

A Apple ainda não lançou oficialmente um modelo de IA, mas um novo documento de investigação dá uma ideia do progresso da empresa no desenvolvimento de modelos com capacidades multimodais de ponta.
O jornal, intitulado "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", apresenta a família de MLLMs da Apple denominada MM1.
O MM1 apresenta capacidades impressionantes na legendagem de imagens, na resposta a perguntas visuais (VQA) e na inferência de linguagem natural. Os investigadores explicam que a escolha cuidadosa dos pares imagem-legenda lhes permitiu obter resultados superiores, especialmente em cenários de aprendizagem com poucas imagens.
O que distingue o MM1 de outros MLLMs é a sua capacidade superior de seguir instruções em várias imagens e de raciocinar sobre as cenas complexas que lhe são apresentadas.
Os modelos MM1 contêm até 30B parâmetros, o que é três vezes mais do que o GPT-4V, o componente que dá ao GPT-4 da OpenAI as suas capacidades de visão.
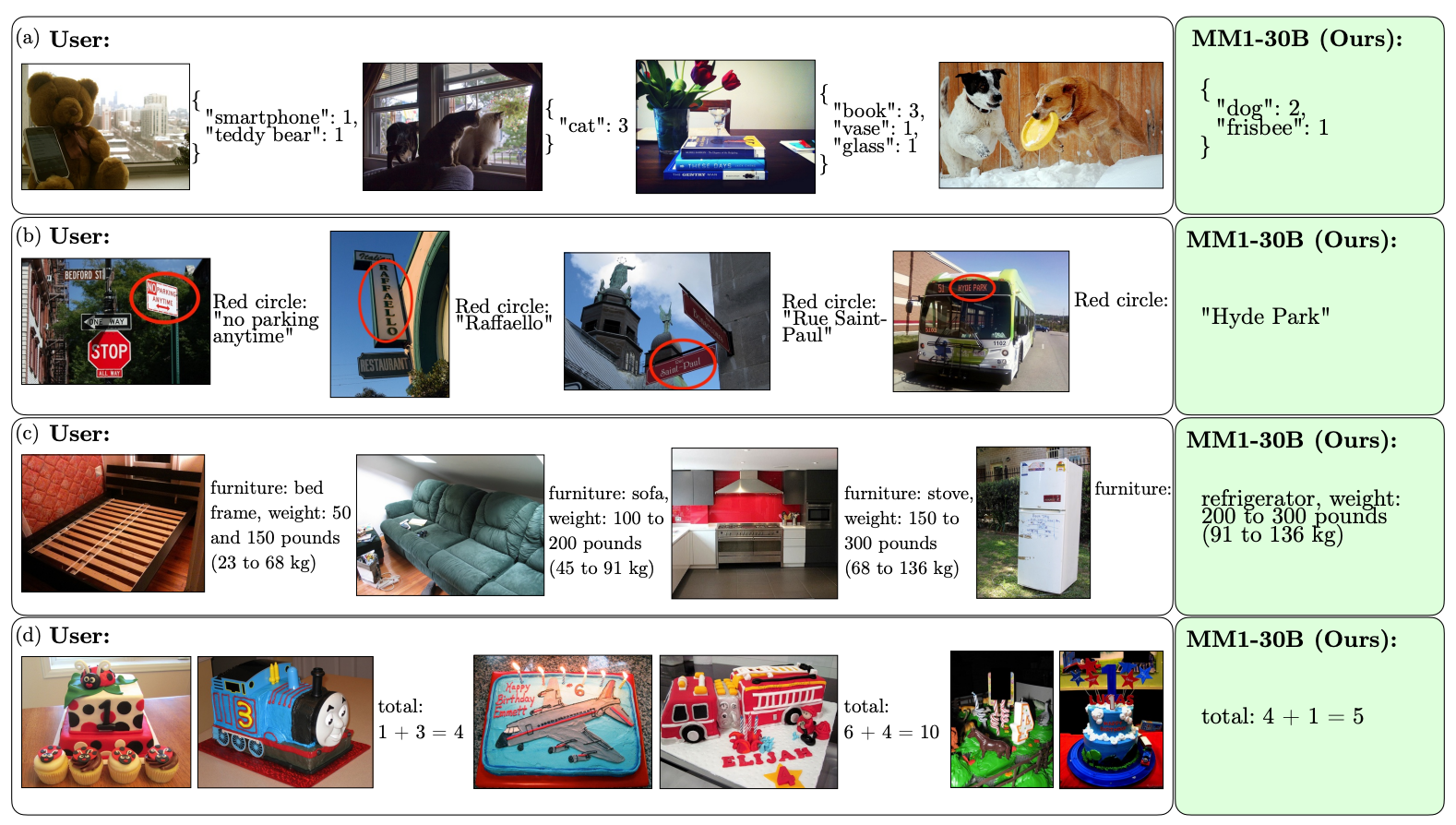
Eis alguns exemplos das capacidades de VQA da MM1.

A MM1 foi submetida a um pré-treino multimodal em grande escala num "conjunto de dados de 500M documentos de texto-imagem intercalados, contendo 1B imagens e 500B tokens de texto".
A escala e a diversidade da sua pré-treino permitem à MM1 efetuar previsões impressionantes no contexto e seguir a formatação personalizada com um pequeno número de exemplos de poucos disparos. Aqui estão exemplos de como o MM1 aprende a saída e o formato desejados a partir de apenas 3 exemplos.
Para criar modelos de IA capazes de "ver" e raciocinar, é necessário um conetor visão-linguagem que traduza imagens e linguagem numa representação unificada que o modelo possa utilizar para processamento posterior.
Os investigadores descobriram que a conceção do conetor visão-linguagem era um fator menos importante para o desempenho do MM1. Curiosamente, foi a resolução da imagem e o número de símbolos de imagem que tiveram o maior impacto.
É interessante ver como a Apple tem estado aberta a partilhar a sua investigação com a comunidade de IA em geral. Os investigadores afirmam que "neste artigo, documentamos o processo de construção do MLLM e tentamos formular lições de design, que esperamos que sejam úteis para a comunidade".
Os resultados publicados irão provavelmente informar a direção que outros criadores de MMLM tomam relativamente à arquitetura e às escolhas de dados de pré-treino.
Ainda não se sabe exatamente como é que os modelos MM1 serão implementados nos produtos da Apple. Os exemplos publicados das capacidades da MM1 sugerem que a Siri se tornará muito mais inteligente quando aprender a ver.



