

Os modelos de linguagem de grande dimensão (LLM) são muitas vezes induzidos em erro por preconceitos ou contextos irrelevantes numa mensagem. Os investigadores da Meta descobriram uma forma aparentemente simples de resolver este problema.
À medida que as janelas de contexto aumentam, as instruções que introduzimos num LLM podem tornar-se mais longas e cada vez mais detalhadas. Os LLMs tornaram-se mais aptos a captar as nuances ou os pequenos detalhes das nossas instruções, mas por vezes isso pode confundi-los.
A aprendizagem automática inicial utilizava uma abordagem de "atenção rigorosa" que seleccionava a parte mais relevante de uma entrada e respondia apenas a essa parte. Isto funciona bem quando se está a tentar legendar uma imagem, mas mal quando se está a traduzir uma frase ou a responder a uma pergunta com várias camadas.
Atualmente, a maioria dos LLM utiliza uma abordagem de "atenção suave", que simboliza toda a mensagem e atribui pesos a cada uma delas.
Meta propõe uma abordagem denominada Sistema 2 Atenção (S2A) para obter o melhor dos dois mundos. O S2A utiliza a capacidade de processamento de linguagem natural de um LLM para receber o seu pedido e eliminar preconceitos e informações irrelevantes antes de começar a trabalhar numa resposta.
Eis um exemplo.

O S2A elimina a informação relativa ao Max, uma vez que é irrelevante para a pergunta. S2A regenera um prompt optimizado antes de começar a trabalhar nele. Os LLMs são notoriamente maus em matemática por isso, tornar o prompt menos confuso é uma grande ajuda.
Os LLMs agradam às pessoas e têm todo o gosto em concordar consigo, mesmo quando está errado. O S2A elimina qualquer preconceito numa mensagem e depois processa apenas as partes relevantes da mensagem. Isto reduz aquilo a que os investigadores de IA chamam "bajulação", ou seja, a propensão de um modelo de IA para dar graxa.

O S2A é, na verdade, apenas um prompt do sistema que instrui o LLM a refinar um pouco o prompt original antes de começar a trabalhar nele. Os resultados obtidos pelos investigadores com questões de matemática, factuais e longas foram impressionantes.
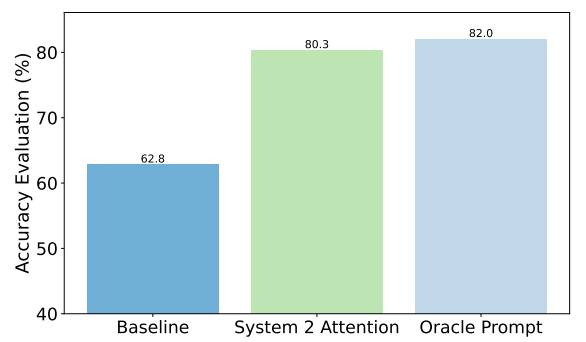
Como exemplo, eis as melhorias que o S2A obteve em questões factuais. A linha de base era constituída por respostas a perguntas que continham preconceitos, enquanto que a pergunta Oracle era uma pergunta ideal refinada por humanos.
O S2A aproxima-se muito dos resultados do prompt Oracle e proporciona uma melhoria de quase 50% na precisão em relação ao prompt de base.
Então, qual é o problema? O pré-processamento do pedido original antes de responder acrescenta requisitos de computação adicionais ao processo. Se o pedido for longo e tiver muitas informações relevantes, a regeneração do pedido pode acrescentar custos significativos.
É pouco provável que os utilizadores melhorem a sua capacidade de escrever prompts bem elaborados, pelo que o S2A pode ser uma boa forma de contornar esse problema.
A Meta vai integrar o S2A na sua Lhama modelo? Não sabemos, mas pode aproveitar a abordagem S2A.
Se tiver o cuidado de omitir opiniões ou sugestões de liderança nos seus avisos, é mais provável que obtenha respostas exactas destes modelos.



