

Os engenheiros da Apple desenvolveram um sistema de IA que resolve referências complexas a entidades no ecrã e a conversas com o utilizador. O modelo leve poderá ser a solução ideal para assistentes virtuais no dispositivo.
Os seres humanos são bons a resolver referências em conversas uns com os outros. Quando usamos termos como "o de baixo" ou "ele", compreendemos a que é que a pessoa se está a referir com base no contexto da conversa e em coisas que podemos ver.
É muito mais difícil para um modelo de IA fazer isto. Os LLMs multimodais, como o GPT-4, são bons a responder a perguntas sobre imagens, mas são dispendiosos de treinar e requerem uma grande sobrecarga de computação para processar cada consulta sobre uma imagem.
Os engenheiros da Apple adoptaram uma abordagem diferente com o seu sistema, denominado ReALM (Reference Resolution As Language Modeling). O jornal vale a pena ler para obter mais pormenores sobre o seu processo de desenvolvimento e teste.
O ReALM utiliza um LLM para processar entidades de conversação, no ecrã e de fundo (alarmes, música de fundo) que constituem as interacções de um utilizador com um agente de IA virtual.
Eis um exemplo do tipo de interação que um utilizador pode ter com um agente de IA.
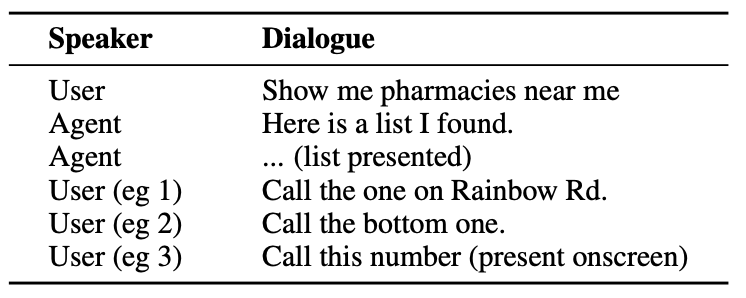
O agente precisa de compreender entidades conversacionais como o facto de que quando o utilizador diz "the one" está a referir-se ao número de telefone da farmácia.
Também precisa de compreender o contexto visual quando o utilizador diz "o de baixo", e é aqui que a abordagem do ReALM difere de modelos como o GPT-4.
O ReALM baseia-se em codificadores a montante para analisar primeiro os elementos no ecrã e as suas posições. Em seguida, a ReALM reconstrói o ecrã em representações puramente textuais, da esquerda para a direita e de cima para baixo.
Em termos simples, utiliza linguagem natural para resumir o ecrã do utilizador.
Agora, quando um utilizador faz uma pergunta sobre algo no ecrã, o modelo de linguagem processa a descrição de texto do ecrã em vez de precisar de utilizar um modelo de visão para processar a imagem no ecrã.
Os investigadores criaram conjuntos de dados sintéticos de entidades de conversação, no ecrã e de fundo e testaram o ReALM e outros modelos para testar a sua eficácia na resolução de referências em sistemas de conversação.
A versão mais pequena do ReALM (80M parâmetros) tem um desempenho comparável ao do GPT-4 e a sua versão maior (3B parâmetros) tem um desempenho substancialmente superior ao do GPT-4.
O ReALM é um modelo pequeno em comparação com o GPT-4. A sua resolução de referência superior torna-o a escolha ideal para um assistente virtual que pode existir no dispositivo sem comprometer o desempenho.
O ReALM não funciona tão bem com imagens mais complexas ou pedidos de utilizadores com mais nuances, mas poderia funcionar bem como assistente virtual no automóvel ou no dispositivo. Imagine se a Siri pudesse "ver" o ecrã do seu iPhone e responder a referências a elementos no ecrã.
A Apple tem sido um pouco lenta a arrancar, mas desenvolvimentos recentes como a sua Modelo MM1 e ReALM mostram que muita coisa está a acontecer à porta fechada.



