

Anthropic os investigadores identificaram com sucesso milhões de conceitos dentro de Claude Sonnet, um dos seus LLMs avançados.
Os modelos de IA são frequentemente considerados caixas negras, o que significa que não é possível "ver" o seu interior para compreender exatamente como funcionam.
Quando se fornece um input a um LLM, este gera uma resposta, mas o raciocínio por detrás das suas escolhas não é claro.
O seu input entra e o output sai - e mesmo os próprios criadores de IA não compreendem verdadeiramente o que acontece dentro dessa "caixa".
As redes neuronais criam as suas próprias representações internas da informação quando mapeiam os inputs para os outputs durante o treino dos dados. Os blocos de construção deste processo, chamados "activações neuronais", são representados por valores numéricos.
Cada conceito está distribuído por vários neurónios e cada neurónio contribui para representar vários conceitos, o que torna difícil mapear conceitos diretamente para neurónios individuais.
Isto é, em traços gerais, análogo ao nosso cérebro humano. Tal como os nossos cérebros processam os estímulos sensoriais e geram pensamentos, comportamentos e memórias, os biliões, ou mesmo triliões, de processos subjacentes a essas funções permanecem essencialmente desconhecidos para a ciência.
Anthropicestudo de tenta ver o interior da caixa negra da IA com uma técnica chamada "aprendizagem de dicionário".
Isto envolve a decomposição de padrões complexos num modelo de IA em blocos de construção lineares ou "átomos" que fazem sentido intuitivamente para os humanos.
Mapeamento de LLMs com aprendizagem de dicionário
Em outubro de 2023, Anthropic aplicou este método a um pequeno modelo de linguagem "de brincar" e encontrou características coerentes correspondentes a conceitos como texto em maiúsculas, sequências de ADN, apelidos em citações, nomes matemáticos ou argumentos de funções no código Python.
Este último estudo amplia a técnica para que funcione com os actuais modelos linguísticos de IA de maior dimensão, neste caso, Anthropic's Claude 3 Soneto.
Aqui está um passo-a-passo de como o estudo funcionou:
Identificar padrões com a aprendizagem de dicionários
Anthropic utilizou a aprendizagem de dicionários para analisar as activações dos neurónios em vários contextos e identificar padrões comuns.
A aprendizagem de dicionário agrupa estas activações num conjunto mais pequeno de "características" significativas, que representam conceitos de nível superior aprendidos pelo modelo.
Ao identificar estas características, os investigadores podem compreender melhor a forma como o modelo processa e representa a informação.
Extração de características da camada intermédia
Os investigadores centraram-se na camada intermédia de Claude 3.0 Sonnet, que funciona como um ponto crítico na cadeia de processamento do modelo.
A aplicação da aprendizagem de dicionário a esta camada extrai milhões de características que captam as representações internas do modelo e os conceitos aprendidos nesta fase.
A extração de características da camada intermédia permite aos investigadores examinar a compreensão que o modelo tem da informação após processou a entrada antes de gerando o resultado final.
Descobrir conceitos diversos e abstractos
As características extraídas revelaram uma gama alargada de conceitos aprendidos por ClaudeA definição de "cidade" é uma das mais importantes, desde entidades concretas como cidades e pessoas até noções abstractas relacionadas com domínios científicos e sintaxe de programação.
Curiosamente, verificou-se que as características eram multimodais, respondendo a entradas textuais e visuais, o que indica que o modelo pode aprender e representar conceitos em diferentes modalidades.
Além disso, as características multilingues sugerem que o modelo pode compreender conceitos expressos em várias línguas.

Analisar a organização dos conceitos
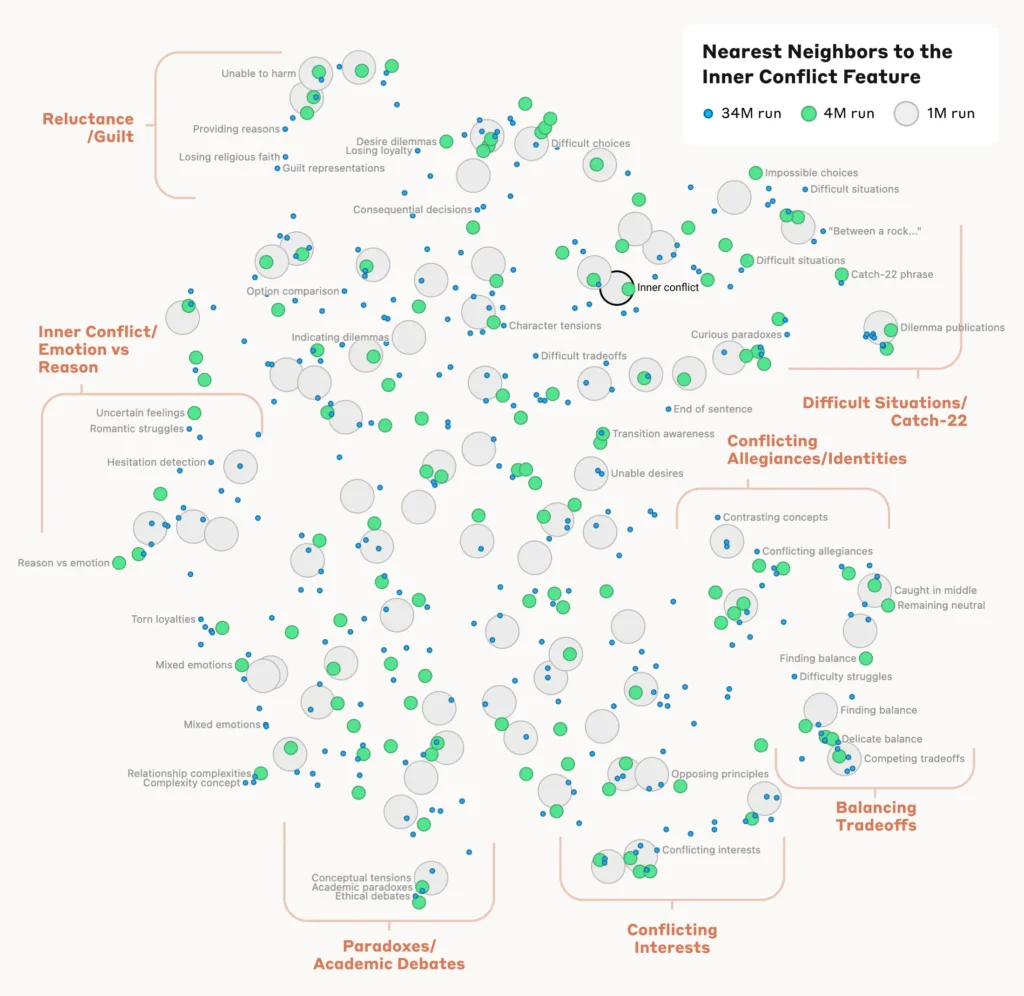
Para compreender como o modelo organiza e relaciona diferentes conceitos, os investigadores analisaram a semelhança entre características com base nos seus padrões de ativação.
Descobriram que as características que representam conceitos relacionados tendem a agrupar-se. Por exemplo, as características associadas a cidades ou disciplinas científicas apresentavam uma maior semelhança entre si do que as características que representavam conceitos não relacionados.
Isto sugere que a organização interna de conceitos do modelo se alinha, até certo ponto, com as intuições humanas sobre relações conceptuais.
Verificação das características
Para confirmar que as características identificadas influenciam diretamente o comportamento e os resultados do modelo, os investigadores realizaram experiências de "orientação de características".
Isto envolveu a amplificação ou supressão selectiva da ativação de características específicas durante o processamento do modelo e a observação do impacto nas suas respostas.
Ao manipular as características individuais, os investigadores puderam estabelecer uma ligação direta entre as características individuais e o comportamento do modelo. Por exemplo, a amplificação de uma caraterística relacionada com uma cidade específica fez com que o modelo gerasse resultados com base na cidade, mesmo em contextos irrelevantes.
Ler o estudo completo aqui.
Porque é que a interpretabilidade é fundamental para a segurança da IA
Anthropicé fundamentalmente relevante para a interpretabilidade da IA e, por extensão, para a segurança.
Compreender como os LLM processam e representam a informação ajuda os investigadores a compreender e a reduzir os riscos. Esta estabelece as bases para o desenvolvimento de sistemas de IA mais transparentes e explicáveis.
Como Anthropic explica: "Esperamos que nós e outros possamos utilizar estas descobertas para tornar os modelos mais seguros. Por exemplo, poderá ser possível utilizar as técnicas aqui descritas para monitorizar os sistemas de IA em relação a determinados comportamentos perigosos (como enganar o utilizador), para os orientar para resultados desejáveis (debiasing) ou para eliminar completamente determinados assuntos perigosos."
A compreensão do comportamento da IA torna-se fundamental à medida que esta se torna omnipresente nos processos críticos de tomada de decisões em domínios como os cuidados de saúde, as finanças e a justiça penal. Também ajuda a descobrir a causa principal de preconceitoalucinações e outros comportamentos não desejados ou imprevisíveis.
Por exemplo, um estudo recente da Universidade de Bona descobriram que as redes neuronais gráficas (GNN) utilizadas para a descoberta de medicamentos se baseiam fortemente na recordação de semelhanças a partir de dados de treino, em vez de aprenderem verdadeiramente novas interacções químicas complexas.
Isto torna difícil compreender como é que estes modelos determinam exatamente os novos compostos de interesse.
No ano passado, o O governo britânico negociou com grandes gigantes da tecnologia como OpenAI e DeepMindA Comissão Europeia está a analisar os processos internos de tomada de decisão dos seus sistemas de IA.
Regulamentos como o Lei da IA da UE irá pressionar as empresas de IA a serem mais transparentes, embora os segredos comerciais pareçam continuar a ser guardados a sete chaves.
AnthropicA investigação da Comissão Europeia oferece um vislumbre do que está dentro da caixa através do "mapeamento" da informação através do modelo.
No entanto, a verdade é que estes modelos são tão vastos que, por Anthropic"Pensamos que é bastante provável que nos faltem ordens de grandeza e que, se quiséssemos obter todas as características - em todas as camadas! - precisaríamos de utilizar muito mais computação do que a computação total necessária para treinar os modelos subjacentes".
Essa é uma questão interessante - a engenharia inversa de um modelo é mais complexa do ponto de vista computacional do que a engenharia do modelo em primeiro lugar.
É uma reminiscência de projectos de neurociência extremamente dispendiosos como o Projeto Cérebro Humano (HBP)que investiu milhares de milhões no mapeamento do nosso próprio cérebro humano, mas que acabou por falhar.
Nunca subestime o que está dentro da caixa negra.



