

Uma equipa de investigadores da Universidade de Nova Iorque fez progressos na descodificação neural da fala, aproximando-nos de um futuro em que as pessoas que perderam a capacidade de falar podem recuperar a voz.
O estudo, publicado em Natureza Inteligência artificialapresenta uma nova estrutura de aprendizagem profunda que traduz com precisão os sinais cerebrais em discurso inteligível.
As pessoas com lesões cerebrais provocadas por acidentes vasculares cerebrais, doenças degenerativas ou traumatismos físicos podem utilizar estes sistemas para comunicar, descodificando os seus pensamentos ou o discurso pretendido a partir de sinais neurais.
O sistema da equipa da NYU envolve um modelo de aprendizagem profunda que mapeia os sinais de electrocorticografia (ECoG) do cérebro para características da fala, como o tom, o volume e outros conteúdos espectrais.
A segunda fase envolve um sintetizador de fala neural que converte as características de fala extraídas num espetrograma audível, que pode depois ser transformado numa forma de onda de fala.
Essa forma de onda pode finalmente ser convertida em fala sintetizada com som natural.
Novo artigo publicado hoje no @NatMachIntellonde mostramos uma descodificação neural robusta para a fala em 48 pacientes. https://t.co/rNPAMr4l68 pic.twitter.com/FG7QKCBVzp
- Adeen Flinker 🇮🇱🇺🇦🎗️ (@adeenflinker) 9 de abril de 2024
Como funciona o estudo
Este estudo envolve o treino de um modelo de IA que pode alimentar um dispositivo de síntese de fala, permitindo que as pessoas com perda de fala falem utilizando impulsos eléctricos do seu cérebro.
Eis como funciona em mais pormenor:
1. Recolha de dados cerebrais
O primeiro passo consiste em recolher os dados em bruto necessários para treinar o modelo de descodificação da fala. Os investigadores trabalharam com 48 participantes que estavam a ser submetidos a uma neurocirurgia para tratamento da epilepsia.
Durante o estudo, foi pedido a estes participantes que lessem centenas de frases em voz alta, enquanto a sua atividade cerebral era registada através de grelhas de ECoG.
Estas grelhas são colocadas diretamente na superfície do cérebro e captam sinais eléctricos das regiões cerebrais envolvidas na produção da fala.
2. Mapeamento dos sinais cerebrais para a fala
Utilizando dados da fala, os investigadores desenvolveram um modelo sofisticado de IA que mapeia os sinais cerebrais registados para características específicas da fala, como o tom, o volume e as frequências únicas que compõem os diferentes sons da fala.
3. Sintetizar o discurso a partir de características
A terceira etapa consiste em converter as características da fala extraídas dos sinais cerebrais em fala audível.
Os investigadores utilizaram um sintetizador de fala especial que utiliza as características extraídas e gera um espetrograma - uma representação visual dos sons da fala.
4. Avaliação dos resultados
Os investigadores compararam o discurso gerado pelo seu modelo com o discurso original falado pelos participantes.
Utilizaram métricas objectivas para medir a semelhança entre os dois e concluíram que o discurso gerado correspondia de perto ao conteúdo e ao ritmo do original.
5. Testes com palavras novas
Para garantir que o modelo consegue lidar com palavras novas que nunca viu antes, algumas palavras foram intencionalmente omitidas durante a fase de treino do modelo e, em seguida, foi testado o desempenho do modelo nestas palavras não vistas.
A capacidade do modelo para descodificar com precisão mesmo palavras novas demonstra o seu potencial para generalizar e lidar com diversos padrões de discurso.
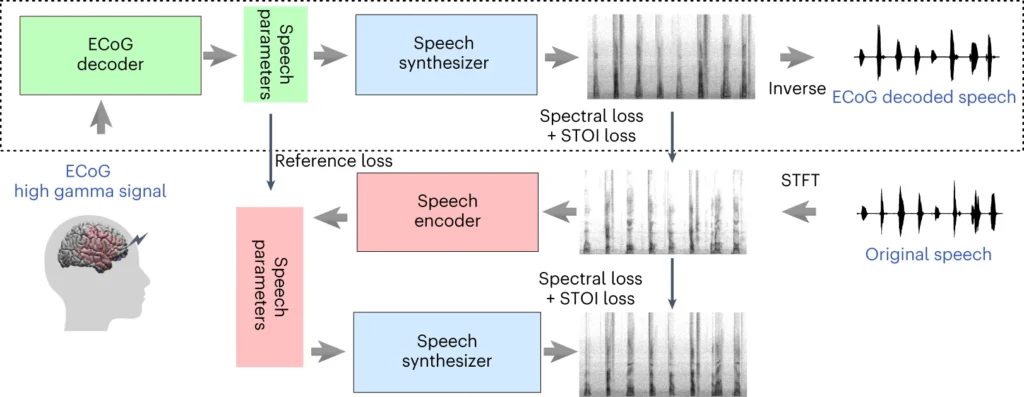
A secção superior do diagrama acima descreve um processo de conversão de sinais cerebrais em fala. Primeiro, um descodificador transforma estes sinais em parâmetros de fala ao longo do tempo. Depois, um sintetizador cria imagens sonoras (espectrogramas) a partir destes parâmetros. Outra ferramenta transforma estas imagens novamente em ondas sonoras.
A secção inferior aborda um sistema que ajuda a treinar o descodificador de sinais do cérebro, imitando a fala. Pega numa imagem sonora, transforma-a em parâmetros de fala e depois utiliza-os para criar uma nova imagem sonora. Esta parte do sistema aprende com os sons reais da fala para os melhorar.
Após o treino, só é necessário o processo superior para transformar os sinais cerebrais em discurso.
Uma das principais vantagens do sistema da NYU é a sua capacidade de obter uma descodificação da fala de alta qualidade sem a necessidade de matrizes de eléctrodos de densidade ultra elevada, que não são práticas para uma utilização a longo prazo.
Na sua essência, oferece uma solução mais leve e portátil.
Outra conquista é a descodificação bem sucedida da fala a partir dos hemisférios esquerdo e direito do cérebro, o que é importante para os doentes com lesões cerebrais num dos lados do cérebro.
Converter pensamentos em discurso utilizando a IA
O estudo da NYU baseia-se em investigação anterior sobre descodificação neural da fala e interfaces cérebro-computador (BCI).
Em 2023, uma equipa da Universidade da Califórnia, em São Francisco, permitiu a um sobrevivente de um AVC paralisado gerar frases a uma velocidade de 78 palavras por minuto, utilizando uma BCI que sintetizava vocalizações e expressões faciais a partir de sinais cerebrais.
Outros estudos recentes exploraram a utilização da IA para interpretar vários aspectos do pensamento humano a partir da atividade cerebral. Os investigadores demonstraram a capacidade de gerar imagens, texto e até música a partir de dados de ressonância magnética e de eletroencefalograma (EEG) retirados do cérebro.
Por exemplo, um estudo da Universidade de Helsínquia utilizaram sinais EEG para orientar uma rede adversária generativa (GAN) na produção de imagens faciais que correspondiam aos pensamentos dos participantes.
A Meta IA também desenvolveu uma técnica para descodificar parcialmente o que alguém estava a ouvir utilizando ondas cerebrais recolhidas de forma não invasiva.
Oportunidades e desafios
O método da NYU utiliza eléctrodos mais amplamente disponíveis e clinicamente viáveis do que os métodos anteriores, tornando-o mais acessível.
Embora isto seja empolgante, há grandes obstáculos a ultrapassar se quisermos assistir a uma utilização generalizada.
Por um lado, a recolha de dados cerebrais de alta qualidade é um esforço complexo e moroso. As diferenças individuais na atividade cerebral dificultam a generalização, o que significa que um modelo treinado para um grupo de participantes pode não funcionar bem para outro.
No entanto, o estudo da NYU representa um passo em frente nesta direção ao demonstrar uma descodificação da fala de elevada precisão utilizando matrizes de eléctrodos mais leves.
Olhando para o futuro, a equipa da NYU pretende aperfeiçoar os seus modelos de descodificação da fala em tempo real, aproximando-nos do objetivo final de permitir conversas naturais e fluentes para indivíduos com deficiências da fala.
Pretendem também adaptar o sistema a dispositivos sem fios implantáveis que possam ser utilizados na vida quotidiana.



