

Os actuais modelos de IA são capazes de fazer muitas coisas inseguras ou indesejáveis. A supervisão humana e o feedback mantêm estes modelos alinhados, mas o que acontecerá quando estes modelos se tornarem mais inteligentes do que nós?
A OpenAI afirma que é possível que nos próximos 10 anos possamos assistir à criação de uma IA mais inteligente do que os humanos. Juntamente com o aumento da inteligência, existe o risco de os humanos deixarem de ser capazes de supervisionar estes modelos.
A equipa de investigação Superalignment da OpenAI está concentrada na preparação para essa eventualidade. A equipa foi lançada em julho deste ano e é co-liderada por Ilya Sutskever, que tem estado na sombra desde a crise de Sam Altman despedimento e subsequente recontratação.
O raciocínio subjacente ao projeto foi colocado num contexto sóbrio pela OpenAI, que reconheceu que "atualmente, não temos uma solução para dirigir ou controlar uma IA potencialmente superinteligente e impedir que se torne desonesta".
Mas como é que nos preparamos para controlar algo que ainda não existe? A equipa de investigação acaba de lançar o seu primeiros resultados experimentais enquanto tenta fazer exatamente isso.
Generalização fraca para forte
Por enquanto, os humanos ainda estão numa posição de inteligência mais forte do que os modelos de IA. Os modelos como o GPT-4 são orientados ou alinhados utilizando o Feedback Humano de Aprendizagem por Reforço (RLHF). Quando o resultado de um modelo é indesejável, o formador humano diz ao modelo "Não faças isso" e recompensa o modelo com uma afirmação do desempenho desejado.
Por enquanto, isto funciona porque temos uma boa compreensão do funcionamento dos modelos actuais e somos mais inteligentes do que eles. Quando os futuros cientistas de dados humanos tiverem de treinar uma IA superinteligente, os papéis da inteligência inverter-se-ão.
Para simular esta situação, a OpenAI decidiu utilizar modelos GPT mais antigos, como o GPT-2, para treinar modelos mais potentes, como o GPT-4. O GPT-2 simularia o futuro treinador humano a tentar afinar um modelo mais inteligente.
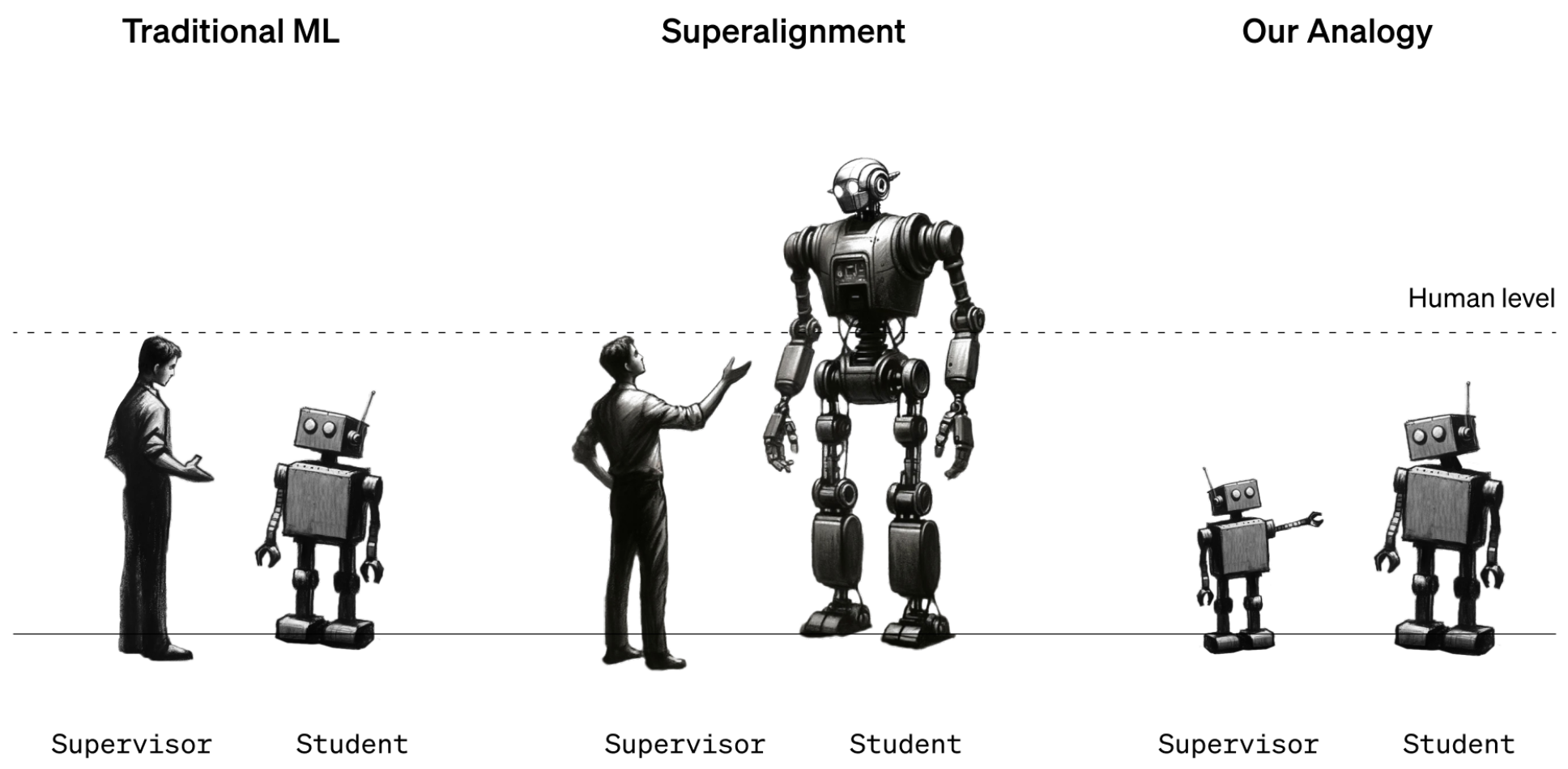
O documento de investigação explica que "tal como o problema dos humanos que supervisionam modelos sobre-humanos, a nossa configuração é uma instância daquilo a que chamamos o problema da aprendizagem fraca para forte".
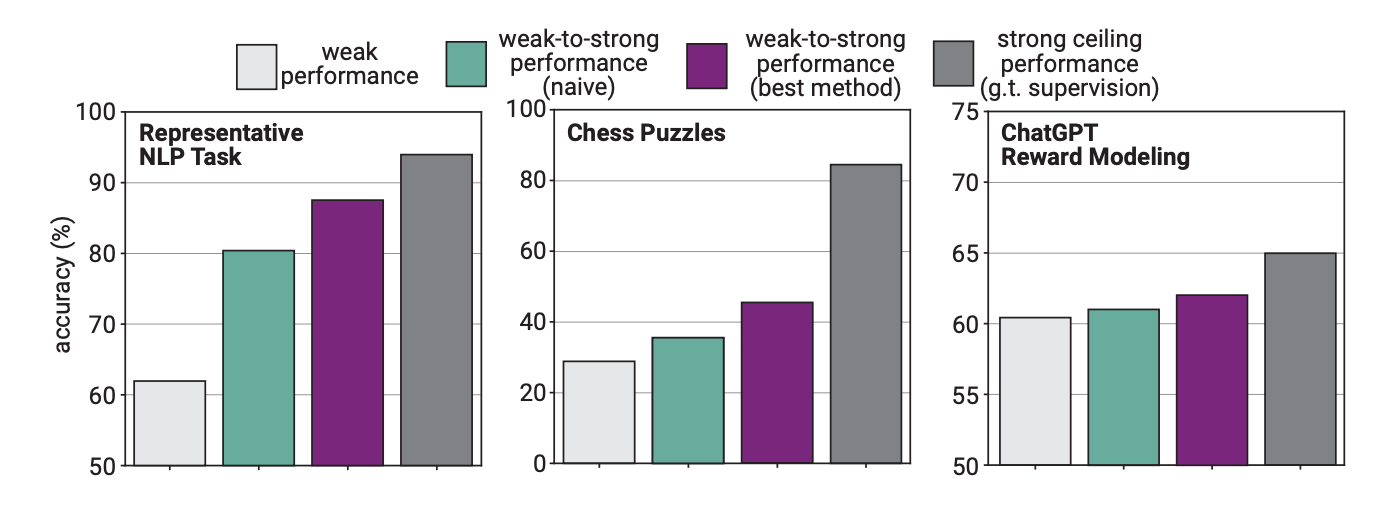
Na experiência, a OpenAI utilizou a GPT-2 para afinar a GPT-4 em tarefas de PNL, puzzles de xadrez e modelação de recompensas. Em seguida, testaram o desempenho do GPT-4 na execução destas tarefas e compararam-no com um modelo GPT-4 que tinha sido treinado com a "verdade básica" ou com as respostas correctas às tarefas.
Os resultados foram prometedores no sentido em que, quando a GPT-4 foi treinada pelo modelo mais fraco, foi capaz de generalizar fortemente e superar o modelo mais fraco. Isto demonstrou que uma inteligência mais fraca podia dar orientação a uma inteligência mais forte que podia depois basear-se nessa formação.
Pense nisto como se um aluno do 3º ano ensinasse matemática a um miúdo muito inteligente e depois o miúdo inteligente passasse a fazer matemática do 12º ano com base na formação inicial.
Diferença de desempenho
Os investigadores descobriram que, como o GPT-4 estava a ser treinado por um modelo menos inteligente, esse processo limitava o seu desempenho ao equivalente a um modelo GPT-3.5 devidamente treinado.
Isto deve-se ao facto de o modelo mais inteligente aprender alguns dos erros ou processos de pensamento deficientes do seu supervisor mais fraco. Isto parece indicar que a utilização de seres humanos para treinar uma IA superinteligente impediria a IA de atingir o seu potencial máximo.
Os investigadores sugeriram a utilização de modelos intermédios numa abordagem de bootstrapping. O documento explica que "em vez de alinhar diretamente modelos muito sobre-humanos, poderíamos primeiro alinhar um modelo apenas ligeiramente sobre-humano, usá-lo para alinhar um modelo ainda mais inteligente, e assim por diante".
A OpenAI está a afetar muitos recursos a este projeto. A equipa de investigação diz que dedicou "20% da computação que assegurámos até à data nos próximos quatro anos para resolver o problema do alinhamento da superinteligência".
Está também a oferecer $10 milhões em subsídios a indivíduos ou organizações que queiram ajudar na investigação.
É bom que descubram isto rapidamente. Uma IA superinteligente poderia potencialmente escrever um milhão de linhas de código complicado que nenhum programador humano poderia compreender. Como é que saberíamos se o código gerado era seguro ou não para ser executado? Esperemos que não o descubramos da maneira mais difícil.



