

Terwijl het tijdperk van generatieve AI voortschrijdt, heeft een breed scala aan bedrijven zich aangesloten bij de strijd en zijn de modellen zelf steeds diverser geworden.
Te midden van deze AI-boom hebben veel bedrijven hun modellen aangeprezen als 'open source', maar wat betekent dit nu echt in de praktijk?
Het concept van open source vindt zijn oorsprong in de softwareontwikkelingsgemeenschap. Traditionele open source software maakt de broncode vrij beschikbaar voor iedereen om te bekijken, aan te passen en te verspreiden.
In essentie is open-source een samenwerkingsinstrument voor het delen van kennis dat wordt gevoed door software-innovatie, wat heeft geleid tot ontwikkelingen zoals het besturingssysteem Linux, de webbrowser Firefox en de programmeertaal Python.
Het is echter verre van eenvoudig om het open-source ethos toe te passen op de enorme AI-modellen van vandaag.
Deze systemen worden vaak getraind op enorme datasets met terabytes of petabytes aan gegevens, waarbij gebruik wordt gemaakt van complexe neurale netwerkarchitecturen met miljarden parameters.
De benodigde computermiddelen kosten miljoenen dollars, het talent is schaars en intellectueel eigendom wordt vaak goed beschermd.
We kunnen dit zien bij OpenAI, dat, zoals de naam al doet vermoeden, vroeger een AI-onderzoekslaboratorium was dat zich grotendeels richtte op het ethos van open onderzoek.
Maar dat ethos snel uitgehold zodra het bedrijf het geld rook en investeringen moest aantrekken om zijn doelen te verwezenlijken.
Waarom? Omdat open-source producten niet gericht zijn op winst en AI duur en waardevol is.
Maar nu generatieve AI explosief is gegroeid, geven bedrijven als Mistral, Meta, BLOOM en xAI open-source modellen vrij om het onderzoek te bevorderen en tegelijkertijd te voorkomen dat bedrijven als Microsoft en Google te veel invloed opeisen.
Maar hoeveel van deze modellen zijn echt open-source van aard, en niet alleen bij naam?
Verduidelijken hoe open open-source modellen echt zijn
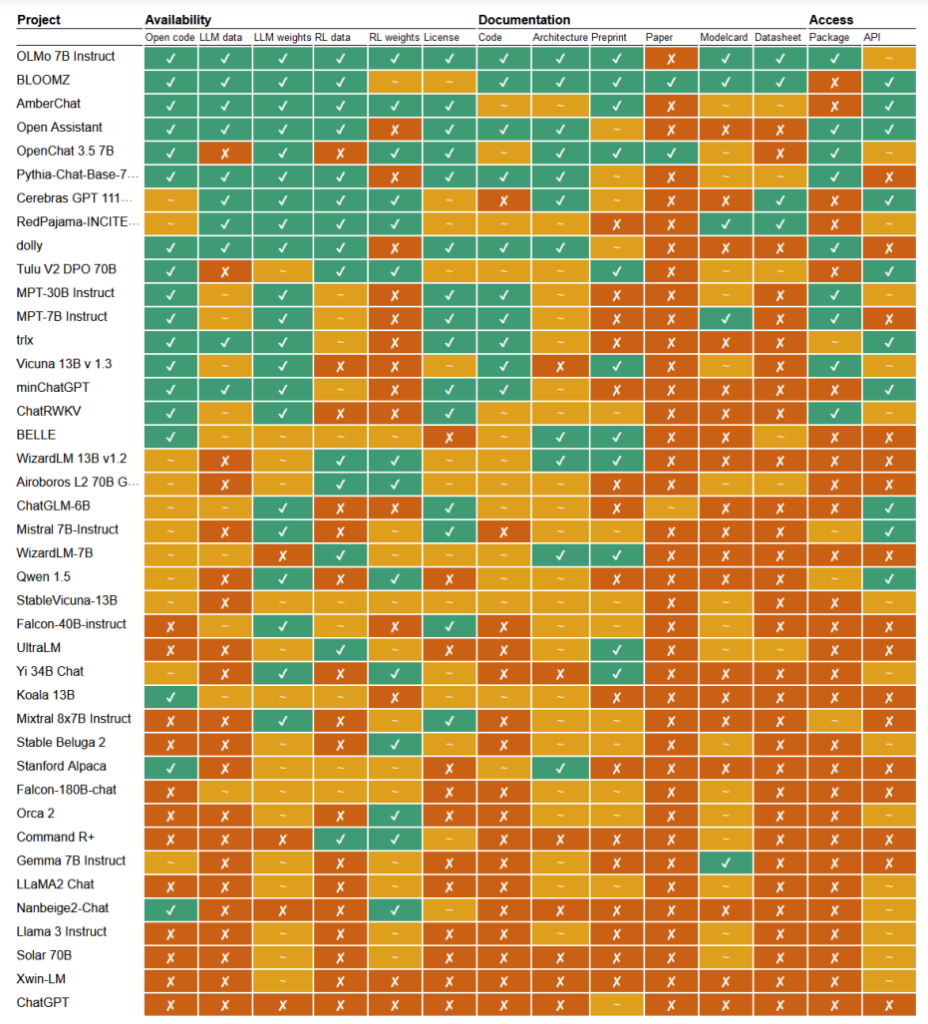
In een recente onderzoekOnderzoekers Mark Dingemanse en Andreas Liesenfeld van de Radboud Universiteit in Nederland analyseerden tal van prominente AI-modellen om te onderzoeken hoe open ze zijn. Ze bestudeerden meerdere criteria, zoals de beschikbaarheid van broncode, trainingsgegevens, modelgewichten, onderzoekspapers en API's.
Het LLaMA-model van Meta en Gemma van Google bleken bijvoorbeeld eenvoudigweg "open gewicht" te hebben, wat betekent dat het getrainde model openbaar wordt vrijgegeven voor gebruik zonder volledige transparantie over de code, het trainingsproces, de gegevens en de fijnafstemmingsmethoden.
Aan de andere kant van het spectrum benadrukten de onderzoekers BLOOM, een groot meertalig model dat is ontwikkeld door een samenwerking van meer dan 1000 onderzoekers wereldwijd, als een voorbeeld van echte open-source AI. Elk element van het model is vrij toegankelijk voor inspectie en verder onderzoek.
Het artikel beoordeelde zo'n 30+ modellen (zowel tekst als afbeeldingen), maar deze laten de immense variatie zien binnen de modellen die beweren open-source te zijn:
- BloomZ (BigScience): Volledig open voor alle criteria, inclusief code, trainingsgegevens, modelgewichten, onderzoekspapers en API. Uitgelicht als een voorbeeld van echt open-source AI.
- OLMo (Allen Instituut voor AI): Open code, trainingsgegevens, gewichten en onderzoekspapers. API slechts gedeeltelijk open.
- Mistral 7B-Instruct (Mistral AI): Open modelgewichten en API. Code en onderzoekspapers slechts gedeeltelijk open. Trainingsgegevens niet beschikbaar.
- Orca 2 (Microsoft): Gedeeltelijk open modelgewichten en onderzoekspapers. Code, trainingsgegevens en API gesloten.
- Gemma 7B instructie (Google): Gedeeltelijk open code en gewichten. Trainingsgegevens, onderzoekspapers en API gesloten. Door Google omschreven als "open" in plaats van "open source".
- Llama 3 Instruct (Meta): Gedeeltelijk open gewichten. Code, trainingsgegevens, onderzoekspapers en API gesloten. Een voorbeeld van een "open gewicht" model zonder meer transparantie.
Gebrek aan transparantie
Het gebrek aan transparantie rond AI-modellen, vooral modellen die zijn ontwikkeld door grote techbedrijven, leidt tot ernstige zorgen over verantwoording en toezicht.
Zonder volledige toegang tot de code van het model, de trainingsgegevens en andere belangrijke onderdelen, wordt het extreem moeilijk om te begrijpen hoe deze modellen werken en beslissingen nemen. Dit maakt het moeilijk om mogelijke vertekeningen, fouten of misbruik van auteursrechtelijk beschermd materiaal te identificeren en aan te pakken.
Schending van auteursrecht in AI-trainingsgegevens is een goed voorbeeld van de problemen die voortkomen uit dit gebrek aan transparantie. Veel gepatenteerde AI-modellen, zoals GPT-3.5/4/40/Claude 3/Gemini, zijn waarschijnlijk getraind op auteursrechtelijk beschermd materiaal.
Maar omdat trainingsgegevens achter slot en grendel worden bewaard, is het bijna onmogelijk om specifieke gegevens in dit materiaal te identificeren.
De New York Times recente rechtszaak tegen OpenAI toont de gevolgen van deze uitdaging in de echte wereld. OpenAI beschuldigde de NYT van het gebruik van prompt engineering-aanvallen om trainingsgegevens bloot te leggen en ChatGPT te verleiden zijn artikelen woordelijk te reproduceren en zo te bewijzen dat OpenAI's trainingsgegevens auteursrechtelijk beschermd materiaal bevatten.
"The Times betaalde iemand om de producten van OpenAI te hacken," verklaarde OpenAI.
In een reactie zei Ian Crosby, de juridisch adviseur van de NYT: "Wat OpenAI op bizarre wijze omschrijft als 'hacken' is simpelweg het gebruik van OpenAI's producten om te zoeken naar bewijs dat ze de auteursrechtelijk beschermde werken van The Times hebben gestolen en gereproduceerd. En dat is precies wat we hebben gevonden."
Sterker nog, dat is slechts één voorbeeld uit een enorme stapel rechtszaken die momenteel geblokkeerd worden, deels vanwege de ondoorzichtige, ondoordringbare aard van AI-modellen.
Dit is nog maar het topje van de ijsberg. Zonder robuuste transparantie en verantwoordingsmaatregelen riskeren we een toekomst waarin onverklaarbare AI-systemen beslissingen nemen die een grote impact hebben op ons leven, onze economie en onze samenleving, maar die niet worden gecontroleerd.
Oproepen tot openheid
Er zijn oproepen geweest voor bedrijven als Google en OpenAI om toegang verlenen tot het binnenwerk van hun modellen voor de veiligheidsevaluatie.
De waarheid is echter dat zelfs AI-bedrijven niet echt begrijpen hoe hun modellen werken.
Dit wordt het "black box" probleem genoemd, dat optreedt wanneer geprobeerd wordt om de specifieke beslissingen van het model op een voor mensen begrijpelijke manier te interpreteren en te verklaren.
Een ontwikkelaar kan bijvoorbeeld weten dat een deep learning-model nauwkeurig is en goed presteert, maar hij kan moeite hebben om precies vast te stellen welke kenmerken het model gebruikt om zijn beslissingen te nemen.
Anthropic, dat de Claude-modellen ontwikkelde, heeft onlangs voerde een experiment uit om te achterhalen hoe Claude 3 Sonnet werkt, en legt uit: "We behandelen AI-modellen meestal als een zwarte doos: er gaat iets in en er komt een antwoord uit, en het is niet duidelijk waarom het model dat specifieke antwoord gaf in plaats van een ander. Dit maakt het moeilijk om erop te vertrouwen dat deze modellen veilig zijn: als we niet weten hoe ze werken, hoe weten we dan dat ze geen schadelijke, bevooroordeelde, leugenachtige of anderszins gevaarlijke antwoorden geven? Hoe kunnen we erop vertrouwen dat ze veilig en betrouwbaar zijn?"
Het is eigenlijk een opmerkelijke bekentenis dat de maker van een technologie zijn product in het AI-tijdperk niet begrijpt.
Dit Antropische experiment illustreerde dat het objectief verklaren van uitgangen een buitengewoon lastige taak is. Anthropic schatte zelfs dat het meer rekenkracht zou kosten om de 'zwarte doos' te openen dan om het model zelf te trainen!
Ontwikkelaars proberen het black-box probleem actief te bestrijden door onderzoek zoals "Explainable AI" (XAI), dat zich richt op het ontwikkelen van technieken en gereedschappen om AI-modellen transparanter en beter interpreteerbaar te maken.
XAI-methoden proberen inzicht te verschaffen in het besluitvormingsproces van het model, de meest invloedrijke kenmerken te benadrukken en menselijk leesbare verklaringen te genereren. XAI is al toegepast op modellen die worden gebruikt in modellen waarbij veel op het spel staat. toepassingen zoals geneesmiddelenontwikkelingwaarbij inzicht in de werking van een model cruciaal kan zijn voor de veiligheid.
Open-source initiatieven zijn van vitaal belang voor XAI en ander onderzoek dat probeert door te dringen tot de zwarte doos en transparantie te bieden in AI-modellen.
Zonder toegang tot de code van het model, de trainingsgegevens en andere belangrijke onderdelen kunnen onderzoekers geen technieken ontwikkelen en testen om uit te leggen hoe AI-systemen echt werken en specifieke gegevens identificeren waarop ze zijn getraind.
Regelgeving kan de open source-situatie verder in de war sturen
De Europese Unie onlangs aangenomen AI-wet staat op het punt om nieuwe regels voor AI-systemen in te voeren, met bepalingen die specifiek betrekking hebben op open source-modellen.
Onder de Wet worden open source modellen voor algemene doeleinden tot een bepaalde grootte vrijgesteld van uitgebreide transparantievereisten.
Maar zoals Dingemanse en Liesenfeld in hun onderzoek aangeven, is de exacte definitie van "open source AI" onder de AI-wet nog onduidelijk en kan dit een twistpunt worden.
De wet definieert open source modellen momenteel als modellen die worden vrijgegeven onder een "vrije en open" licentie die gebruikers toestaat het model te wijzigen. Er worden echter geen eisen gesteld aan de toegang tot trainingsgegevens of andere belangrijke componenten.
Deze dubbelzinnigheid laat ruimte voor interpretatie en mogelijk lobbyen door bedrijfsbelangen. De onderzoekers waarschuwen dat het verfijnen van de definitie van open source in de AI-wet "waarschijnlijk een enkel drukpunt zal vormen waar bedrijfslobby's en grote bedrijven zich op zullen richten."
Het risico bestaat dat zonder duidelijke, robuuste criteria voor wat echt open-source AI is, de regelgeving onbedoeld mazen in de wet creëert of bedrijven stimuleert om aan "open-washing" te doen - openheid claimen vanwege de juridische en PR-voordelen, terwijl belangrijke aspecten van hun modellen nog steeds gepatenteerd blijven.
Bovendien betekent het wereldwijde karakter van AI-ontwikkeling dat verschillende regelgevingen in verschillende rechtsgebieden het landschap nog ingewikkelder kunnen maken.
Als grote AI-producenten zoals de Verenigde Staten en China verschillende benaderingen hanteren ten aanzien van openheid en transparantie-eisen, kan dit leiden tot een gefragmenteerd ecosysteem waarin de mate van openheid sterk varieert afhankelijk van waar een model vandaan komt.
De auteurs van het onderzoek benadrukken de noodzaak voor regelgevers om nauw samen te werken met de wetenschappelijke gemeenschap en andere belanghebbenden om ervoor te zorgen dat alle open source-bepalingen in AI-wetgeving gebaseerd zijn op een grondig begrip van de technologie en de principes van openheid.
Zoals Dingemanse en Liesenfeld concluderen in een discussie met de natuurHet is eerlijk om te zeggen dat de term open source een ongekend juridisch gewicht krijgt in de landen die vallen onder de AI-wet van de EU."
Hoe dit in de praktijk uitpakt, zal grote gevolgen hebben voor de toekomstige richting van AI-onderzoek en -implementatie.



