

Investigadores da Universidade da Califórnia em San Diego e da Universidade de Nova Iorque desenvolveram o V*, um algoritmo de pesquisa guiada por LLM que é muito melhor do que o GPT-4V na compreensão do contexto e na seleção precisa de elementos visuais específicos nas imagens.
Os modelos multimodais de linguagem ampla (MLLM), como o GPT-4V da OpenAI, surpreenderam-nos no ano passado com a sua capacidade de responder a perguntas sobre imagens. Por muito impressionante que o GPT-4V seja, por vezes tem dificuldades quando as imagens são muito complexas e, muitas vezes, deixa escapar pequenos pormenores.
O algoritmo V* utiliza um LLM de resposta a perguntas visuais (VQA) para o orientar na identificação da área da imagem em que se deve concentrar para responder a uma pergunta visual. Os investigadores chamam a esta combinação Show, sEArch, and telL (SEAL).
Se alguém lhe desse uma imagem de alta resolução e lhe fizesse uma pergunta sobre ela, a sua lógica guiá-lo-ia para fazer zoom numa área onde fosse mais provável encontrar o item em questão. O SEAL utiliza o V* para analisar imagens de uma forma semelhante.
Um modelo de pesquisa visual poderia simplesmente dividir uma imagem em blocos, fazer zoom em cada bloco e depois processá-la para encontrar o objeto em questão, mas isso é computacionalmente muito ineficiente.
Quando lhe é solicitada uma consulta textual sobre uma imagem, V* começa por tentar localizar diretamente o alvo da imagem. Se não o conseguir fazer, pede ao MLLM que utilize uma abordagem de senso comum para identificar a área da imagem onde é mais provável que o alvo se encontre.
Em seguida, concentra a sua pesquisa apenas nessa área, em vez de tentar uma pesquisa "ampliada" de toda a imagem.

Quando o GPT-4V é solicitado a responder a perguntas sobre uma imagem que requer um processamento visual extensivo de imagens de alta resolução, ele tem dificuldades. O SEAL com V* tem um desempenho muito melhor.

Quando lhe foi perguntado "Que tipo de bebida podemos comprar naquela máquina de venda automática?" o SEAL respondeu "Coca-Cola", enquanto o GPT-4V adivinhou incorretamente "Pepsi".
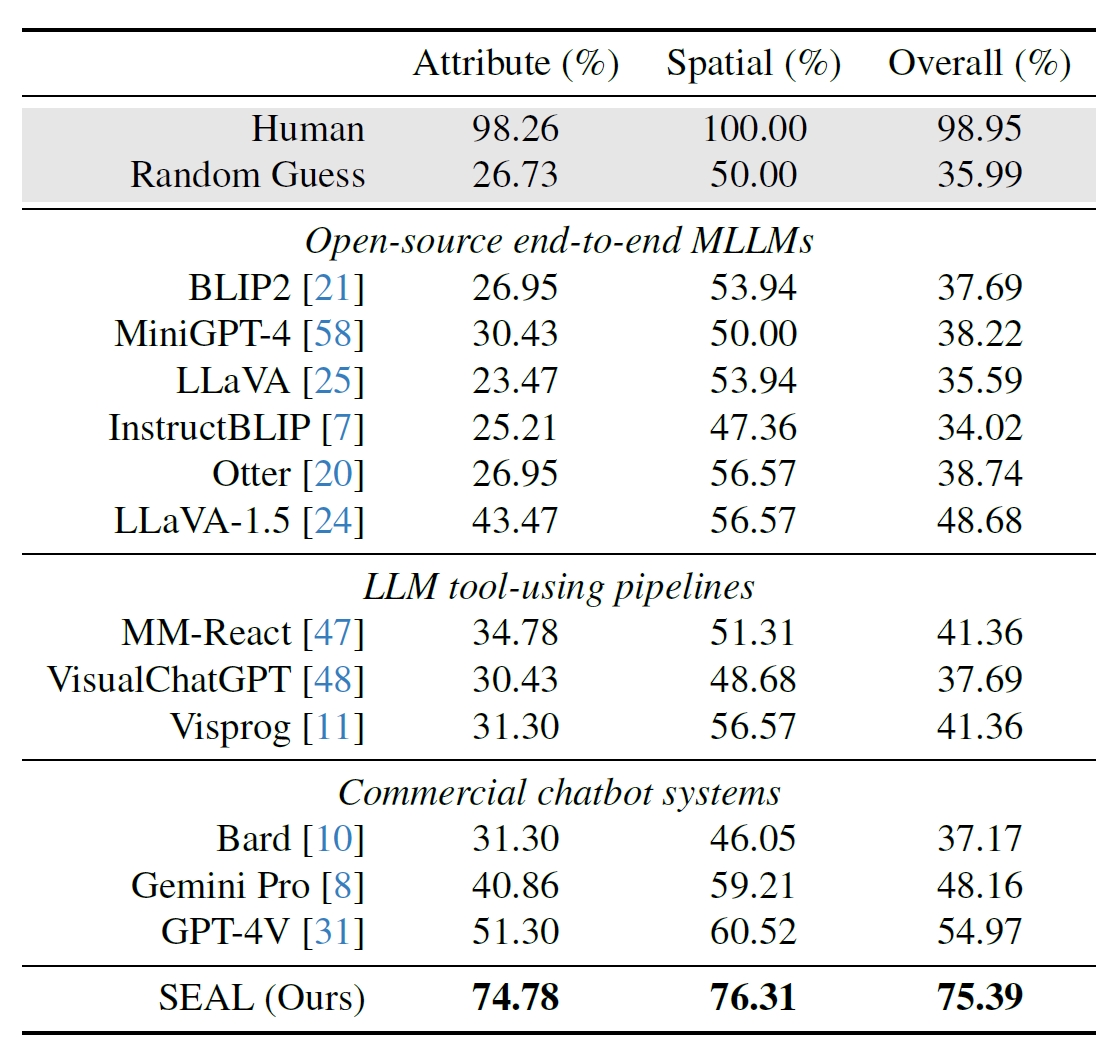
Os investigadores utilizaram 191 imagens de alta resolução do conjunto de dados Meta's Segment Anything (SAM) e criaram uma referência para ver como o desempenho do SEAL se comparava com o de outros modelos. O benchmark V*Bench testa duas tarefas: reconhecimento de atributos e raciocínio de relações espaciais.
As figuras abaixo mostram o desempenho humano em comparação com modelos de código aberto, modelos comerciais como o GPT-4V e o SEAL. O aumento que o V* dá no desempenho do SEAL é particularmente impressionante porque o MLLM subjacente que utiliza é o LLaVa-7b, que é muito mais pequeno do que o GPT-4V.
Esta abordagem intuitiva à análise de imagens parece funcionar muito bem com uma série de exemplos impressionantes no resumo do documento no GitHub.
Será interessante ver se outros MLLMs, como os da OpenAI ou da Google, adoptam uma abordagem semelhante.
Quando lhe perguntaram que bebida era vendida na máquina de venda automática da imagem acima, o Bard da Google respondeu: "Não há nenhuma máquina de venda automática em primeiro plano". Talvez o Gemini Ultra faça um trabalho melhor.
Para já, parece que o SEAL e o seu novo algoritmo V* estão muito à frente de alguns dos maiores modelos multimodais no que diz respeito ao questionamento visual.



