

Os investigadores introduziram o FANToM, um novo parâmetro de referência concebido para testar e avaliar rigorosamente a compreensão e a aplicação da Teoria da Mente (ToM) pelos modelos de linguagem de grande dimensão (LLM).
A teoria da mente refere-se à capacidade de atribuir crenças, desejos e conhecimentos a si próprio e aos outros, e de compreender que os outros têm crenças e perspectivas diferentes das suas.
A ToM é vista como fundamental para a consciência dos animais inteligentes. Para além dos humanos, considera-se que primatas como os orangotangos, os gorilas e os chimpanzés têm ToM, bem como alguns animais não primatas, como os papagaios e os membros da família dos corvos.
À medida que os modelos de IA se tornam mais complexos, os investigadores de IA procuram novos métodos de avaliação de capacidades como a ToM.
Um novo marco de referência chamado FANToMcriado por investigadores do Allen Institute for AI, da Universidade de Washington, da Universidade Carnegie Mellon e da Universidade Nacional de Seul, submete os modelos de aprendizagem automática a cenários dinâmicos que reflectem as interacções da vida real.
Com o FANToM, as personagens entram e saem de conversas, desafiando os modelos de IA a manter uma compreensão exacta de quem sabe o quê num dado momento.
A submissão de grandes modelos linguísticos (LLMs) ao FANToM revelou que mesmo os modelos mais avançados têm dificuldade em manter uma ToM consistente.
O desempenho dos modelos foi significativamente inferior ao dos participantes humanos, salientando as limitações da IA na compreensão e navegação em interacções sociais complexas.
De facto, os humanos dominaram todas as categorias, como se pode ver abaixo.
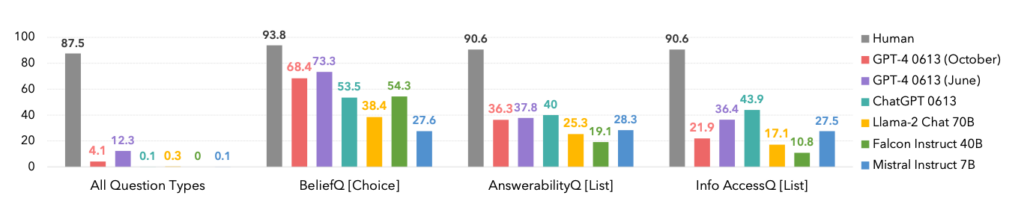
Um aspeto interessante é o facto de a versão de outubro da iteração do modelo GPT-4 ter sido ultrapassada por uma versão anterior de junho, o que poderá confirmar as recentes histórias de utilizadores que afirmam que ChatGPT está a piorar.
O FANToM também revelou técnicas para melhorar a ToM da LLM, como o raciocínio em cadeia e outros métodos de afinação.
No entanto, o fosso entre as competências de ToM da IA e dos humanos continua a ser elevado.
A IA aproxima-se de competências linguísticas semelhantes às humanas
Num caso um pouco relacionado mas distinto estudo publicado na Nature, os cientistas desenvolveram uma rede neuronal capaz de generalizar uma linguagem semelhante à humana.
Esta nova rede neuronal demonstrou uma capacidade impressionante de integrar palavras recentemente aprendidas no seu vocabulário existente. Podia então utilizar essas palavras em vários contextos, uma capacidade cognitiva conhecida como generalização sistemática.
Os seres humanos exibem naturalmente uma generalização sistemática, incorporando sem problemas novo vocabulário no seu repertório.
Por exemplo, quando alguém aprende o termo "photobomb", pode aplicá-lo em várias situações quase imediatamente. Estão sempre a surgir novas gírias e os seres humanos absorvem-nas naturalmente no seu vocabulário.
Os investigadores submeteram a sua própria rede neural personalizada e o ChatGPT a uma série de testes, descobrindo que o ChatGPT ficou atrás do modelo personalizado em termos de desempenho.
Embora os LLMs como o ChatGPT sejam excelentes em muitos cenários de conversação, apresentam inconsistências e lacunas visíveis noutros, um problema que esta nova rede neural resolve.
Para investigar este aspeto da comunicação linguística, os investigadores realizaram uma experiência com 25 participantes humanos, avaliando a sua capacidade de aplicar palavras recentemente aprendidas em diferentes contextos. Os sujeitos foram apresentados a uma pseudo-linguagem constituída por palavras sem sentido que representam várias acções e regras.
Após uma fase de treino, os participantes destacaram-se na aplicação destas regras abstractas a novas situações, demonstrando uma generalização sistemática.
Quando a rede neural recentemente desenvolvida foi exposta a esta tarefa, reflectiu o desempenho humano. No entanto, quando o ChatGPT foi sujeito ao mesmo desafio, teve dificuldades significativas, falhando entre 42 e 86% do tempo, dependendo da tarefa específica.
Este facto é significativo por duas razões. Em primeiro lugar, pode dizer-se que esta nova rede neuronal superou efetivamente o GPT-4 nesta tarefa específica - o que já é suficientemente impressionante. Em segundo lugar, este estudo expõe novos métodos para ensinar modelos de IA a generalizar uma nova linguagem como os humanos.
Como Elia Bruni, especialista em processamento de linguagem natural na Universidade de Osnabrück, na Alemanha, descreve, "Infundir sistematicidade nas redes neuronais é um grande negócio".
Em conjunto, estes dois estudos oferecem novas abordagens para o treino de modelos de IA mais inteligentes, capazes de rivalizar com os humanos em áreas críticas como a linguística e a Teoria da Mente.



