

O Google DeepMind lançou o Gecko, um novo parâmetro de referência para avaliar exaustivamente os modelos de IA de texto para imagem (T2I).
Nos últimos dois anos, vimos geradores de imagens com IA como DALL-E e Meio da viagem tornam-se progressivamente melhores a cada versão lançada.
No entanto, a decisão sobre qual dos modelos subjacentes que estas plataformas utilizam é o melhor tem sido largamente subjectiva e difícil de aferir.
Afirmar de forma generalizada que um modelo é "melhor" do que outro não é assim tão simples. Diferentes modelos destacam-se em vários aspectos da geração de imagens. Um pode ser bom na renderização de texto, enquanto outro pode ser melhor na interação com objectos.
Um dos principais desafios que os modelos T2I enfrentam é o de seguir cada detalhe do pedido e fazer com que estes se reflictam com precisão na imagem gerada.
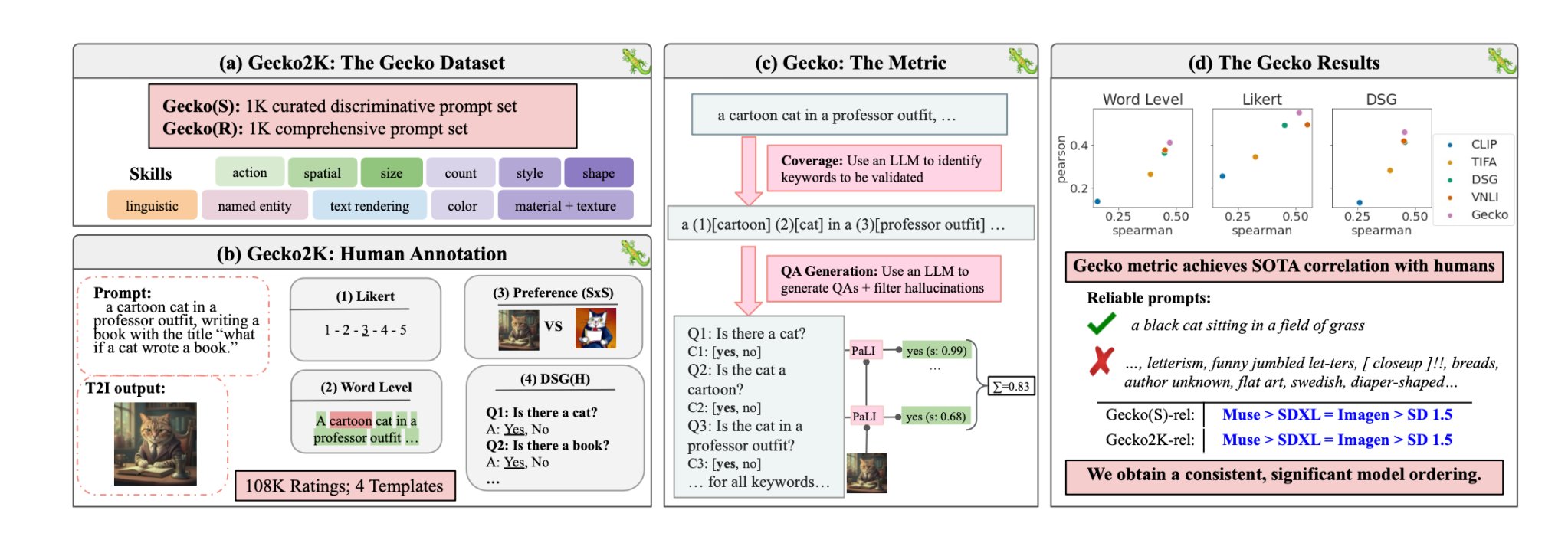
Com o Gecko, o DeepMind os investigadores criaram um referência que avalia as capacidades dos modelos T2I de forma semelhante à dos humanos.
Conjunto de competências
Os investigadores começaram por definir um conjunto de dados abrangente de competências relevantes para a geração de T2I. Estas incluem a compreensão espacial, o reconhecimento de acções, a interpretação de textos, entre outras. Depois, dividiram-nas em subcompetências mais específicas.
Por exemplo, na renderização de texto, as subcompetências podem incluir a renderização de diferentes tipos de letra, cores ou tamanhos de texto.
Em seguida, um LLM foi utilizado para gerar instruções para testar a capacidade do modelo T2I numa competência ou subcompetência específica.
Isto permite aos criadores de um modelo T2I identificar não só as competências que constituem um desafio, mas também o nível de complexidade em que uma competência se torna um desafio para o seu modelo.
Avaliação humana vs. avaliação automática
O Gecko também mede a precisão com que um modelo T2I segue todos os pormenores de uma mensagem. Mais uma vez, foi utilizado um LLM para isolar os principais pormenores de cada mensagem de entrada e, em seguida, gerar um conjunto de perguntas relacionadas com esses pormenores.
Estas perguntas podem ser simples e directas sobre elementos visíveis na imagem (por exemplo, "Há um gato na imagem?") e perguntas mais complexas que testam a compreensão da cena ou as relações entre objectos (por exemplo, "O gato está sentado por cima do livro?").
Em seguida, um modelo de resposta a perguntas visuais (VQA) analisa a imagem gerada e responde às perguntas para verificar a exatidão com que o modelo T2I alinha a sua imagem de saída com um pedido de entrada.
Os investigadores recolheram mais de 100.000 anotações humanas em que os participantes pontuavam uma imagem gerada com base no grau de alinhamento da imagem com critérios específicos.
Foi pedido aos humanos que considerassem um aspeto específico da mensagem de entrada e classificassem a imagem numa escala de 1 a 5, com base na sua adequação à mensagem.
Utilizando as avaliações anotadas por humanos como padrão de ouro, os investigadores conseguiram confirmar que a sua métrica de avaliação automática "está mais bem correlacionada com as classificações humanas do que as métricas existentes para o nosso novo conjunto de dados".
O resultado é um sistema de avaliação comparativa capaz de atribuir números a factores específicos que tornam uma imagem gerada boa ou má.
O Gecko classifica essencialmente a imagem de saída de uma forma que se aproxima da forma como decidimos intuitivamente se estamos ou não satisfeitos com a imagem gerada.
Então, qual é o melhor modelo de texto para imagem?
Em o seu trabalhoNa sua investigação, os investigadores concluíram que o modelo Muse da Google supera o Stable Diffusion 1.5 e o SDXL no benchmark Gecko. Podem ser tendenciosos, mas os números não mentem.



