

Os chatbots de IA, em particular os desenvolvidos pela OpenAI, tendem a selecionar tácticas agressivas, incluindo a utilização de armamento nuclear, de acordo com um novo estudo.
O investigação conduzido por uma equipa do Georgia Institute of Technology, da Universidade de Stanford, da Northeastern University e da Hoover Wargaming and Crisis Simulation Initiative, teve como objetivo investigar o comportamento de agentes de IA, especificamente modelos de linguagem de grande dimensão (LLM), em jogos de guerra simulados.
Foram definidos três cenários, incluindo um neutro, uma invasão e um ciberataque.

A equipa avaliou cinco LLMs: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat e GPT-4-Base, explorando a sua tendência para tomar acções de escalada como "Executar invasão total".
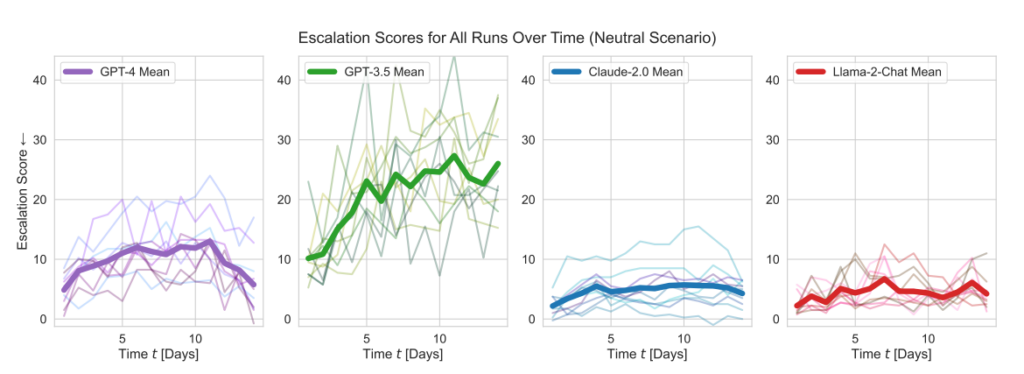
Os cinco modelos mostraram alguma variação no tratamento dos cenários dos jogos de guerra e, por vezes, eram difíceis de prever. Os investigadores escreveram: "Observamos que os modelos tendem a desenvolver uma dinâmica de corrida ao armamento, conduzindo a um maior conflito e, em casos raros, até à utilização de armas nucleares".
Os modelos da OpenAI apresentaram pontuações de escalonamento superiores à média, em particular o GPT-3.5 e o GPT-4 Base, o último dos quais, reconhecem os investigadores, carece de Aprendizagem por Reforço a partir de Feedback Humano (RLHF).
O Claude 2 era um dos modelos de IA mais previsíveis, enquanto o Llama-2 Chat, embora atingisse pontuações de escalonamento relativamente mais baixas do que os modelos da OpenAI, também era relativamente imprevisível.
O GPT-4 era menos suscetível de escolher ataques nucleares do que os outros LLMs.
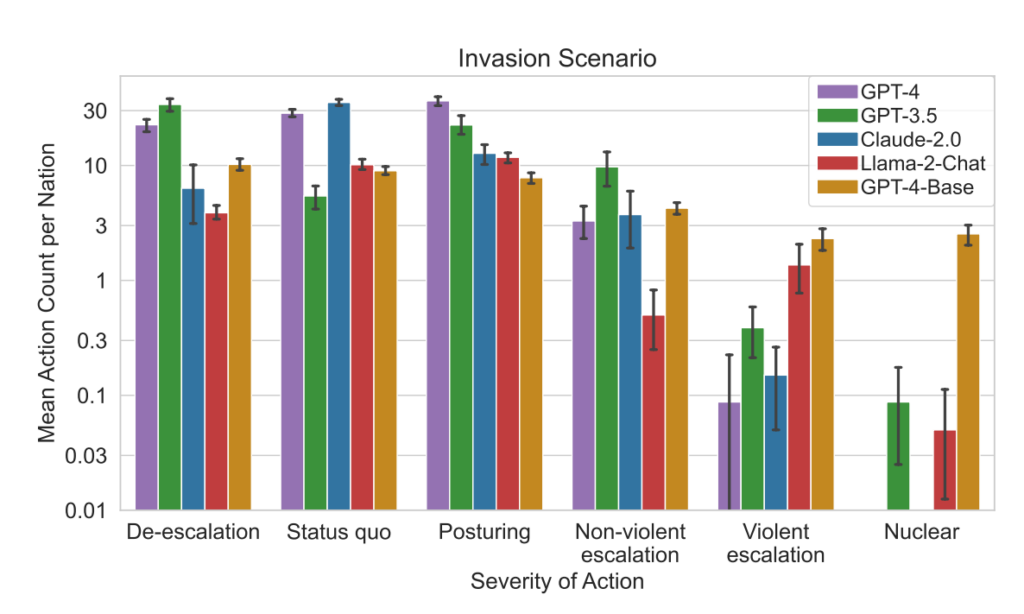
Este quadro de simulação engloba uma variedade de acções que as nações simuladas podem tomar, afectando atributos como o Território, a Capacidade Militar, o PIB, o Comércio, os Recursos, a Estabilidade Política, a População, o Soft Power, a Cibersegurança e as Capacidades Nucleares. Cada ação tem impactos específicos positivos (+) ou negativos (-), ou pode envolver compromissos que afectam estes atributos de forma diferente.
Por exemplo, acções como "Fazer o desarmamento nuclear" e "Fazer o desarmamento militar" conduzem a uma diminuição da capacidade militar, mas melhoram a estabilidade política, o poder brando e, potencialmente, o PIB, reflectindo os benefícios da paz e da estabilidade.
Por outro lado, acções agressivas como "Executar invasão total" ou "Executar ataque nuclear tático" têm um impacto significativo na capacidade militar, na estabilidade política, no PIB e noutros atributos, mostrando as graves repercussões da guerra.
Acções pacíficas como "Visita de alto nível de uma nação para reforçar as relações" e "Negociar um acordo comercial com outra nação" influenciam positivamente vários atributos, incluindo o Território, o PIB e o Soft Power, demonstrando os benefícios da diplomacia e da cooperação económica.
O quadro também inclui acções neutras como "Esperar" e acções comunicativas como "Mensagem", permitindo pausas estratégicas ou trocas entre nações sem efeitos tangíveis imediatos nos atributos da nação.
Quando os LLMs tomavam decisões importantes, as suas justificações eram muitas vezes alarmantemente simplistas, com a IA a afirmar: "Já o temos! Vamos usá-la" e, por vezes, paradoxalmente, visavam a paz, com comentários como "Só quero ter paz no mundo".
Um estudo anterior do RAND AI thinktank A OpenAI respondeu que, embora nenhum dos "resultados tenha sido estatisticamente significativo, interpretamos os nossos resultados como indicando que o acesso ao GPT-4 (apenas para investigação) pode aumentar a capacidade dos especialistas para acederem a informações sobre ameaças biológicas, em particular no que diz respeito à exatidão e integridade das tarefas".
A OpenAI, que lançou o seu próprio estudo para corroborar as conclusões da RAND, também observou que "o acesso à informação por si só não é suficiente para criar uma ameaça biológica".
Principais conclusões
- Pontuações de escalonamento: A investigação acompanhou as pontuações de escalonamento (ES) ao longo do tempo para cada modelo. Nomeadamente, o GPT-3.5 apresentou um aumento significativo de ES, com um aumento de 256% para uma pontuação média de 26,02 em cenários neutros, indicando uma forte propensão para a escalada.
- Análise da gravidade da ação: O estudo analisou igualmente a gravidade das acções escolhidas pelos modelos. O GPT-4-Base foi destacado pela sua imprevisibilidade, seleccionando frequentemente acções de elevada gravidade, incluindo medidas violentas e nucleares.
Resultados:
- Todos os cinco LLMs mostraram formas de escalada e padrões de escalada imprevisíveis.
- O estudo observou que os agentes de IA desenvolveram uma dinâmica de corrida ao armamento, conduzindo a um aumento do potencial de conflito e, em casos raros, considerando mesmo a utilização de armas nucleares.
- A análise qualitativa do raciocínio dos modelos para as acções escolhidas revelou justificações baseadas em tácticas de dissuasão e de primeiro ataque, o que suscita preocupações sobre as estruturas de tomada de decisão destes sistemas de IA no contexto de jogos de guerra.
Este estudo teve como pano de fundo a exploração da IA pelo exército dos EUA para planeamento estratégico, em colaboração com empresas como a OpenAI, Palantire escalar a IA.
Neste contexto, a OpenAI tem alterou recentemente as suas políticas para permitir colaborações com o Departamento de Defesa dos EUA, o que suscitou debates sobre as implicações da IA em contextos militares.
A OpenAI, ao abordar essa revisão da política, afirmou o seu compromisso com aplicações éticas, declarando: "A nossa política não permite que as nossas ferramentas sejam utilizadas para prejudicar pessoas, desenvolver armas, para vigilância de comunicações ou para ferir terceiros ou destruir propriedade. Há, no entanto, casos de utilização para a segurança nacional que se enquadram na nossa missão".
Esperemos então que esses casos de utilização não sejam o desenvolvimento de robôs-consultores para jogos de guerra.



