

Os investigadores da DeepMind e da Universidade de Stanford desenvolveram um agente de IA que verifica os factos dos LLM e permite a avaliação comparativa da factualidade dos modelos de IA.
Mesmo os melhores modelos de IA tendem a alucinar às vezes. Se pedir ao ChatGPT para lhe dar os factos sobre um tópico, quanto mais longa for a resposta, mais provável é que inclua alguns factos que não são verdadeiros.
Que modelos são mais exactos em termos factuais do que outros quando geram respostas mais longas? É difícil dizer porque, até agora, não dispúnhamos de uma referência para medir a factualidade das respostas longas dos LLM.
O DeepMind começou por utilizar o GPT-4 para criar o LongFact, um conjunto de 2.280 perguntas sob a forma de questões relacionadas com 38 tópicos. Estas solicitações suscitam respostas longas do LLM que está a ser testado.
Em seguida, criaram um agente de IA utilizando o GPT-3.5-turbo para utilizar o Google para verificar o grau de factualidade das respostas geradas pelo LLM. Chamaram a este método Search-Augmented Factuality Evaluator (SAFE).
O SAFE começa por dividir a resposta longa do LLM em factos individuais. Em seguida, envia pedidos de pesquisa para o Google Search e analisa a veracidade do facto com base nas informações contidas nos resultados da pesquisa.
Aqui está um exemplo do trabalho de investigação.
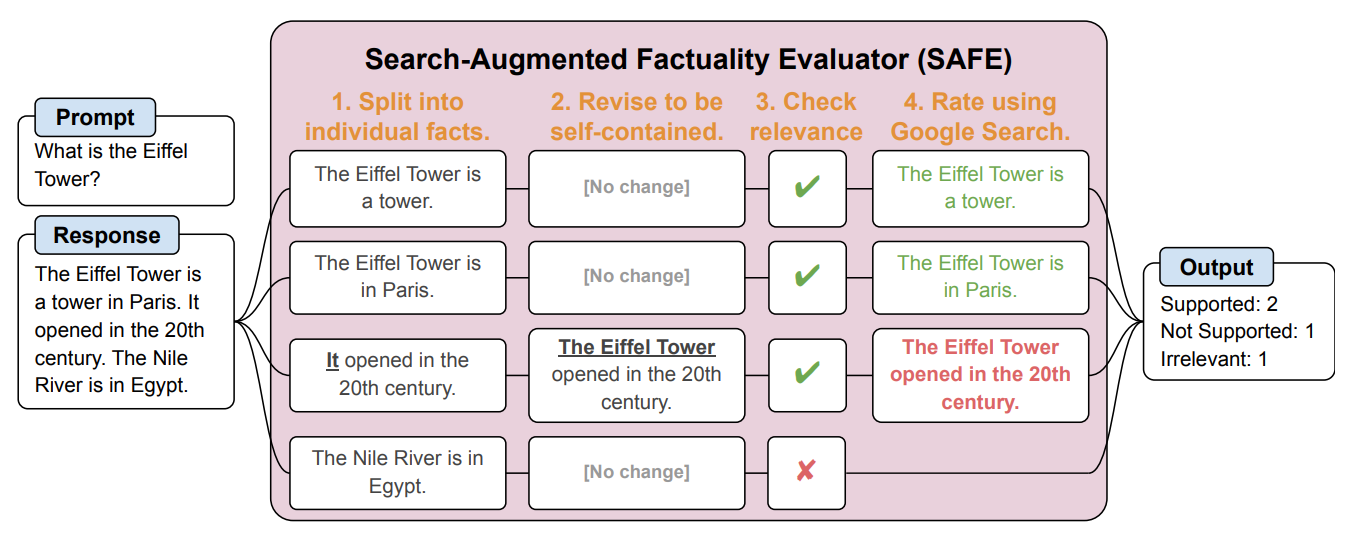
Os investigadores afirmam que o SAFE atinge um "desempenho sobre-humano" em comparação com os anotadores humanos que fazem a verificação dos factos.
O SAFE concordou com 72% das anotações humanas e, nos casos em que diferiu das anotações humanas, foi considerado correto em 76% das vezes. Além disso, foi 20 vezes mais económico do que os anotadores humanos de crowdsourcing. Assim, os LLM são melhores e mais baratos verificadores de factos do que os humanos.
A qualidade da resposta dos LLMs testados foi medida com base no número de factóides na sua resposta, combinado com o grau de factualidade de cada factoide.
A métrica que utilizaram (F1@K) estima o número "ideal" de factos preferido pelos humanos numa resposta. Os testes de referência utilizaram 64 como mediana para K e 178 como máximo.
Simplificando, F1@K é uma medida de "A resposta deu-me tantos factos como eu queria?" combinada com "Quantos desses factos eram verdadeiros?
Qual é o LLM mais factual?
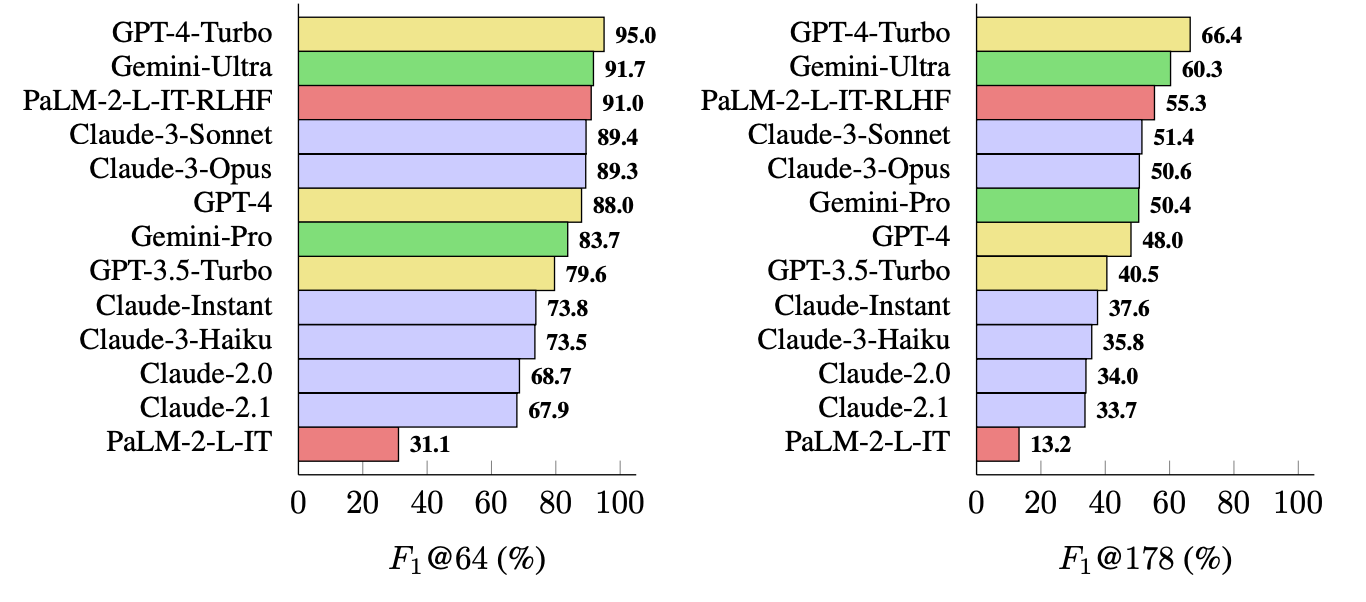
Os investigadores utilizaram o LongFact para solicitar 13 LLMs das famílias Gemini, GPT, Claude e PaLM-2. Em seguida, utilizaram o SAFE para avaliar a factualidade das suas respostas.
O GPT-4-Turbo está no topo da lista como o modelo mais factual ao gerar respostas longas. Foi seguido de perto pelo Gemini-Ultra e pelo PaLM-2-L-IT-RLHF. Os resultados mostraram que os LLM maiores são mais factuais do que os mais pequenos.
O cálculo de F1@K provavelmente entusiasmaria os cientistas de dados, mas, por uma questão de simplicidade, estes resultados de referência mostram o grau de factualidade de cada modelo ao devolver respostas de comprimento médio e mais longas às perguntas.
O SAFE é uma forma barata e eficaz de quantificar a factualidade do LLM. É mais rápido e mais barato do que os humanos na verificação de factos, mas continua a depender da veracidade das informações que o Google apresenta nos resultados da pesquisa.
A DeepMind lançou o SAFE para utilização pública e sugeriu que poderia ajudar a melhorar a factualidade das LLM através de uma melhor pré-treino e afinação. Também poderia permitir que um LLM verificasse os seus factos antes de apresentar o resultado a um utilizador.
A OpenAI ficará satisfeita por ver que a investigação da Google mostra que o GPT-4 bate o Gemini em mais um teste de referência.



