
O rastreio de pacientes para encontrar participantes adequados para ensaios clínicos é uma tarefa trabalhosa, dispendiosa e propensa a erros, mas a IA poderá em breve resolver esse problema.
Uma equipa de investigadores do Brigham and Women's Hospital, da Harvard Medical School e do Mass General Brigham Personalized Medicine realizou um estudo para verificar se um modelo de IA poderia processar registos médicos para encontrar candidatos a ensaios clínicos adequados.
Utilizaram o GPT-4V, o LLM da OpenAI com processamento de imagem, possibilitado pela Retrieval-Augmented Generation (RAG) para processar os registos de saúde electrónicos (EHR) e as notas clínicas dos potenciais candidatos.
Os LLMs são pré-treinados usando um conjunto de dados fixo e só podem responder a perguntas com base nesses dados. A RAG é uma técnica que permite que uma LLM recupere dados de fontes de dados externas, como a Internet ou documentos internos de uma organização.
Quando os participantes são seleccionados para um ensaio clínico, a sua adequação é determinada por uma lista de critérios de inclusão e exclusão. Normalmente, isto implica que uma equipa formada vasculhe os registos electrónicos de centenas ou milhares de doentes para encontrar aqueles que correspondem aos critérios.
Os investigadores recolheram dados de um ensaio que tinha como objetivo recrutar doentes com insuficiência cardíaca sintomática. Utilizaram esses dados para ver se o GPT-4V com RAG podia fazer o trabalho de forma mais eficiente do que a equipa do estudo, mantendo a precisão.
Os dados estruturados nos registos clínicos electrónicos dos potenciais candidatos podem ser utilizados para determinar 5 de 6 critérios de inclusão e 5 de 17 critérios de exclusão para o ensaio clínico. Essa é a parte fácil.
Os restantes 13 critérios tiveram de ser determinados através da interrogação de dados não estruturados nas notas clínicas de cada doente, que é a parte trabalhosa em que os investigadores esperavam que a IA pudesse ajudar.
🔍Pode @Microsoft @Azure @OpenAI's #GPT4 tem melhor desempenho do que um humano na seleção de ensaios clínicos? Colocámos esta questão no nosso estudo mais recente e estou extremamente entusiasmado por partilhar os nossos resultados na pré-impressão:https://t.co/lhOPKCcudP
A integração da GPT4 nos ensaios clínicos não é...- Ozan Unlu (@OzanUnluMD) 9 de fevereiro de 2024
Resultados
Os investigadores começaram por obter avaliações estruturadas realizadas pela equipa do estudo e notas clínicas relativas aos últimos dois anos.
Desenvolveram um fluxo de trabalho para um sistema de resposta a perguntas com base em notas clínicas, alimentado pela arquitetura RAG e pelo GPT-4V, e chamaram a este fluxo de trabalho RECTIFIER (RAG-Enabled Clinical Trial Infrastructure for Inclusion Exclusion Review).
Foram utilizadas notas de 100 doentes como conjunto de dados de desenvolvimento, 282 doentes como conjunto de dados de validação e 1894 doentes como conjunto de teste.
Um médico especialista efectuou uma análise cega dos processos dos doentes para responder às questões de elegibilidade e determinar as respostas "padrão de ouro". Estas foram depois comparadas com as respostas da equipa do estudo e do RECTIFIER com base nos seguintes critérios:
- Sensibilidade - A capacidade de um teste para identificar corretamente os doentes que são elegíveis para o ensaio (verdadeiros positivos).
- Especificidade - A capacidade de um teste para identificar corretamente os doentes que não são elegíveis para o ensaio (verdadeiros negativos).
- Exatidão - A proporção global de classificações correctas (tanto verdadeiros positivos como verdadeiros negativos).
- Coeficiente de correlação de Matthews (MCC) - Uma métrica utilizada para medir a eficácia do modelo na seleção ou exclusão de uma pessoa. Um valor de 0 é o mesmo que lançar uma moeda ao ar e 1 representa acertar 100% das vezes.
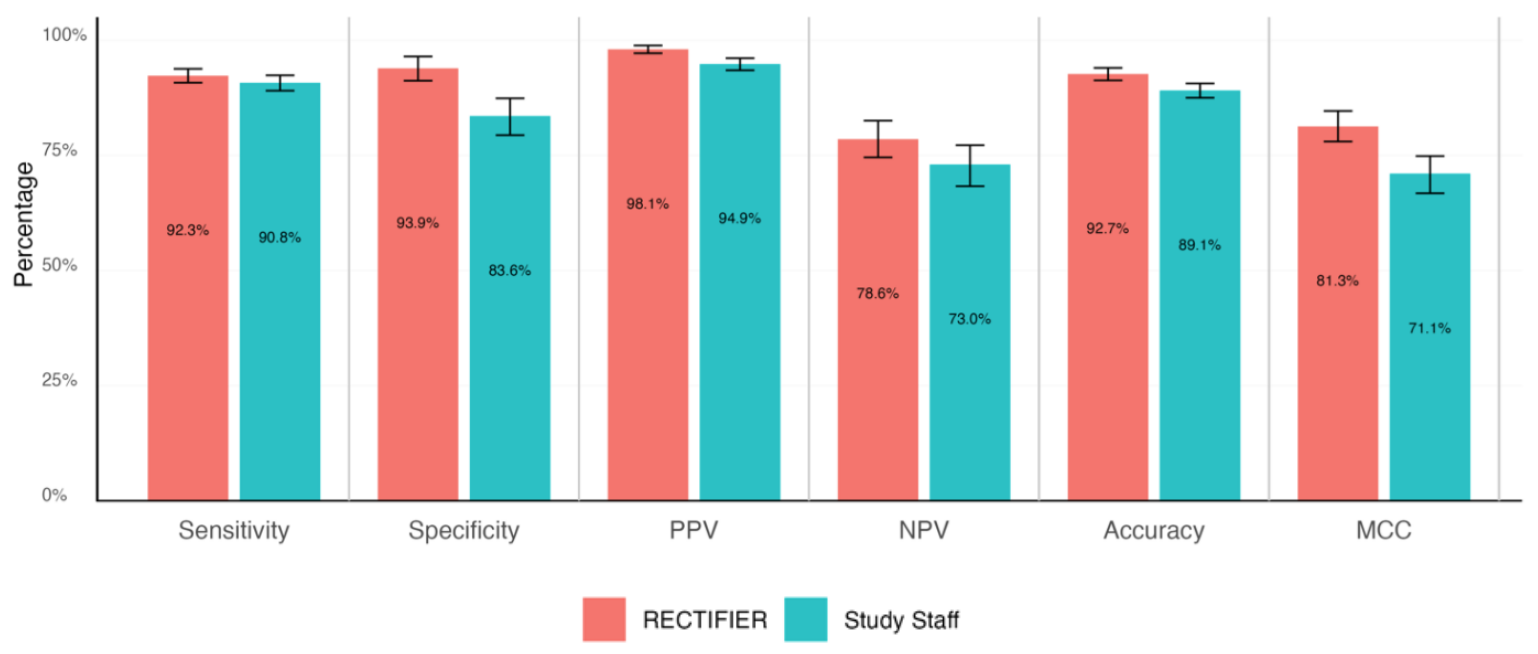
O RECTIFIER teve um desempenho tão bom, e nalguns casos melhor, do que a equipa do estudo. Provavelmente, o resultado mais significativo do estudo foi a comparação de custos.
Embora não tenham sido indicados valores para a remuneração da equipa do estudo, deve ter sido significativamente superior ao custo da utilização do GPT-4V, que variou entre $0,02 e $0,10 por doente. A utilização de IA para avaliar um conjunto de 1000 potenciais candidatos demoraria uma questão de minutos e custaria cerca de $100.
Os investigadores concluíram que a utilização de um modelo de IA como o GPT-4V com RAG pode manter ou melhorar a exatidão na identificação de candidatos a ensaios clínicos e fazê-lo de forma mais eficiente e muito mais barata do que utilizar pessoal humano.
Os investigadores referiram a necessidade de cautela na entrega de cuidados médicos a sistemas automatizados, mas parece que a IA fará um trabalho melhor do que nós, se for corretamente orientada.



