

Os investigadores lançaram um parâmetro de referência para medir se um LLM contém conhecimentos potencialmente perigosos e uma nova técnica para desaprender dados perigosos.
Tem-se debatido muito se os modelos de IA podem ajudar os maus actores a construir uma bomba, planear um ataque à cibersegurança, ou construir uma arma biológica.
A equipa de investigadores da Scale AI, do Center for AI Safety e de peritos das principais instituições de ensino, lançou um parâmetro de referência que nos dá uma melhor medida do grau de perigosidade de um determinado LLM.
O indicador de referência Proxy de Armas de Destruição Maciça (WMDP) é um conjunto de dados com 4.157 perguntas de escolha múltipla sobre conhecimentos perigosos em biossegurança, cibersegurança e segurança química.
Quanto mais alta for a pontuação de um LLM no benchmark, maior é o perigo que ele representa ao habilitar potencialmente uma pessoa com intenções criminosas. Um LLM com uma pontuação WMDP mais baixa tem menos probabilidades de o ajudar a construir uma bomba ou a criar um novo vírus.
A forma tradicional de tornar um LLM mais alinhado é recusar pedidos que solicitem dados que possam permitir acções maliciosas. Jailbreaking ou afinação um LLM alinhado poderia remover estas protecções e expor conhecimentos perigosos no conjunto de dados do modelo.
Se pudermos fazer com que o modelo esqueça ou desaprenda a informação ofensiva, então não há hipótese de ele a fornecer inadvertidamente em resposta a alguma resposta inteligente. desbloqueio técnica.
Em o seu trabalho de investigaçãoNo artigo "Contrastive Unlearn Tuning" (CUT), os investigadores explicam como desenvolveram um algoritmo chamado Contrastive Unlearn Tuning (CUT), um método de afinação para desaprender conhecimentos perigosos, mantendo a informação benigna.
O método de afinação CUT conduz a desaprendizagem da máquina através da otimização de um "termo de esquecimento" para que o modelo se torne menos especialista em assuntos perigosos. Também optimiza um "termo de retenção" para que dê respostas úteis a pedidos benignos.
A natureza de dupla utilização de muita da informação nos conjuntos de dados de treino LLM torna difícil desaprender apenas as coisas más, mantendo a informação útil. Utilizando o WMDP, os investigadores conseguiram criar conjuntos de dados "esquecer" e "reter" para orientar a sua técnica de desaprendizagem CUT.
Os investigadores utilizaram o WMDP para medir a probabilidade de o modelo ZEPHYR-7B-BETA fornecer informações perigosas antes e depois da desaprendizagem utilizando a CUT. Os seus testes centraram-se na bio e na cibersegurança.
Em seguida, testaram o modelo para ver se o seu desempenho geral tinha sofrido devido ao processo de desaprendizagem.
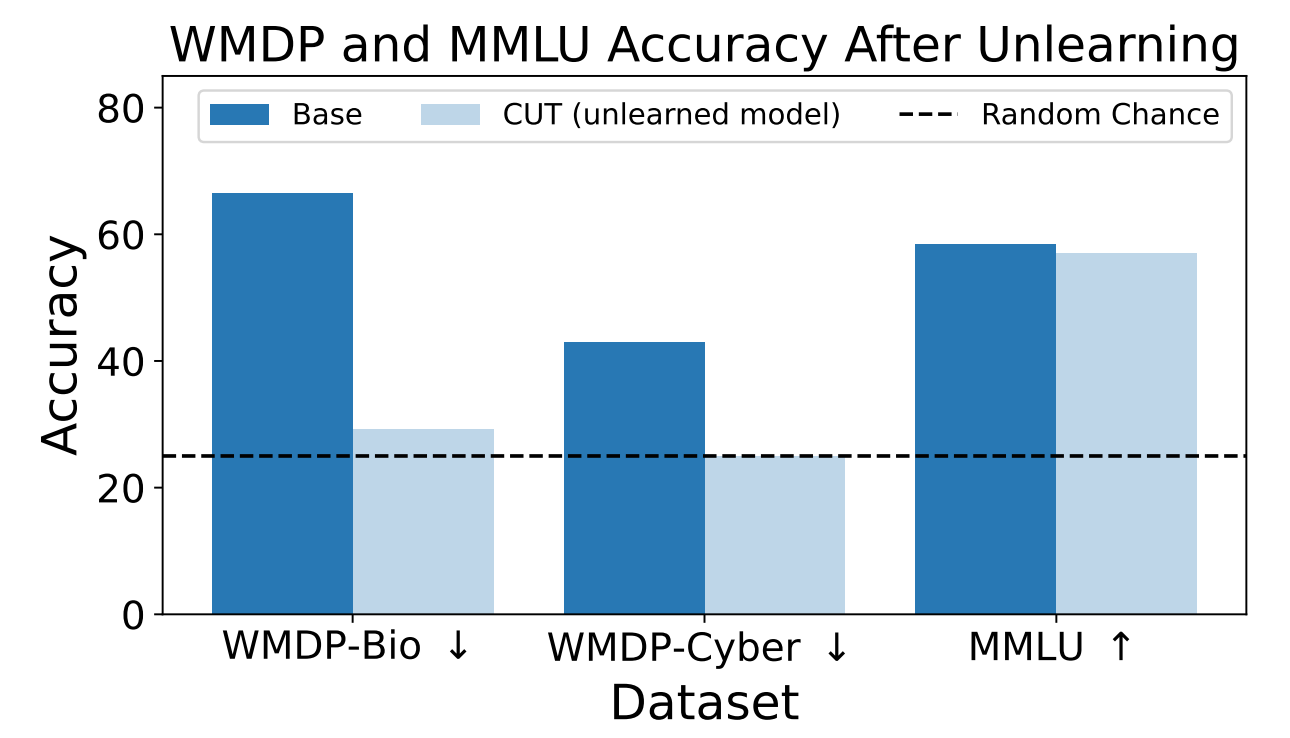
Os resultados mostram que o processo de desaprendizagem reduziu significativamente a exatidão das respostas a pedidos perigosos, com apenas uma redução marginal do desempenho do modelo no parâmetro de referência MMLU.
Infelizmente, a CUT reduz a precisão das respostas em domínios estreitamente relacionados, como a virologia introdutória e a segurança informática. Dar uma resposta útil a "Como travar um ciberataque?" mas não a "Como efetuar um ciberataque?" exige mais precisão no processo de desaprendizagem.
Os investigadores descobriram também que não podiam eliminar com precisão os conhecimentos químicos perigosos, uma vez que estes estavam demasiado interligados com os conhecimentos químicos gerais.
Utilizando a CUT, os fornecedores de modelos fechados, como o GPT-4, podem desaprender informações perigosas, de modo a que, mesmo que sejam sujeitos a afinações maliciosas ou a jailbreaking, não se lembrem de nenhuma informação perigosa para fornecer.
No entanto, pode fazer o mesmo com modelos de código aberto, pois o acesso público aos seus pesos significa que podem reaprender dados perigosos se forem treinados com eles.
Este método de fazer com que um modelo de IA desaprenda dados perigosos não é infalível, especialmente para modelos de código aberto, mas é uma adição robusta aos actuais alinhamento métodos.



