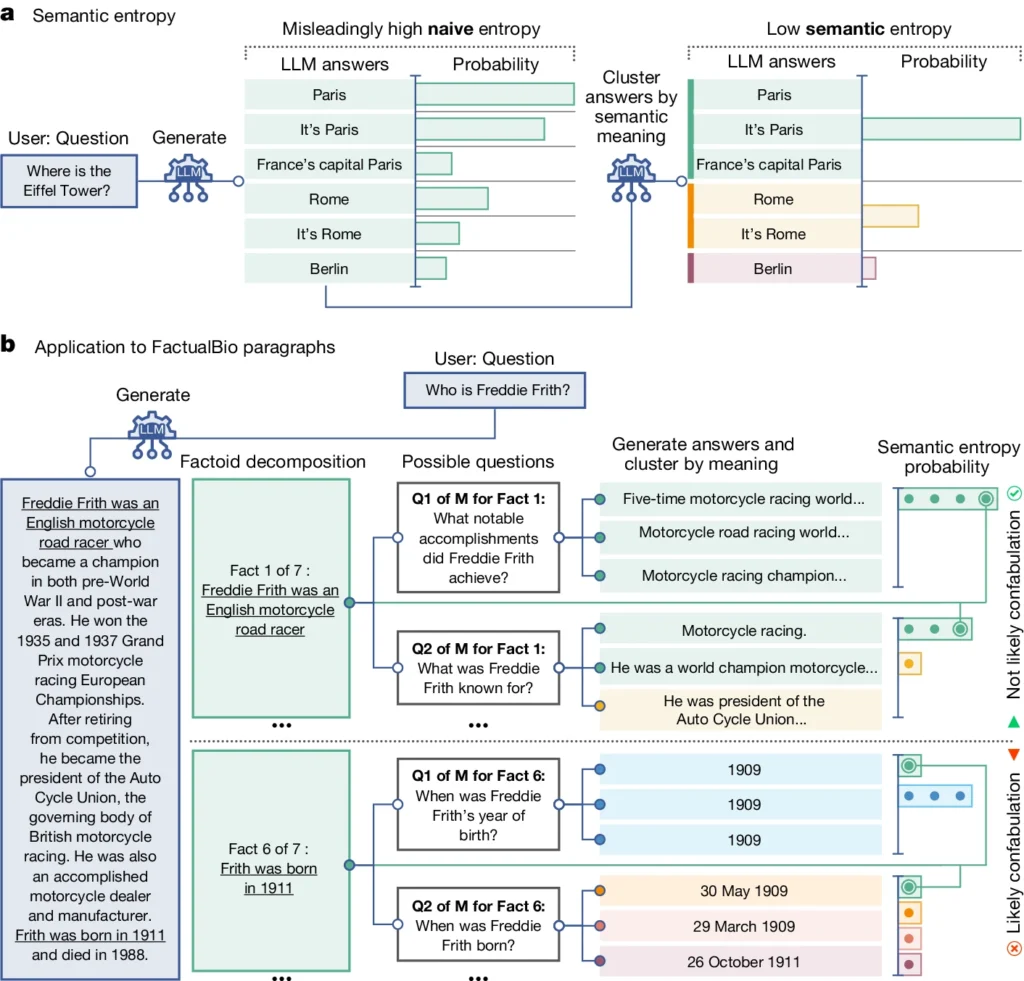
No diagrama acima, é possível ver como alguns pedidos levam o LLM a gerar uma resposta confabulada (imprecisa, alucinatória). Por exemplo, produz um dia e um mês de nascimento para as perguntas na parte inferior do diagrama, quando a informação necessária para as responder não foi fornecida na informação inicial.
Implicações da deteção de alucinações
Este trabalho pode ajudar a explicar as alucinações e a tornar os MLT mais fiáveis e dignos de confiança.
Ao fornecer uma forma de detetar quando um LLM é incerto ou propenso a alucinações, a entropia semântica abre caminho para a utilização destas ferramentas de IA em domínios de grande importância em que a exatidão dos factos é crítica, como os cuidados de saúde, o direito e as finanças.
Resultados errados podem ter impactos potencialmente catastróficos quando influenciam situações de grande importância, como demonstrado por alguns policiamento preditivo falhado e sistemas de saúde.
No entanto, também é importante lembrar que as alucinações são apenas um tipo de erro que os LLMs podem cometer.
Como explica o Dr. Farquhar, "se um LLM cometer erros consistentes, este novo método não os detectará. As falhas mais perigosas da IA surgem quando um sistema faz algo de mau mas está confiante e é sistemático. Ainda há muito trabalho a fazer".
No entanto, o método de entropia semântica da equipa de Oxford representa um grande passo em frente na nossa capacidade de compreender e atenuar as limitações dos modelos linguísticos de IA.
Fornecer um meio objetivo para os detetar aproxima-nos de um futuro em que podemos aproveitar o potencial da IA, assegurando ao mesmo tempo que continua a ser uma ferramenta fiável e digna de confiança ao serviço da humanidade.



